什么是虚拟化可用性选项?
Microsoft Windows Server 2008 R2和vSphere 4.0是最新发布的。 在考虑您的虚拟服务器和运行在其上的应用程序的可用性时,我们来看看一些虚拟化可用性选项。
我也将借此机会介绍一些启用虚拟机可用性的功能。此外,我已将这些功能分组为其功能角色,以帮助突出其功能。
计划停机
意外停机
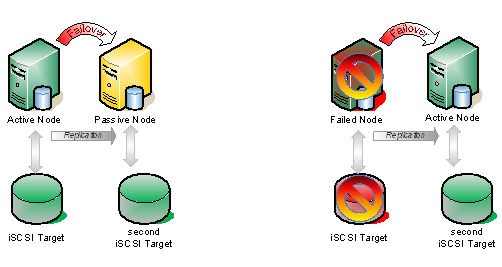
微软的Windows服务器故障转移群集和VMware的高可用性(HA)是在发生意外宕机时保护虚拟机的解决方案。两种解决方案都很相似 他们监视虚拟机的可用性。如果发生故障,VM将移动到备用节点。然后,机器重新启动以进行此恢复过程。在故障转移之前没有时间同步内存。
灾难恢复
如果在完全丢失网站的情况下如何恢复我的虚拟机?好消息是虚拟化使这个过程变得更加简单。虚拟机只是一个可以拾取并移动到另一台服务器的文件。到目前为止,VMware和微软的可用性特性和功能非常相似。但是,这是微软真正闪耀的地方。VMware提供Site Recovery Manager,这是一款很好的产品。但仅限于支持SRM认证的基于阵列的复制解决方案。此外,故障切换和故障恢复过程并不是微不足道的,可以花一天时间从灾难恢复站点到主数据中心完成一次完整的往返。它确实有一些很好的功能,如DR测试。 根据我使用Microsoft的灾难恢复解决方案的经验,在灾难恢复方面他们有更好的解决方案。
微软的Hyper-V DR解决方案
Microsoft Hyper-V DR解决方案是多站点群集配置中的Windows Server故障转移群集(请参阅视频演示)。在此配置中,性能和行为与局域集群相同,但它可以跨越数据中心。从本质上讲,您实际上可以将您的虚拟机跨越数据中心,几乎没有可感知的停机时间。故障回复是相同的过程,只需点击并点击即可将虚拟机资源移回主数据中心。没有内置的“DR测试”。尽管我认为最好在一两分钟内做一次实际的灾难恢复测试,而不会发生意外的停机时间。
基于主机的复制供应商
我还喜欢WSFC多站点群集的另一件事是复制选项不仅包括基于阵列的复制供应商,还包括基于主机的复制供应商。这确实为您提供了各种价格范围的复制解决方案,并且不需要升级现有的存储基础架构。
容错
容错功能基本上消除了在出现意外故障的情况下重新启动虚拟机的需要。VMware在这方面具有优势,因为它提供了VMware FT。还有一些第三方的硬件和软件供应商也在这个领域发挥作用。实施FT系统时有很多限制和要求。如果您需要确保硬件组件故障导致零宕机时间与在标准HA配置中启动VM时所需的一两分钟时间,则这是一个选项。您可能希望确保现有服务器已满载热备用CPU,RAM,电源等。你有冗余的路径到网络和存储。否则,你可能会在糟糕的时候投入好的钱。容错性对于防止硬件故障非常有用。如果您的应用程序或虚拟机的操作系统表现不佳,会发生什么情况?这就是当你需要应用程序级集群时,如下所述。
应用可用性
到目前为止,我所讨论的所有内容都只考虑了物理服务器和整个虚拟机的健康状况。这一切都很好,但是,如果你的虚拟机蓝屏?或者如果最新的SQL服务包破坏了你的应用程序?在这些情况下,这些解决方案都不会对你有一点帮助。对于那些最关键的应用程序,您确实必须在应用程序层进行集群。研究在虚拟机上操作系统内部与管理程序内部运行的群集解决方案。在微软的世界里,这意味着MSCS / WSFC或第三方集群解决方案。在虚拟机内进行群集时,您的存储选项的范围受到iSCSI目标或基于主机的复制解决方案的限制。 目前,VMware确实没有解决这个问题的方法。它将遵循在虚拟机内运行的解决方案,以实现应用层监控。
概要
随着虚拟化的出现,这实际上不是您是否需要可用性的问题。还有更多关于什么是虚拟化可用性选项将有助于满足您的SLA和/或DR要求的问题。我希望这些信息可以帮助您了解可用的可用性选项。
转载https://clusteringformeremortals.com/2009/08/14/making-sense-of-virtualization-availability-options-2/许可
阅读我们的成功案例,了解SIOS如何为您提供帮助