How APM Tools and High Availability Clusters Improve Network Resilience
Network resilience refers to a network’s ability to maintain connectivity and continue functioning even when disruptions occur. For organizations that rely heavily on technology, maintaining this resilience has become an operational necessity. A recent analysis by Siemens found that even a single hour of downtime can cost organizations millions of dollars. Downtime can interrupt production, breach service level agreements (SLAs), halt transactions, and generate significant expenses related to overtime, external consultants, incident investigations, and regulatory penalties.
In some industries, such as financial services, the consequences of weak network resilience can ripple far beyond a single organization. Global economies depend on financial institutions that operate stable and efficient IT systems capable of supporting trillions of dollars in transactions each year. Any perception that these systems are unreliable can affect entire markets. As a result, regulatory bodies such as the Basel Committee and the US Federal Reserve enforce strict standards around operational resilience. Similarly, organizations operating in sectors such as healthcare, telecommunications, and critical infrastructure must follow guidelines that ensure strong levels of network reliability and continuity.
Resilient Organizations Invest in Smart Infrastructure
IT environments, whether deployed on-premises, in the cloud, or across hybrid architectures, continue to grow in size and complexity. As a result, IT teams need tools that provide better visibility and enable smarter decision-making. Modern IT operations rely increasingly on data-driven insights and automation to support the work of IT professionals.
For this reason, forward-thinking organizations are investing in technologies that strengthen resilience and improve operational awareness. Two technologies that work particularly well together are application performance monitoring (APM) platforms and high availability (HA) clustering solutions.
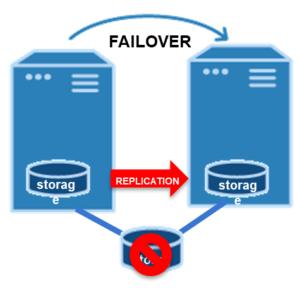
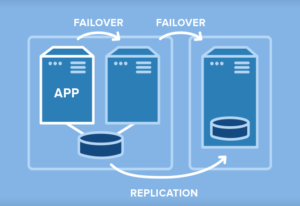
APM tools play a key role by collecting and analyzing performance data across the IT environment. This data helps organizations better understand the health and behavior of their systems, allowing administrators to establish more accurate thresholds for alerts and automated responses. High availability clusters complement this capability by ensuring services can fail over to standby systems when disruptions occur. These clusters may rely on shared storage in traditional SAN-based environments or use software-based SANless clustering that replicates data between nodes.
Combining APM and HA for Greater Network Resilience
When APM tools and HA clusters are deployed together, organizations gain stronger capabilities for improving network resilience. Monitoring insights from APM platforms can inform automation and operational decisions, while HA clusters ensure workloads continue running even when failures occur.
This combination supports capabilities such as automated failover, predictive analytics, self-healing processes, and faster incident response. These capabilities help organizations maintain higher uptime and deliver consistent application performance.
In multi-cloud environments, this approach becomes even more valuable. If a cloud provider experiences an outage, services can fail over to an alternate cloud environment. Organizations can also distribute workloads across multiple clouds to eliminate single points of failure and improve overall system resilience.
As enterprises continue moving toward more autonomous IT operations, the data gathered by APM tools provides a detailed view of system performance and health. This information allows IT teams to define precise policies and operational thresholds, enabling confident and informed decision-making when issues arise.
Using Monitoring Data to Support Failover Decisions
Consider a scenario where an IT administrator must decide whether to initiate a failover to prevent a potential outage. The cost of manually initiating the failover may exceed $50,000 due to operational disruption and recovery procedures. However, waiting too long could result in a far more expensive failure.
Without clear data, decision-makers may hesitate to act. They may worry about triggering a costly intervention based on incomplete information or intuition alone. Reliable performance data helps eliminate this uncertainty by providing objective evidence that supports informed action.
With accurate monitoring insights, teams can determine whether system conditions truly justify failover. If intervention becomes necessary, they can confidently act with data-backed justification.
This is where the combination of APM tools and HA clustering becomes particularly valuable. Together, they help maintain service continuity when performance degradation, unexpected incidents, or large-scale disruptions threaten operations. APM monitoring provides visibility into the health of infrastructure components, allowing administrators to identify issues early and respond before downtime occurs. If failover becomes necessary, the decision is guided by clearly defined parameters based on the organization’s risk tolerance.
The Advantages of HA Clusters with APM
When HA clusters are integrated with an organization’s APM platform, mission-critical applications and services can fail over automatically with minimal disruption. Automated failover reduces the risk of delays or errors that can occur during manual recovery efforts and allows operations to continue while underlying issues are addressed.
Today, many organizations are adopting SANless clustering approaches. These solutions provide the same failover capabilities as traditional SAN-based clusters but without the cost and complexity of shared storage infrastructure. SANless clusters replicate data across nodes and operate efficiently in on-premises, cloud, or hybrid environments.
They also support geographically distributed deployments across multiple data centers or regions, which is essential for effective disaster recovery planning.
Whether an organization operates in a highly regulated industry or simply wants to strengthen its reliability and operational stability, combining APM monitoring with high availability clustering offers a practical and effective strategy. Together, these technologies provide a straightforward and cost-efficient way to improve uptime, strengthen resilience, and meet the growing expectations for reliable IT services.
Strengthen Network Resilience with High Availability Clustering
Keep your applications running even when failures occur. SIOS high availability clustering helps organizations maintain uptime, automate failover, and protect critical systems from downtime.
Request a demo to see how SIOS can help strengthen your network resilience.
Reproduced with permission from SIOS