High Availability Clusters in VMware vSphere without Sacrificing Features or Flexibility
Six key facts you should know about high availability protection in VMware vSphere
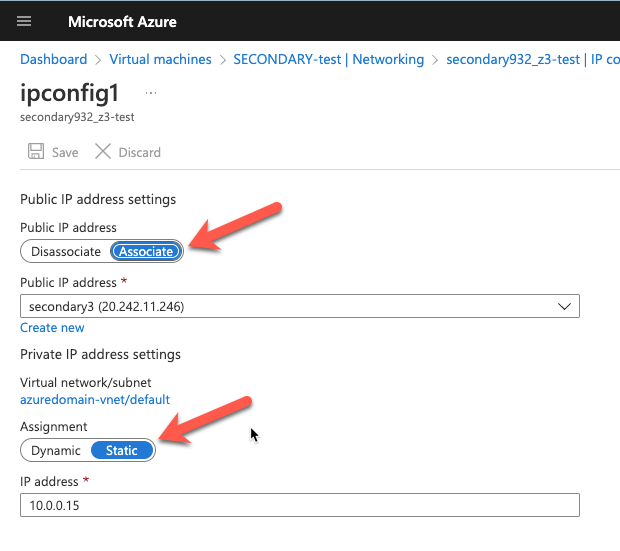
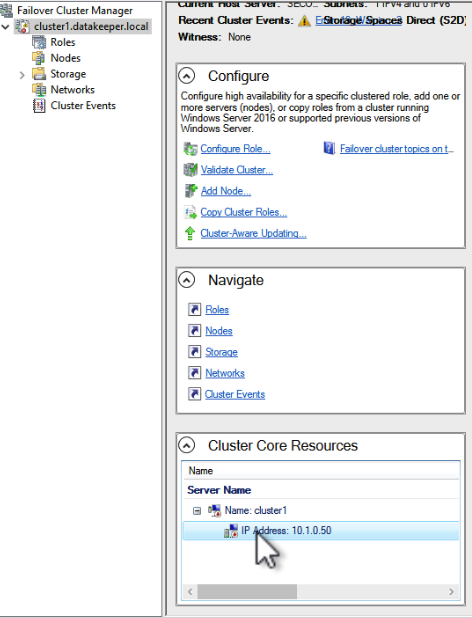
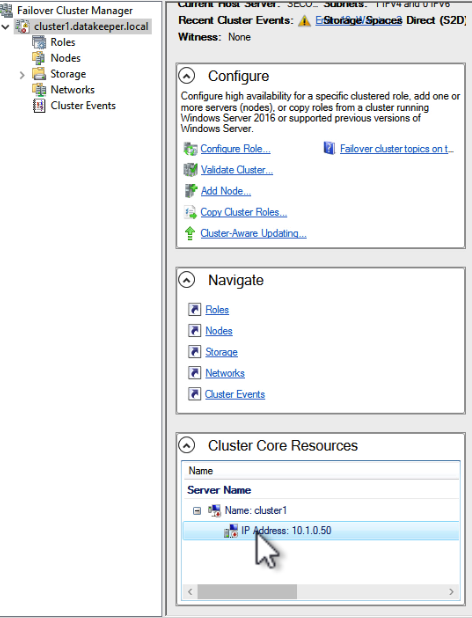
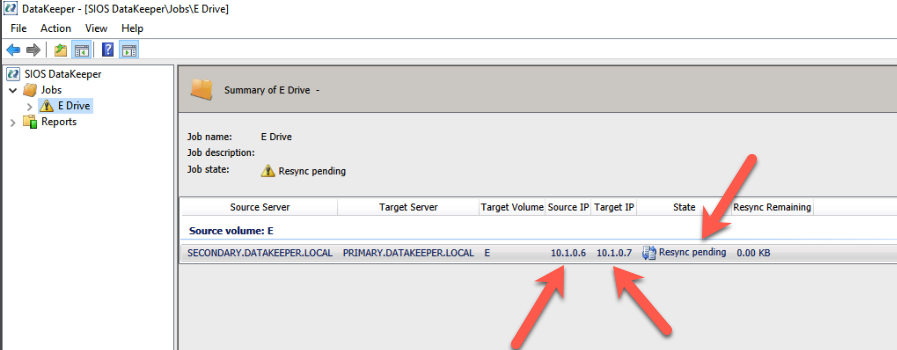
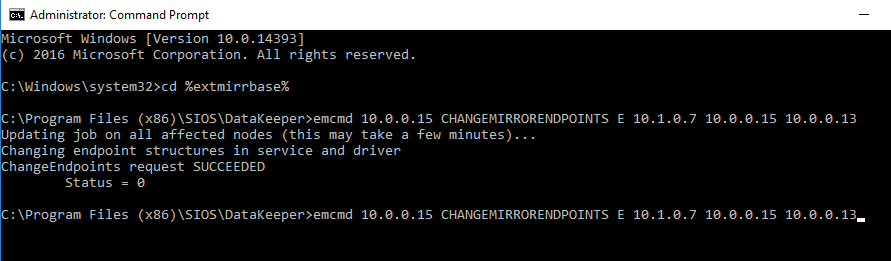
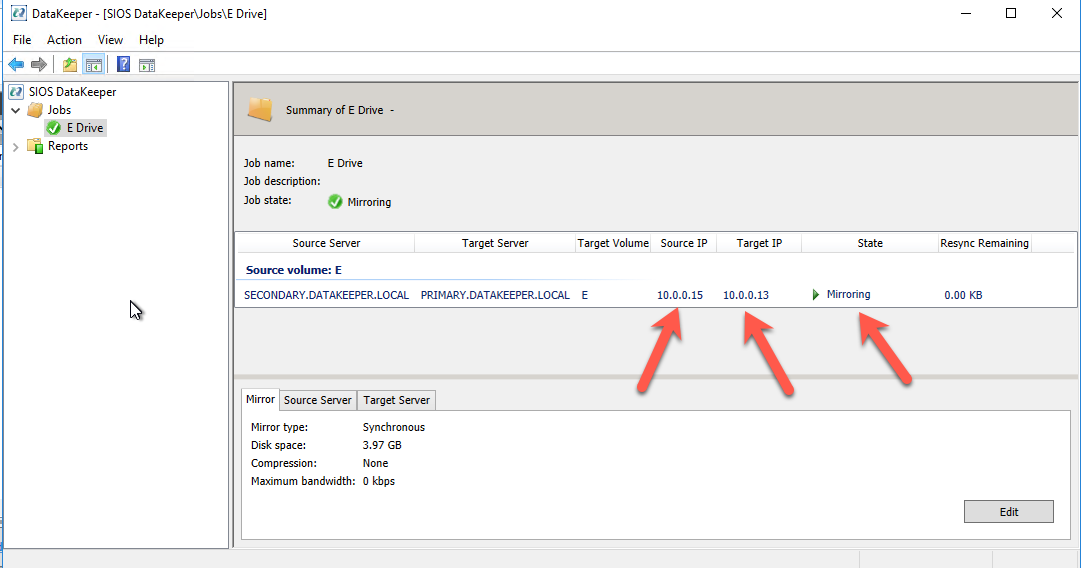
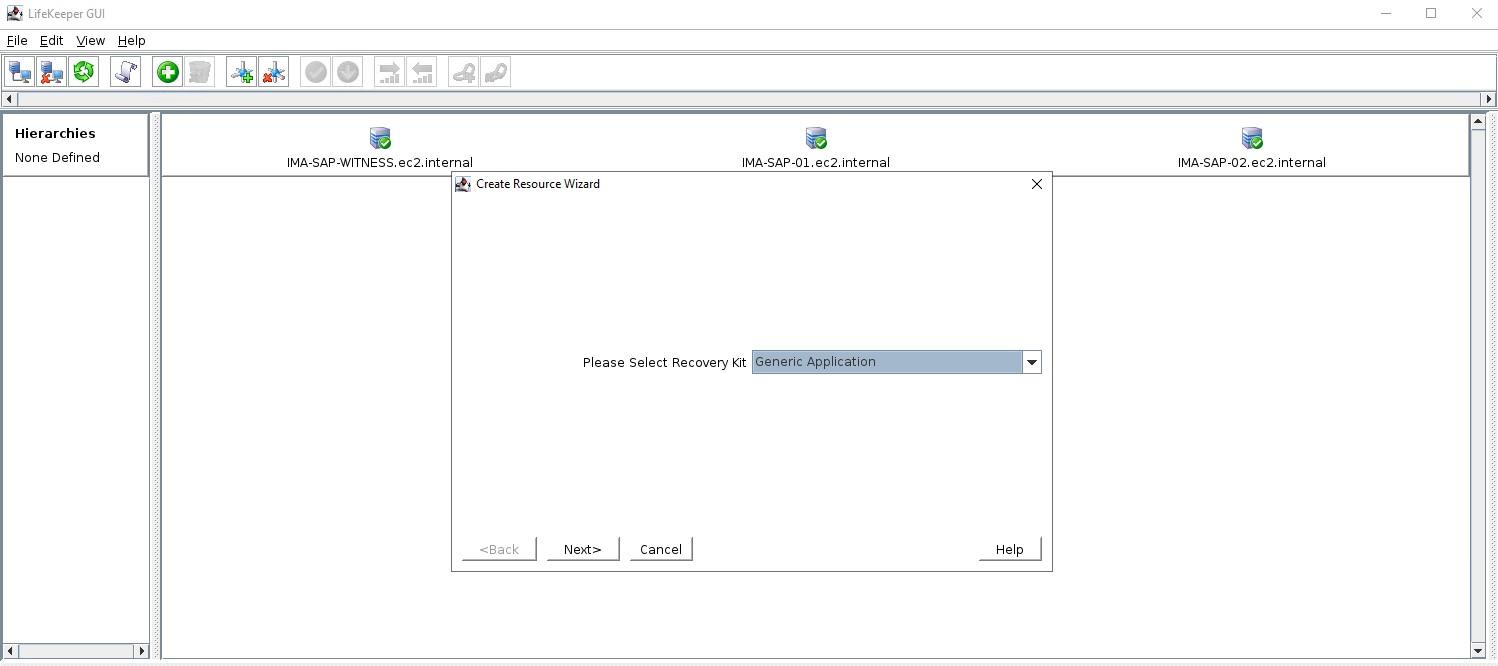
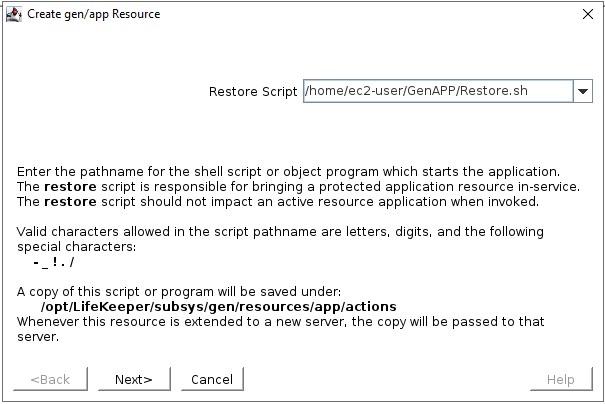
Many large enterprises are moving important applications from traditional physical servers to virtualized environments, such as VMware vSphere in order to take advantage of key benefits such as configuration flexibility, data and application mobility, and efficient use of IT resources. Realizing these benefits with business-critical applications, such as SQL Server or SAP can pose several challenges.
This paper explains these challenges and highlights six key facts you should know about HA protection in VMware vSphere environments that can save you money.
Reproduced with permission from SIOS