Webinar: Secure your SAP and SAP S/4HANA on Azure: Disaster Recovery Best Practices
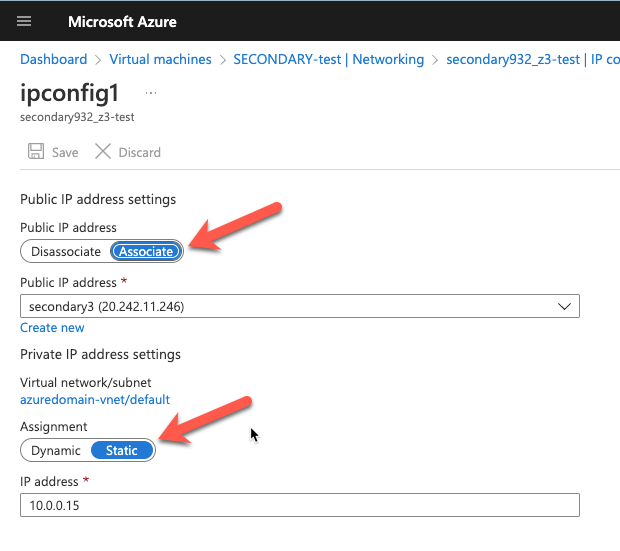
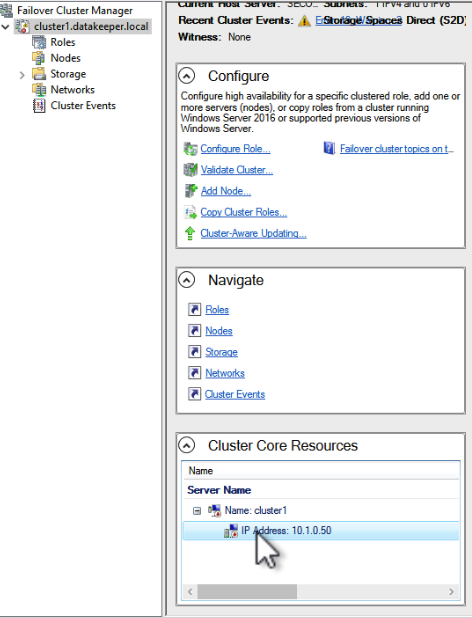
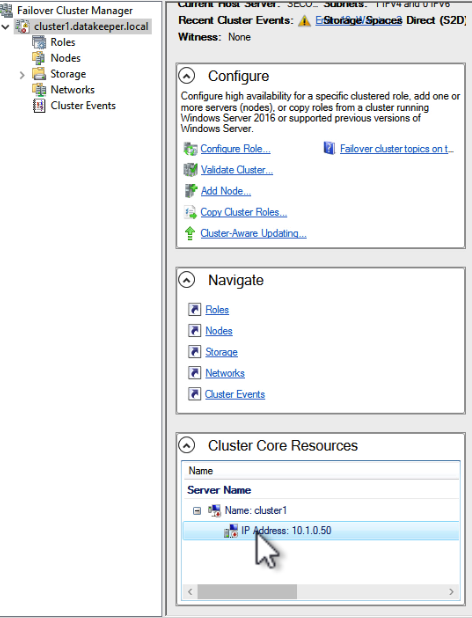
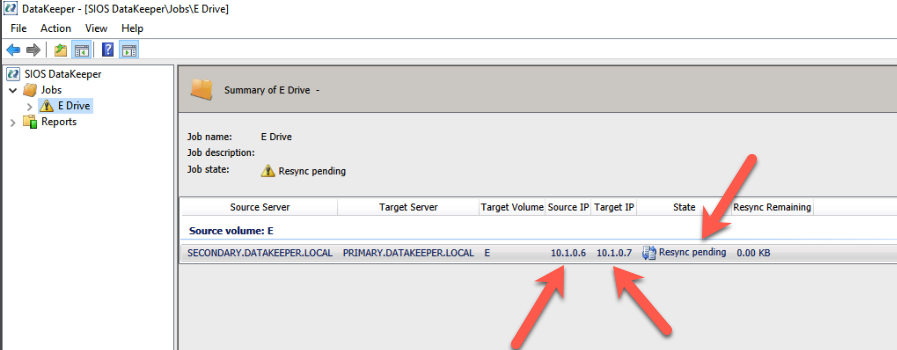
In today’s digital landscape, securing critical business applications such as SAP and SAP S/4HANA is paramount to protect against potential disasters that could impact business continuity. Leveraging the power of cloud computing, Azure provides robust disaster recovery solutions for SAP and SAP S/4HANA environments. This on-demand symposium session discusses best practices for securing your SAP and SAP S/4HANA systems on Azure, including strategies for data replication, backup and restore, high availability, and failover. Harikrishna Madathala, Microsoft Senior Customer Engineer for Fast Track at SAP on Azure cloud, shares insights, practical tips, and real-world examples to help implement disaster recovery best practices to safeguard SAP and SAP S/4HANA deployments on Azure, ensuring the highest level of security, resilience, and availability for critical business applications.
Reproduced with permission from SIOS