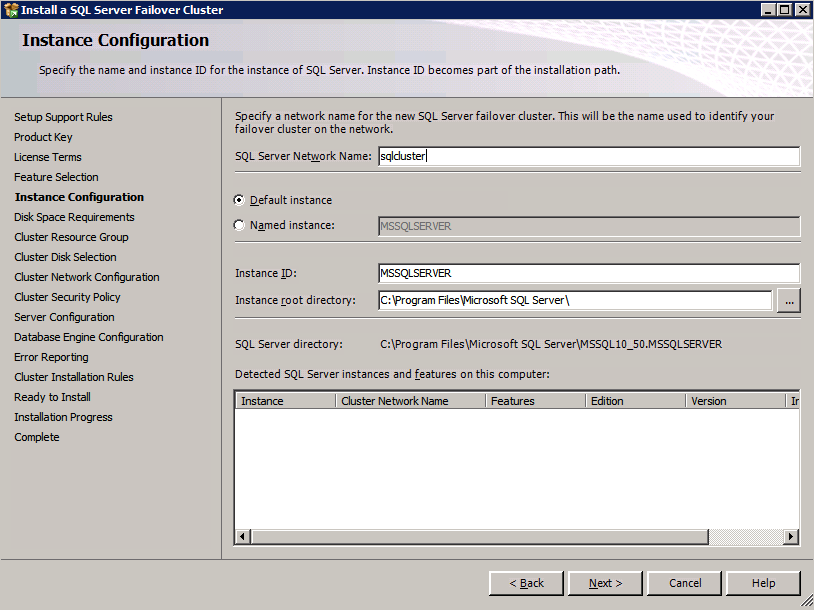
在Azure中运行SQL Server的存储注意事项
在Azure或任何云平台中部署SQL Server?考虑到Azure中的存储与您可能访问本地的存储不完全相同,而不是像您为内部部署多年来那样配置存储。一些传统的“最佳实践”可能会花费你额外的钱,并给你不到最佳的性能。然而,一直没有为您提供任何预期的好处。我将要讨论的大部分内容也在SQL Server虚拟机中的Azure性能指南中进行了描述。
磁盘类型
我不是要告诉您必须使用UltraSSD,Premium Storage或任何其他磁盘类型。您只需要知道您有选项,以及每种磁盘类型为表带来的内容。当然,就像云中的其他任何东西一样,您花费的钱越多,您将获得的功率,速度,吞吐量等就越多。诀窍是找到适合您存储考虑因素的最佳配置,这样您就可以花费足够的时间来达到预期的效果。
尺寸很重要
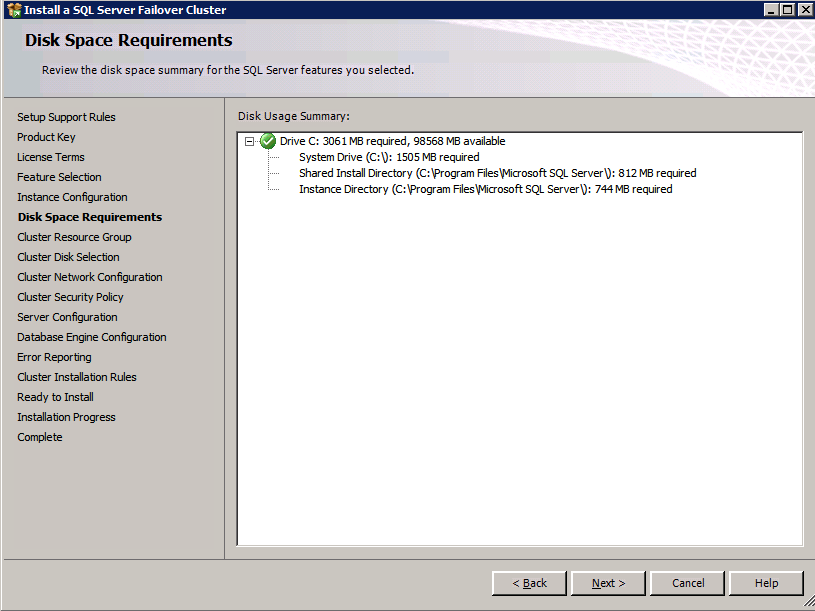
像云中的许多东西一样,某些规格是捆绑在一起的。对于服务器,如果你想要更多的RAM,你经常会获得更多的CPU,即使你不需要更多的CPU。对于存储,IOPS,吞吐量和大小都捆绑在一起。如果您想要更多IOPS,则需要更大的磁盘。如果您需要更多空间,您还可以获得更多IOPS。当然,您可以在存储类之间跳转以在某种程度上规避这一点,但是如果您需要更多IOPS,您仍然可以在任何不同的存储类型上获得更多空间。虚拟机实例的大小也很重要。无论您最终使用哪种存储配置,总体吞吐量都将限制在实例大小允许的范围内。因此,再次,您可能需要支付比您需要的更多的RAM和CPU,只是为了实现您期望的存储性能。确保您了解实例大小可以支持的最大IOPS和MBps吞吐量。很多时候,实例大小将成为Azure中感知存储性能问题的瓶颈。
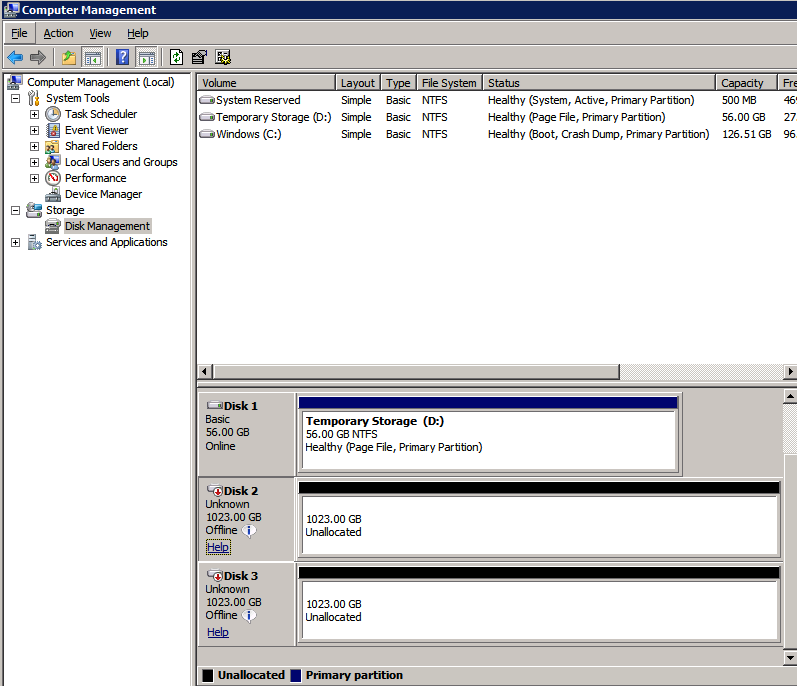
使用Raid 0
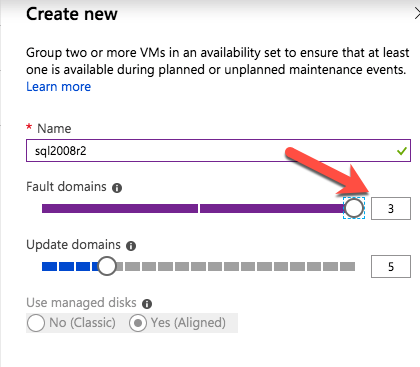
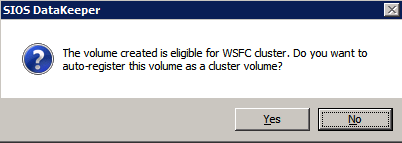
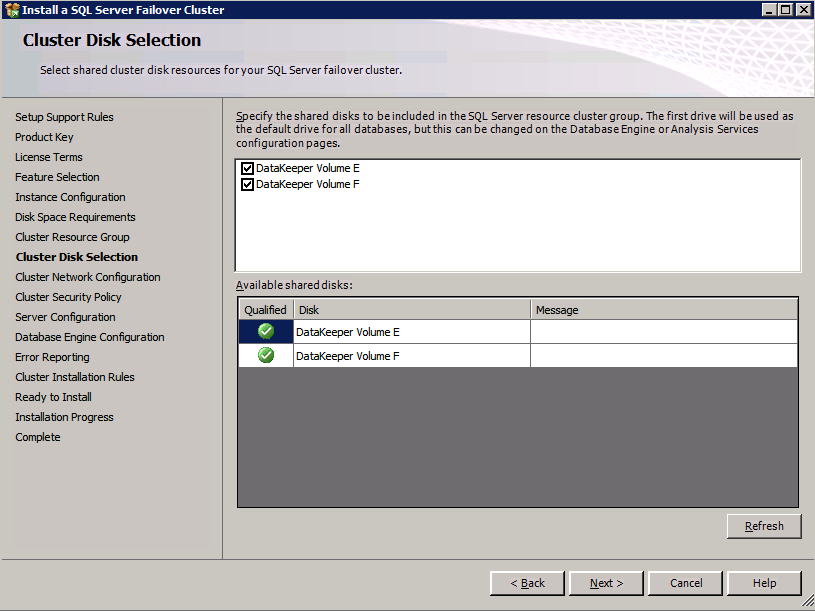
RAID 0传统上是存储配置选项的第三轨。虽然它提供了任何RAID选项的性能和存储利用率的最佳组合,但它存在灾难性故障的风险。当RAID 0条带集中的单个磁盘发生故障时,整个条带集将失败。因此,传统上RAID 0仅用于数据丢失可接受且需要高性能的情况。但是,在Azure软件中,RAID 0是可取的,甚至在许多情况下也是推荐的。我们如何在Azure中使用RAID 0?答案很简单。您呈现给Azure虚拟机实例的每个磁盘已在后端具有三重冗余。这意味着在丢失条带集之前需要多次失败。通过使用RAID 0,您可以组合多个磁盘。对于添加到条带集的每个附加磁盘,组合条带集的整体性能将增加100%。因此,例如,您需要10,000 IOPS,您可能认为您需要UltraSSD,因为高级存储使用P50最高可达7,500 IOPS。但是,通过将两个P50放入RAID 0,您现在可以实现高达15,000 IOPS。假设您正在运行Standard_F16s_v2或类似的大型实例大小,支持那么多IOPS。在Windows 2012及更高版本中,RAID 0是通过创建简单存储空间来实现的。在Windows Server 2008 R2中,您可以使用动态磁盘创建RAID 0条带卷。只是提醒一句。如果您要使用本地存储空间并使用DataKeeper配置可用性组或SANless故障转移群集实例,则最好在创建群集之前配置存储。 只是提醒。您只有两个月的时间将SQL Server 2008 R2实例移动到Azure。查看我的帖子,了解如何在Azure上部署SQL Server 2008 R2 FCI以确保高可用性。
不要打扰分离日志和数据文件
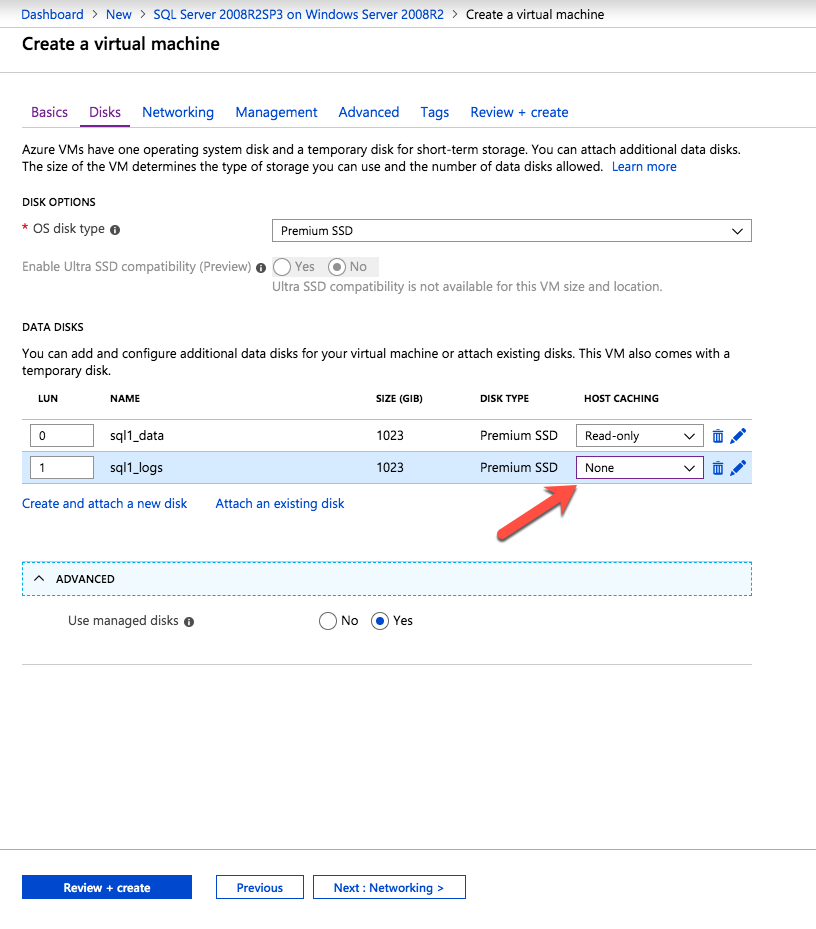
传统上,日志和数据文件将驻留在不同的物理磁盘上。日志文件往往具有大量写入活动,而数据文件往往具有更多读取活动。因此,有时存储将基于这些特征进行优化。还希望将日志和数据文件保存在不同的磁盘上以用于恢复目的。如果您丢失了一个或另一个,并且有适当的备份策略,您可以恢复数据库而不会丢失数据。使用基于云的存储,只丢失一个卷的可能性非常低。现在您正考虑存储注意事项。如果您偶然丢失了存储空间,则可能是您的整个存储群集以及三重冗余都要去吃午餐。因此,虽然将日志放入E: logs和F: data中的数据可能是正确的,但您确实在做自己的损害。例如,您为日志配置了P20,为数据配置了P20。每个卷的大小为512 GiB,上限为2,300 IOPS。试想一下,你可能不需要那么大的日志文件。但它可能不会为您的数据文件增长留出太多空间。它最终需要转移到更昂贵的P30,只是为了额外的空间。简单地将这两个卷组合成一个支持4,600 IOPS的漂亮的大1 TB卷不是更好吗?通过这样做,日志和数据文件都可以利用增加的IOPS。而且,您还可以通过推迟数据文件的P30磁盘来优化存储利用率并降低云存储成本。这同样适用于真正的文件和文件组。真的很想你在做什么。一旦你搬到云端,它是否仍然有意义。 有意义的事情可能与你过去所做的事情相违背。如有疑问,请遵循KISS规则,Keep It Simple Stupid!云的美妙之处在于您可以随时添加更多存储空间,增加实例大小,或者尽一切可能优化性能与成本。
如何处理TempDB
使用本地SSD,也称为D:驱动器。D驱动器将成为tempdb的最佳位置。 因为它是本地驱动器,所以数据被认为是“临时的”。这意味着如果移动,重新启动服务器等,它可能会丢失。没关系。每次SQL启动时都会重新创建Tempdb。本地SSD将很快并且具有低延迟。但是因为它是本地的,所以对它的读取和写入不会影响实例大小的总体存储IOPS限制。所以有效它是免费的IOPS!为什么不利用?如果要使用SIOS DataKeeper构建SANless SQL Server FCI,请确保创建D驱动器的非镜像卷资源。这样您就不必不必要地复制TempDB。
装载点变得过时
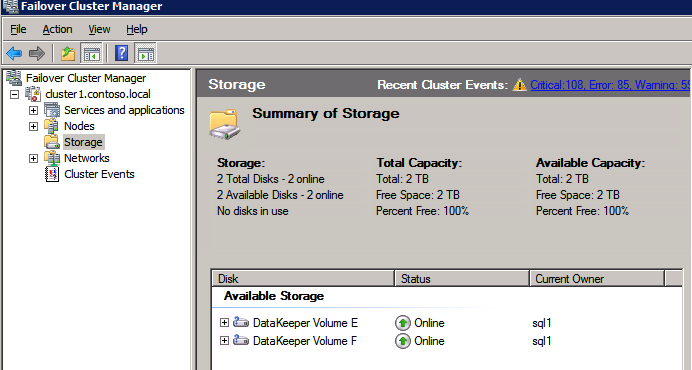
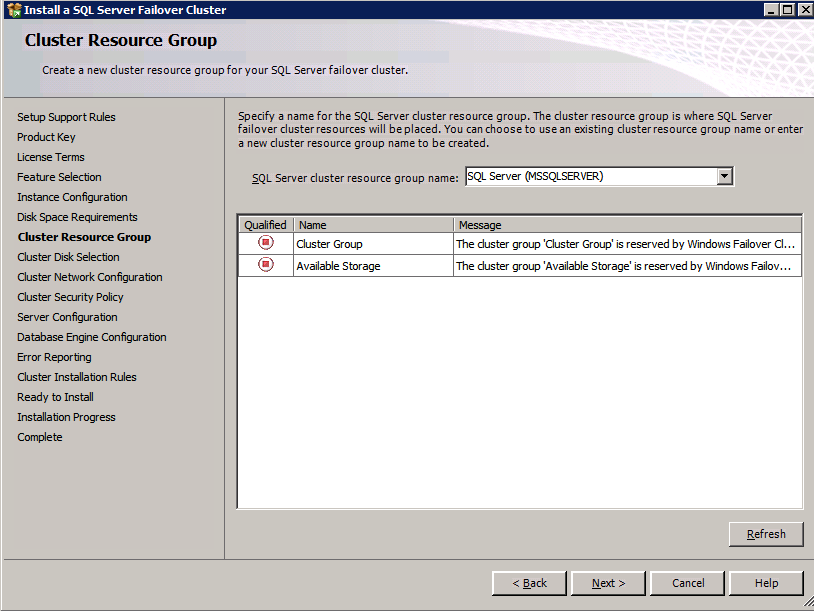
当在同一Windows群集上安装多个SQL Server实例时,挂载点通常用于SQL Server FCI配置中。这降低了SQL Server许可证的总体成本。它可以通过提高服务器利用率来帮助节省成本。正如我们过去所讨论的,通常可能有五个或更多驱动器与每个SQL Server实例相关联。如果每个驱动器都必须使用驱动器号,那么在大约三到四个实例中就会用完字母。因此,不是给每个驱动器一个字母,而是使用挂载点,以便每个实例只能由一个驱动器号(根驱动器)提供服务。根驱动器具有映射到没有驱动器号的单独物理磁盘的安装点。但是,正如我们上面所讨论的,使用一堆单独磁盘的概念在云中确实没有多大意义。因此,挂载点在云中变得过时。相反,我们如上所述创建RAID 0条带。每个群集实例SQL Server都将拥有自己独立的卷,该卷针对空间,性能和成本进行了优化。这解决了驱动器号耗尽的问题。此外,还可以提高存储利用率和性能,同时还可以降低云存储的成本。
结论
这篇文章是一个跳跃点,而不是权威指南。这篇文章的主要内容是让您对云和存储注意事项有不同的看法,因为它与在Azure中运行SQL Server有关。不要简单地采用您在本地进行的操作并在云中重新创建它。这几乎总会导致不太理想的性能和比必要的更大的存储费用。经Clusteringformeremortals.com许可转载
 不要丢失SQL Server 2008安全更新!让SIOS专家帮助您迁移到Azure通过利用SIOS DataKeeper降低停机时间并获得Azure 99
不要丢失SQL Server 2008安全更新!让SIOS专家帮助您迁移到Azure通过利用SIOS DataKeeper降低停机时间并获得Azure 99
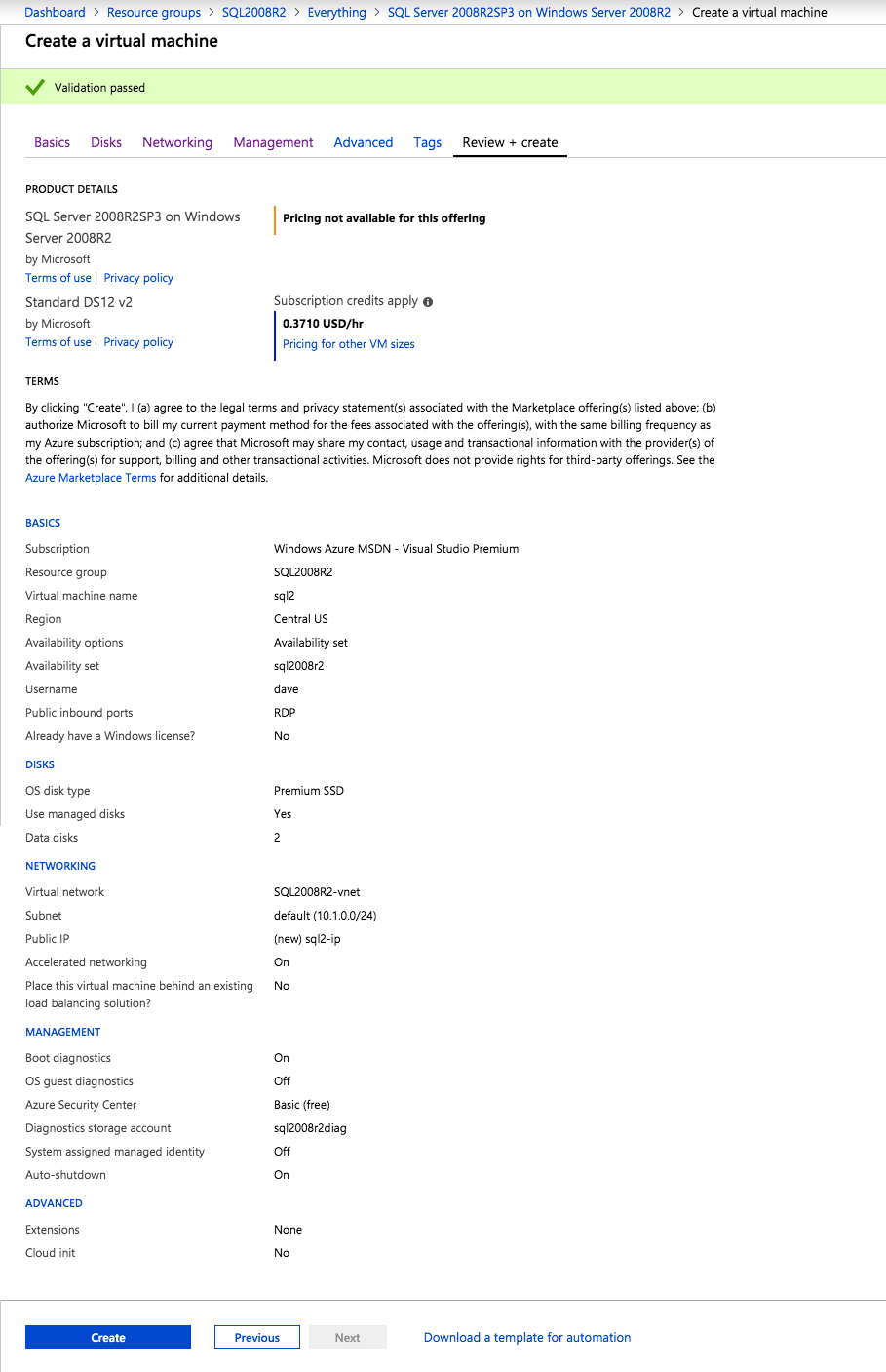
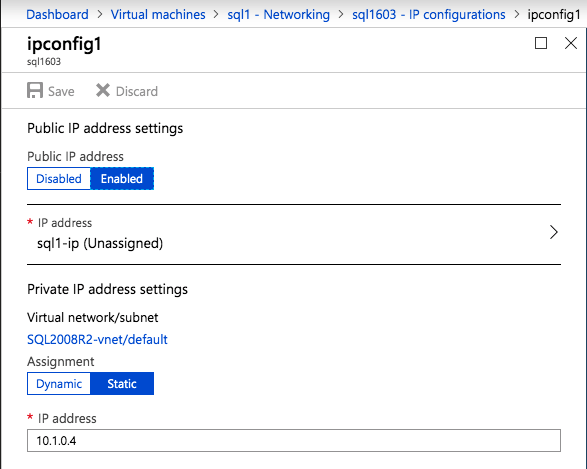
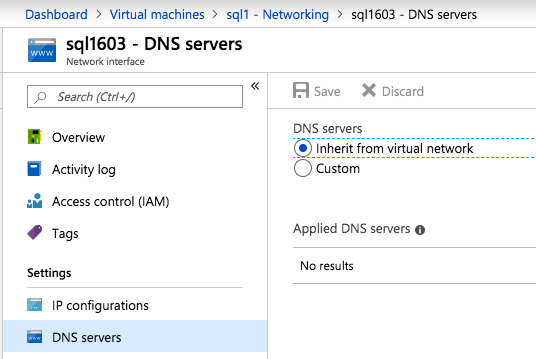
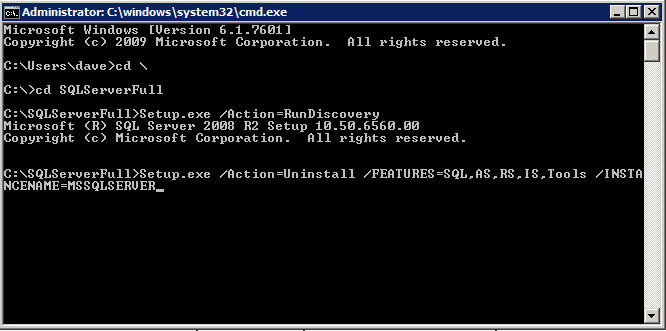

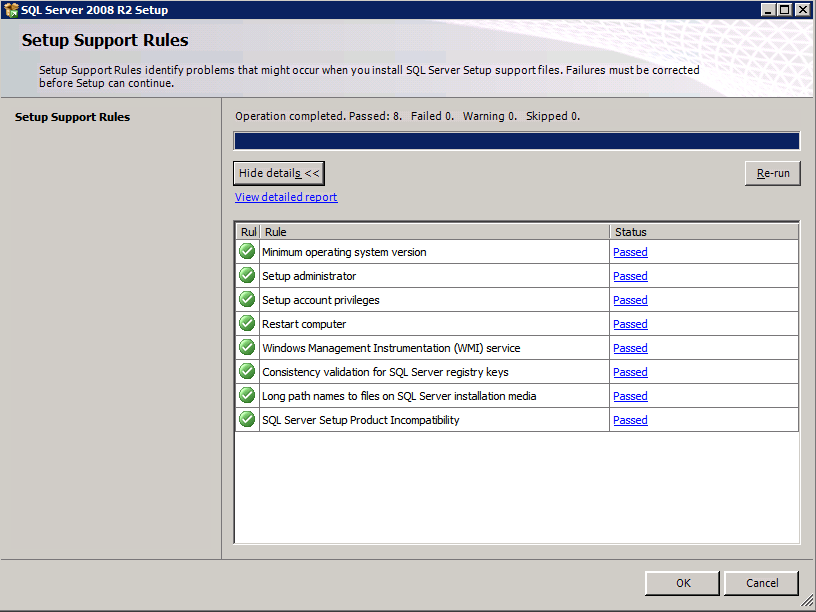
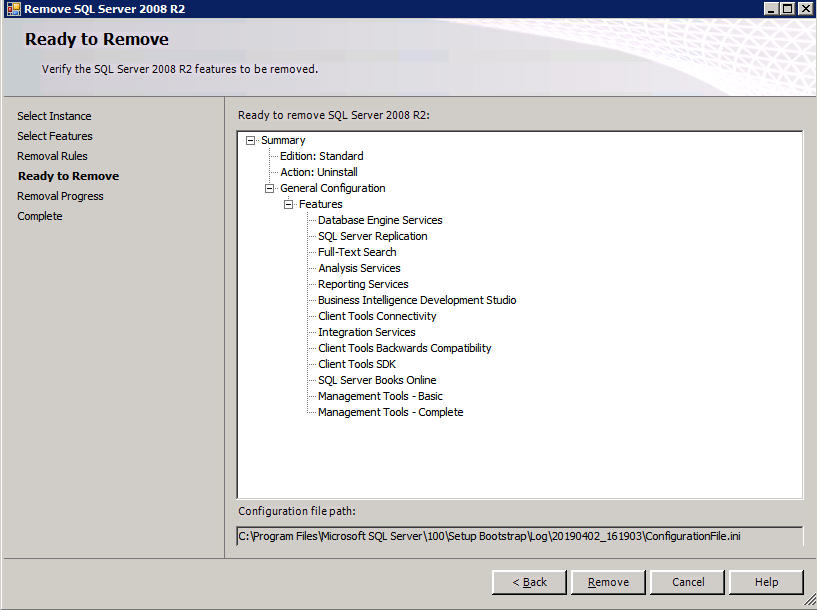
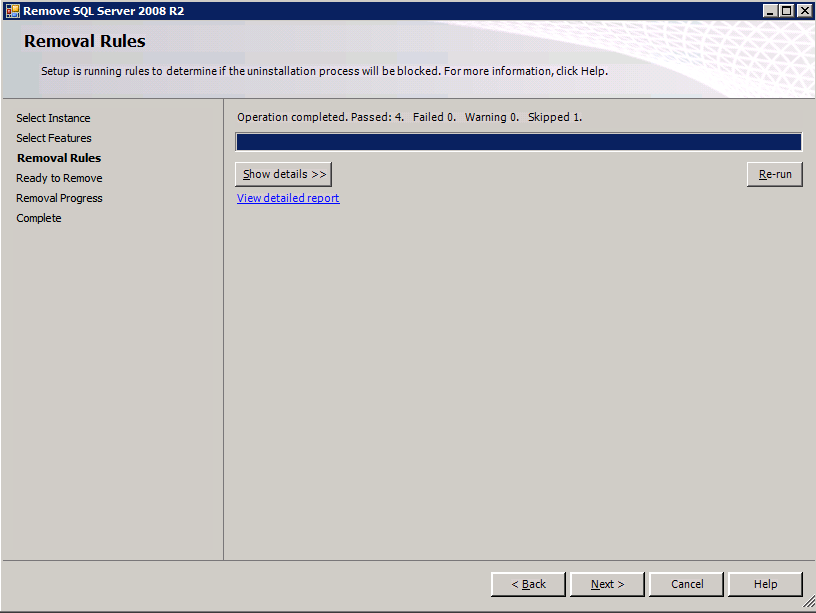
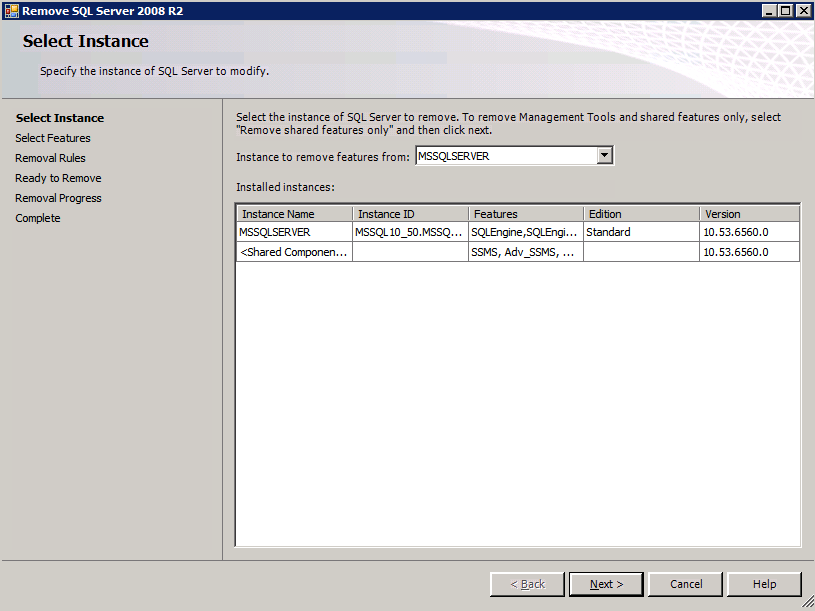
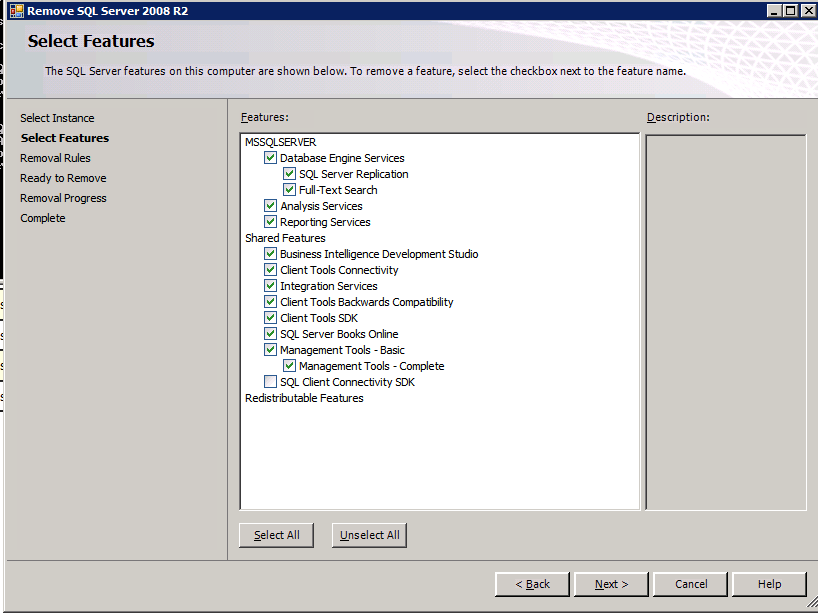
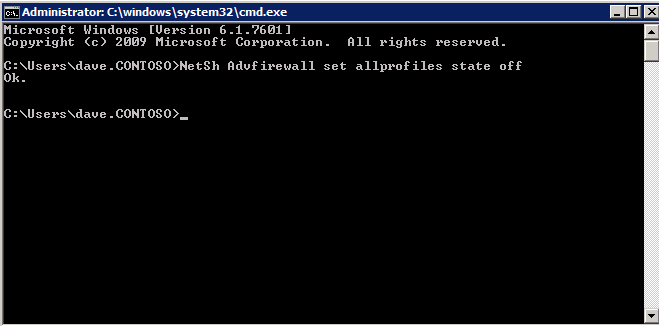
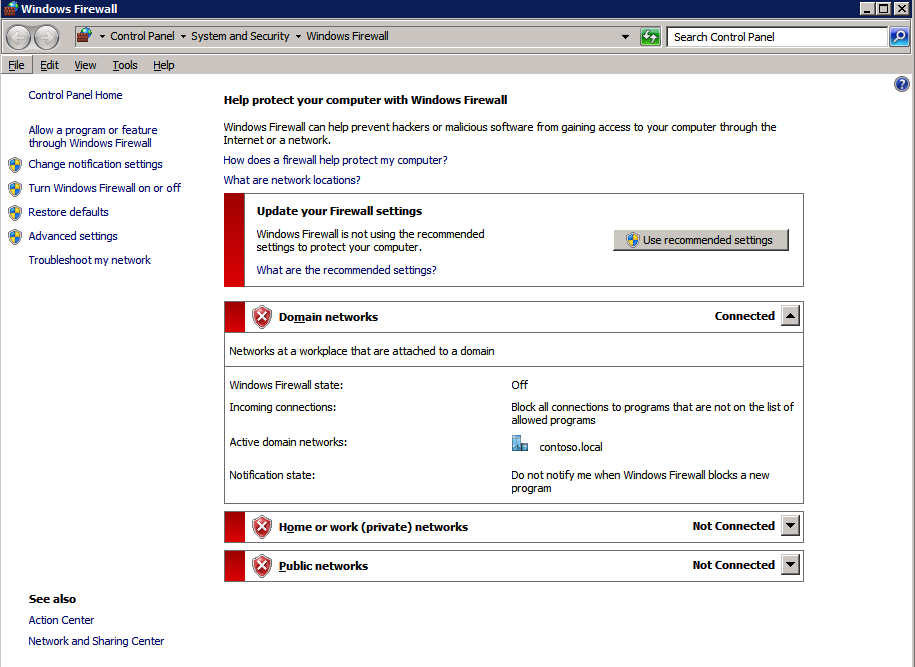
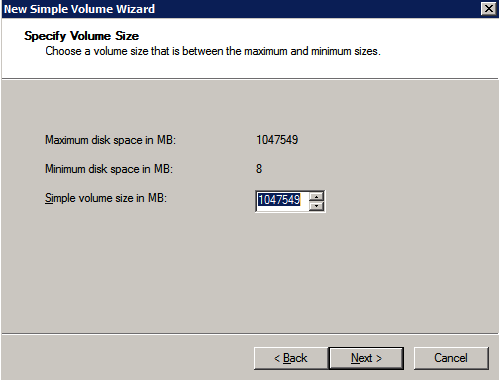
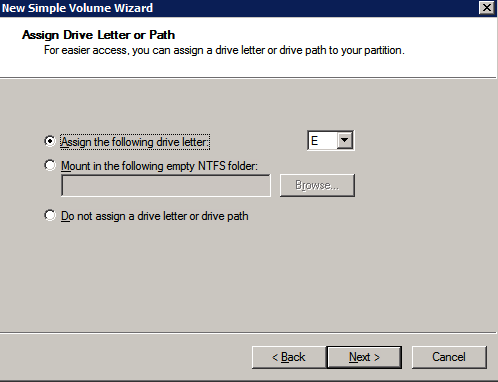
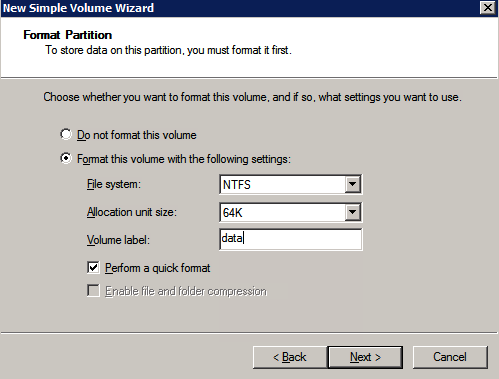
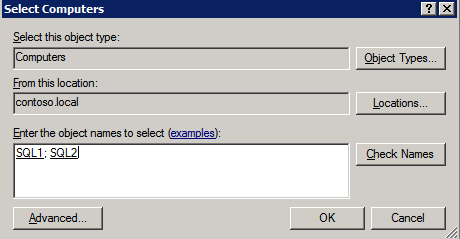
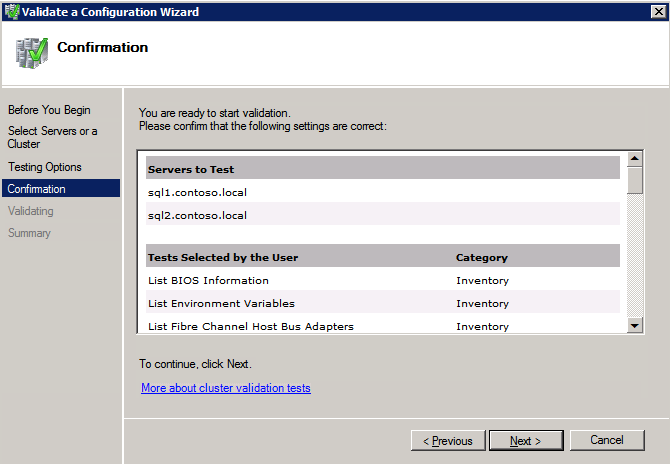
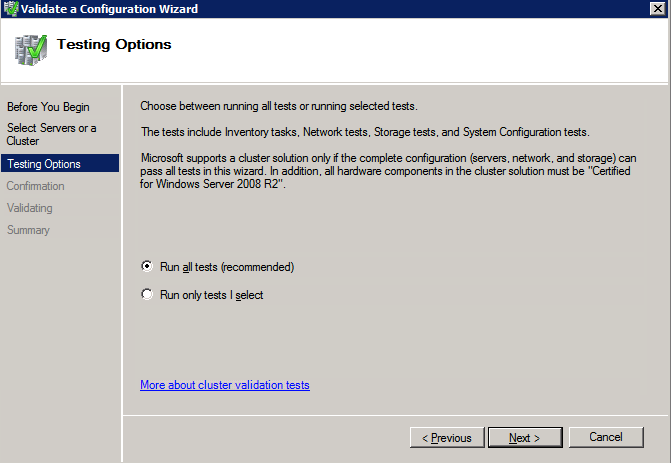
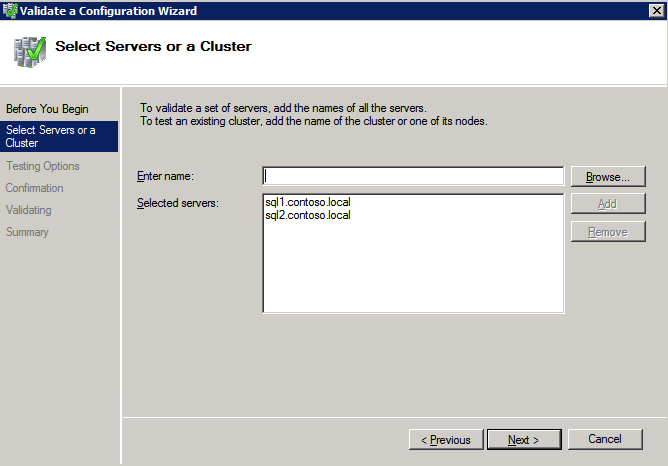
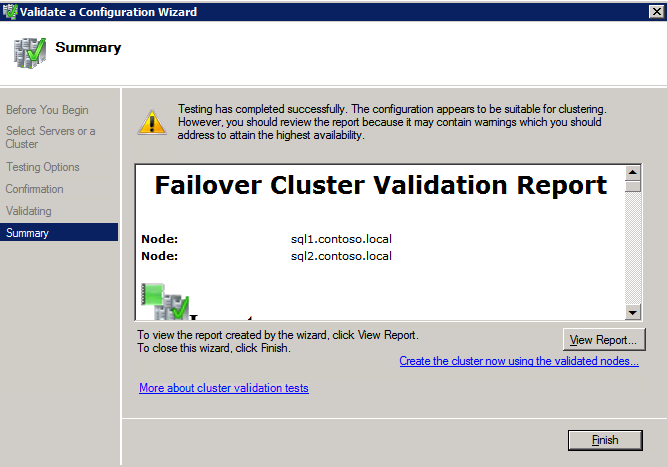
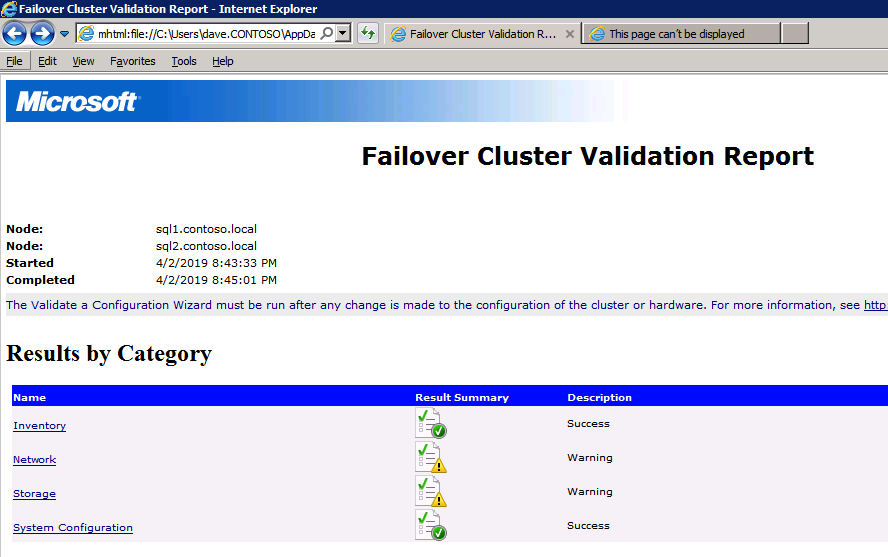
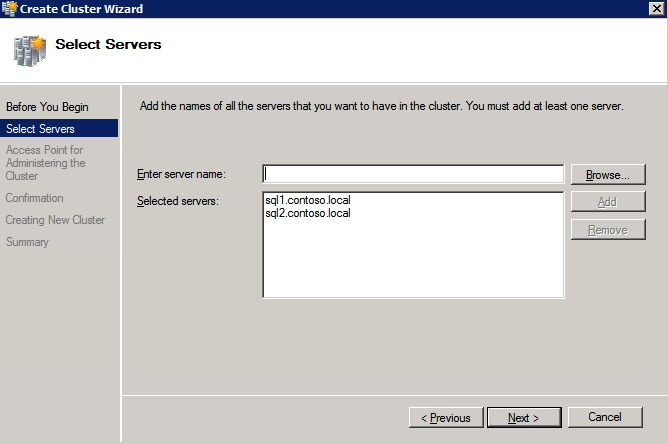
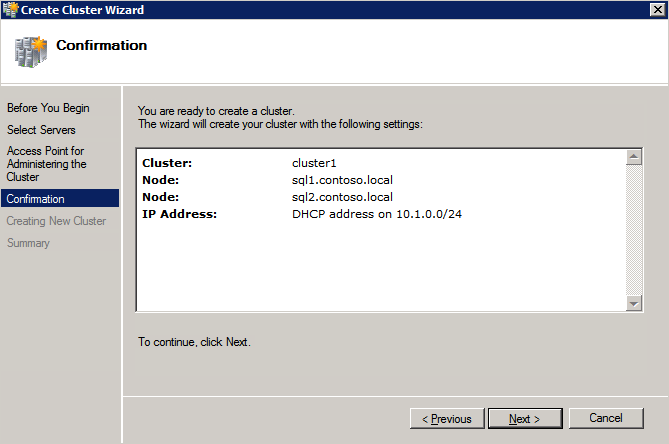
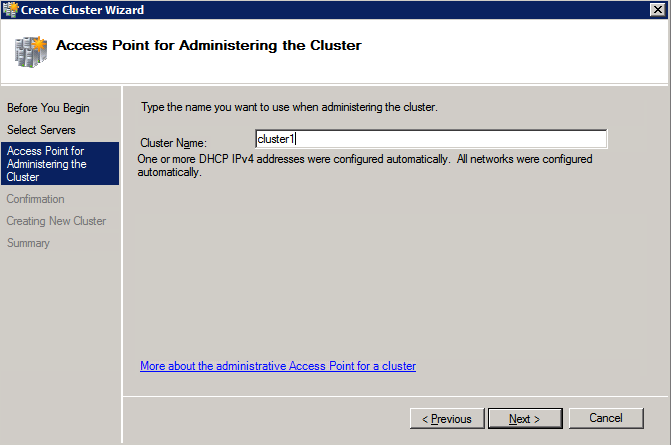
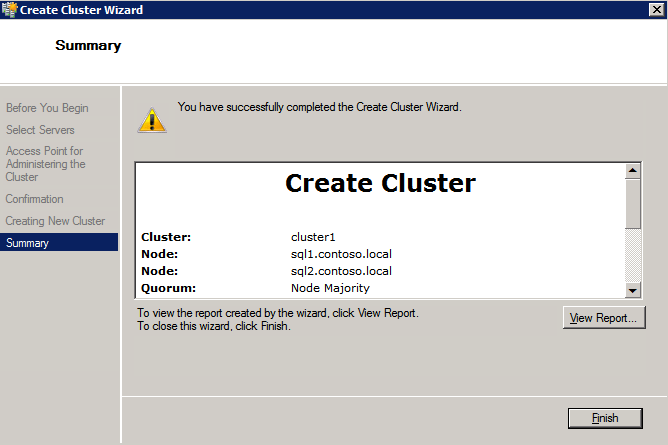
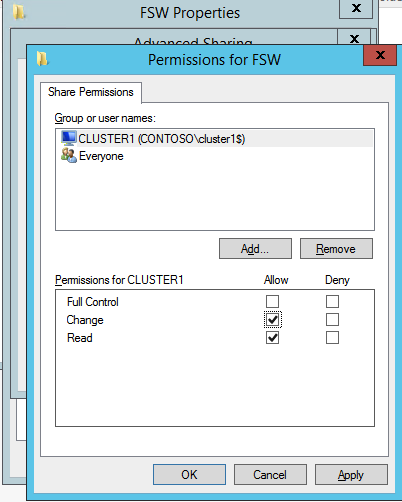
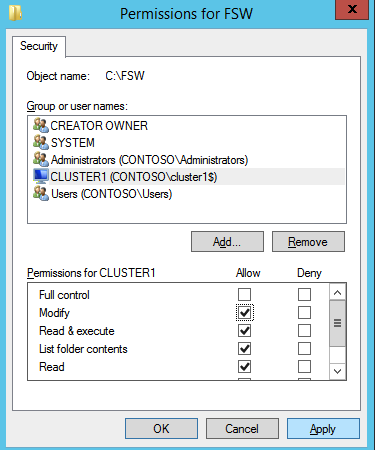
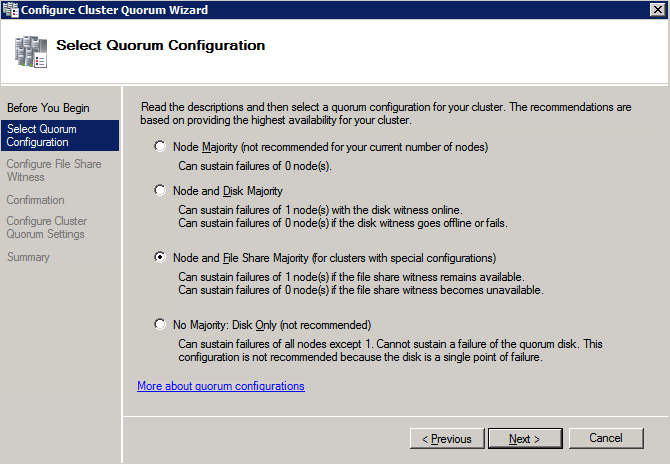
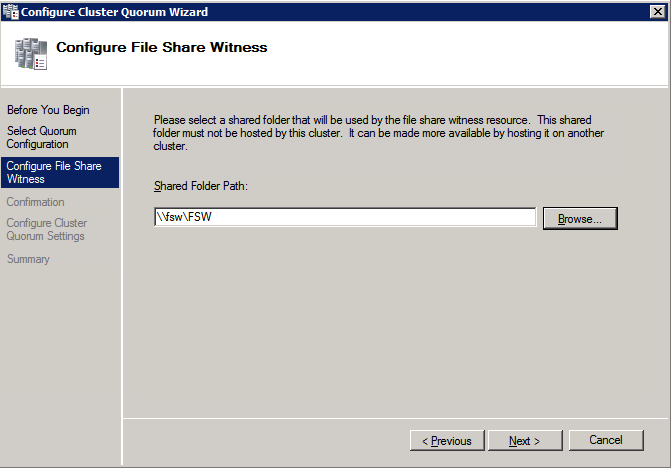
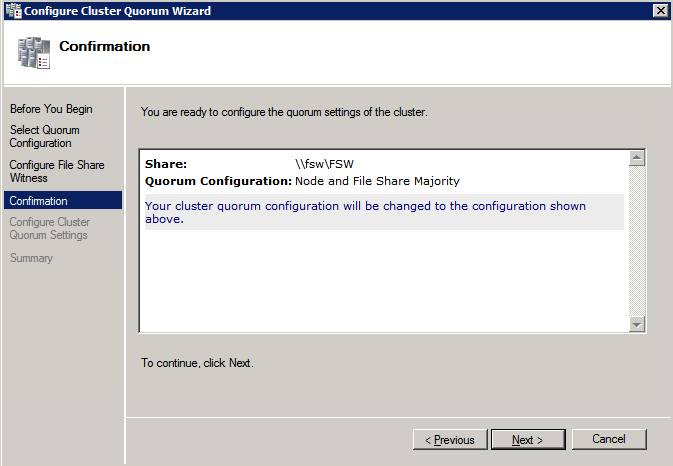
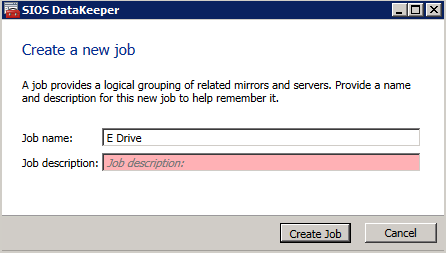
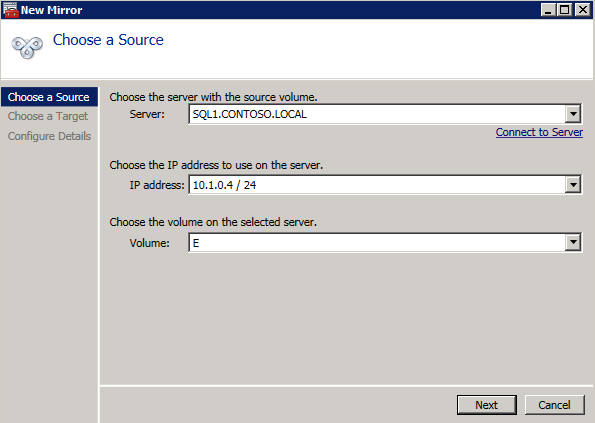
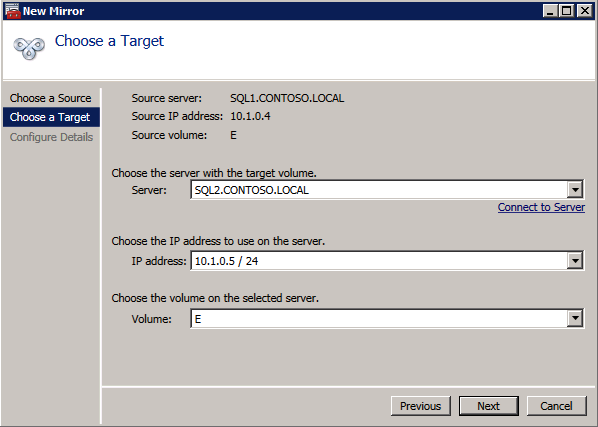
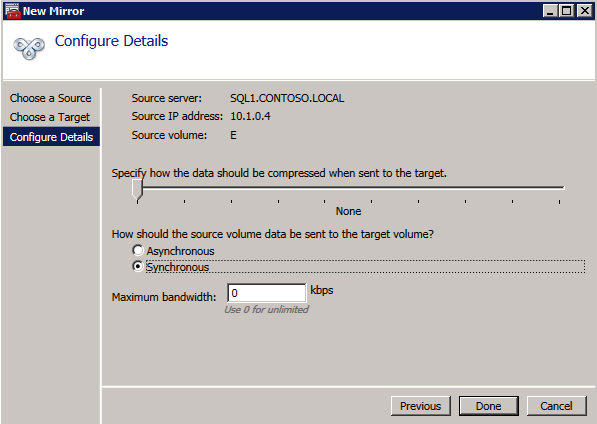
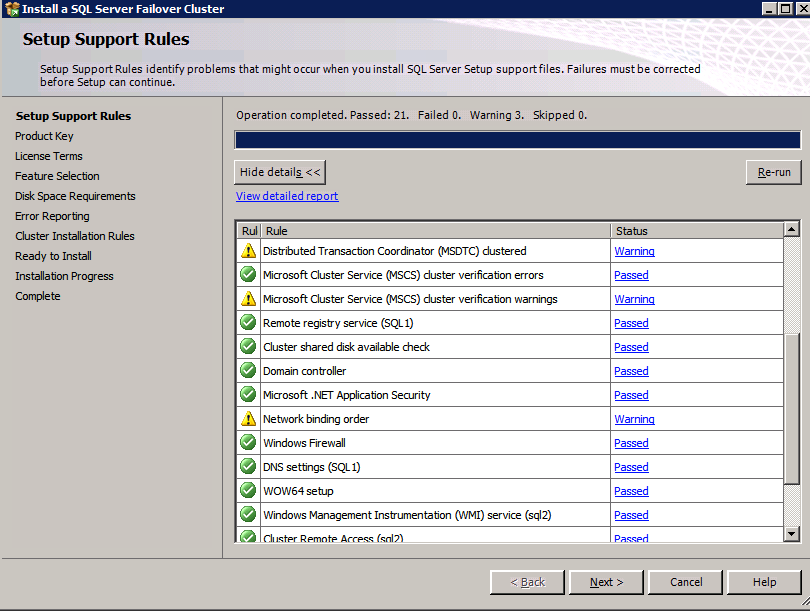
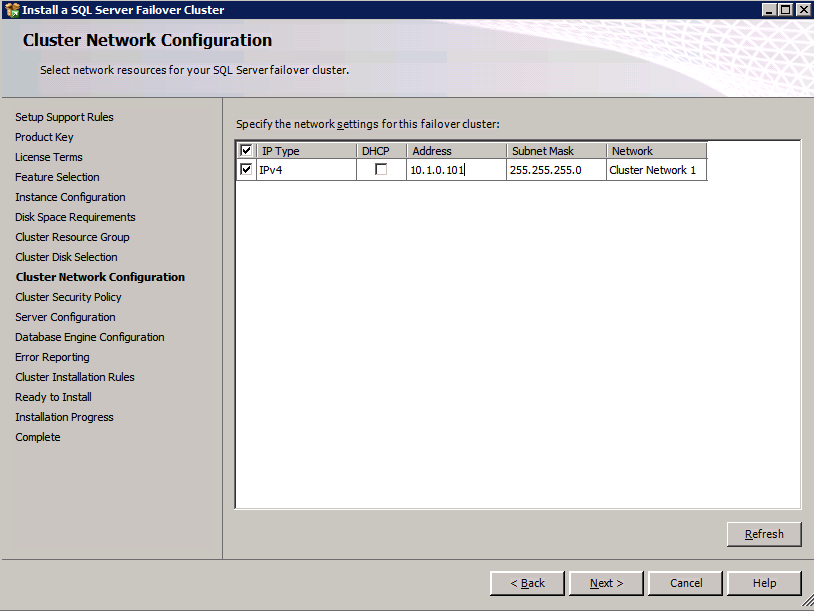
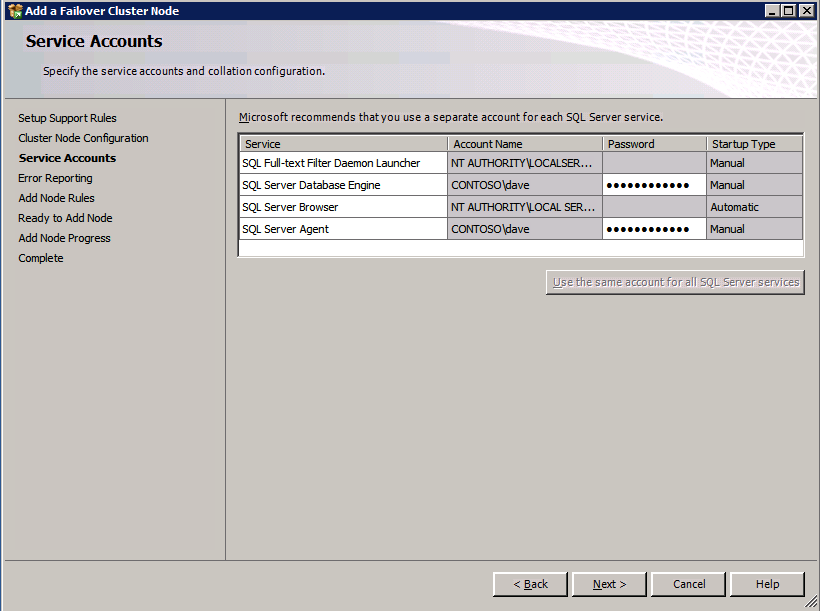
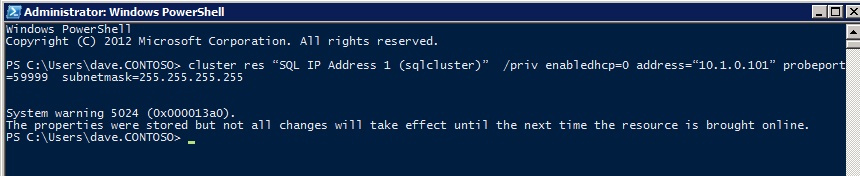
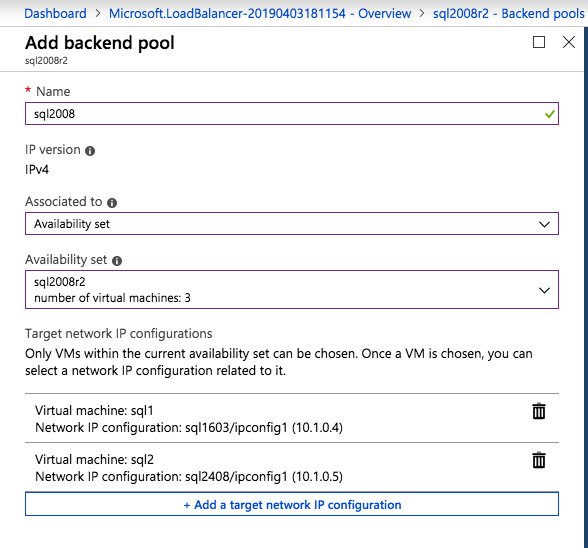
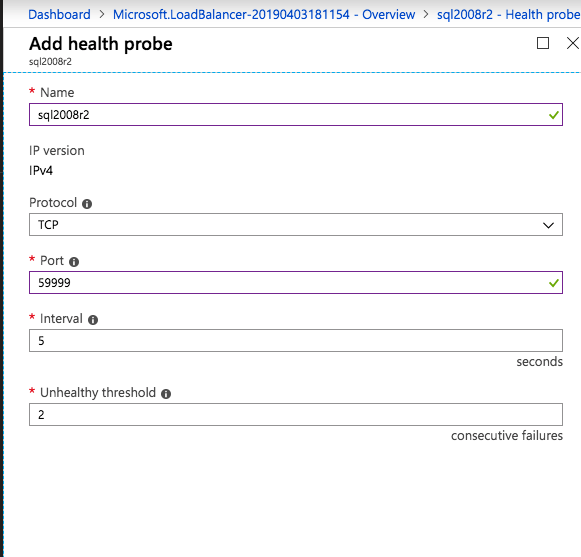
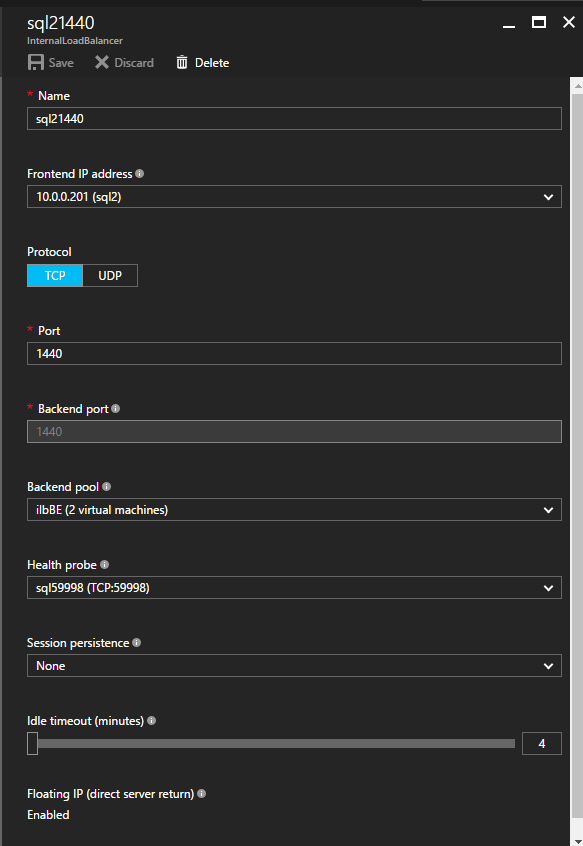
 接下来,我们将需要添加另一个探测,因为实例可以在不同的服务器上运行。如下图所示,我添加了一个探测端口59998(而不是通常的59999)的探测器。我们需要确保新规则引用此探针。我们还需要记住该端口号,因为我们需要在此过程的最后一步更新与此实例关联的IP地址。
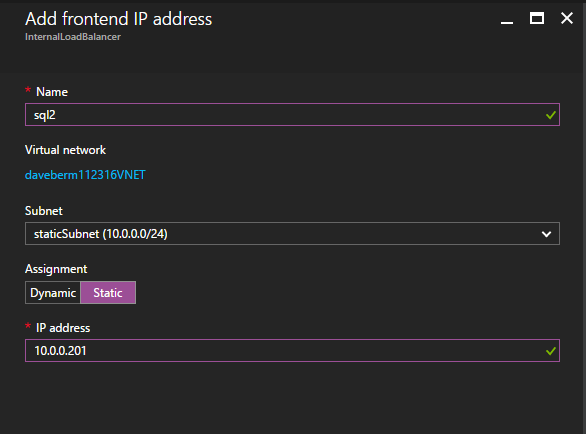
接下来,我们将需要添加另一个探测,因为实例可以在不同的服务器上运行。如下图所示,我添加了一个探测端口59998(而不是通常的59999)的探测器。我们需要确保新规则引用此探针。我们还需要记住该端口号,因为我们需要在此过程的最后一步更新与此实例关联的IP地址。 现在我们需要向ILB添加两个新规则来引导目标为第二个SQL实例的流量。当然我们需要添加一个规则来重定向TCP端口1440(我用于SQL命名实例的端口),但由于我们现在使用的是命名实例,我们还需要一个端口来支持SQL Server Browser服务,UDP端口1434。在下面描述SQL Server Browser服务规则的图片中,请注意前端IP地址引用了新的FrontendIP地址(10.0.0.201),端口和后端端口的UDP端口1434。在池中,您需要指定群集中的两个服务器,最后确保选择刚刚创建的新Health Probe。
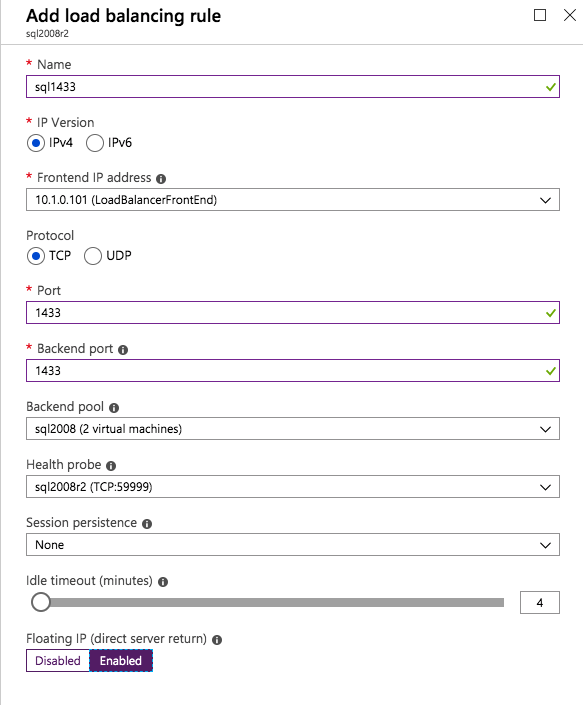
现在我们需要向ILB添加两个新规则来引导目标为第二个SQL实例的流量。当然我们需要添加一个规则来重定向TCP端口1440(我用于SQL命名实例的端口),但由于我们现在使用的是命名实例,我们还需要一个端口来支持SQL Server Browser服务,UDP端口1434。在下面描述SQL Server Browser服务规则的图片中,请注意前端IP地址引用了新的FrontendIP地址(10.0.0.201),端口和后端端口的UDP端口1434。在池中,您需要指定群集中的两个服务器,最后确保选择刚刚创建的新Health Probe。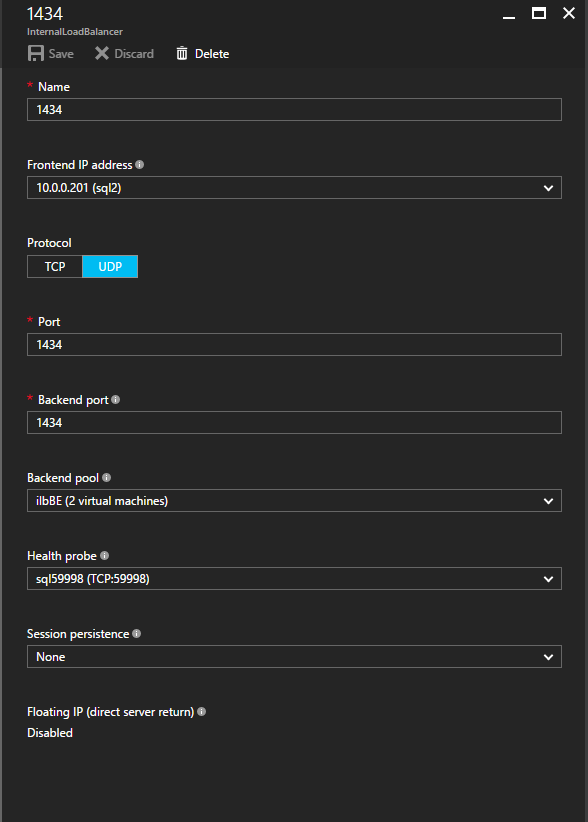 我们现在将添加TCP / 1440规则。如下图所示,为端口TCP 1440添加新规则,或为SQL Server的命名实例锁定的任何端口。同样,请务必选择新的FrontEnd IP地址和新的Health Probe(59998)。此外,请确保启用了浮动IP(直接服务器返回)。
我们现在将添加TCP / 1440规则。如下图所示,为端口TCP 1440添加新规则,或为SQL Server的命名实例锁定的任何端口。同样,请务必选择新的FrontEnd IP地址和新的Health Probe(59998)。此外,请确保启用了浮动IP(直接服务器返回)。