SIOS Technology Joins Nutanix Elevate Partner Program
SIOS Technology Corp. announced its membership in the Nutanix Elevate Partner Program, marking a milestone in providing easy-to-use HA clustering solutions for critical applications within Nutanix AHV environments.
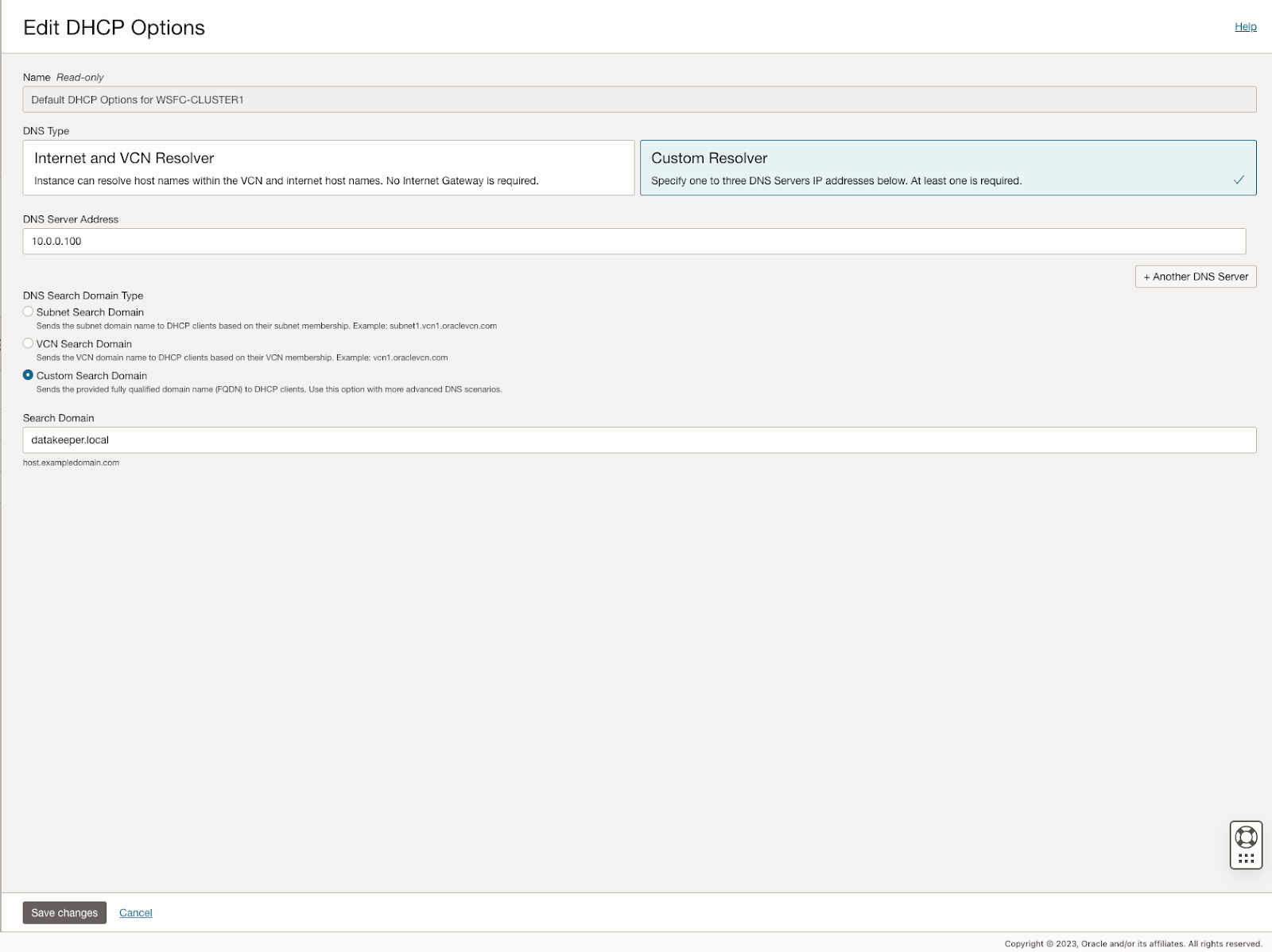
The completion of the Nutanix Ready validation designation awarded to SIOS demonstrates SIOS LifeKeeper and DataKeeper‘s interoperability with the Nutanix infrastructure. As part of this validation, The 2 partners are collaborating to help joint customers benefit from continued innovation.
SIOS’ track record includes successful implementations for customers enabling HA and DR with more than 80,000 licenses installed globally, protecting applications for companies in a range of industries.
LifeKeeper and DataKeeper products have completed verification testing, which can give customers added confidence regarding the compatibility of the solution. LifeKeeper for Linux enables Nutanix to offer customers simple, reliable HA for business-critical applications backed by deep HA expertise. With SIOS products, Nutanix customers with intrinsically complex environments, such as SAP, HANA, SQL Server, and others running in SUSE Linux, Red Hat Linux, Oracle Linux, Rocky Linux and Windows Server can save time and eliminate costly downtime by implementing, maintaining, and managing stable, reliable HA environments.
Margaret Hoagland, VP of global marketing, SIOS, said: “Joining the Nutanix Elevate Partner Program is a testament to our commitment to delivering robust HA solutions to customers, extending our reach and providing Nutanix users with the reliability and simplicity they need to ensure uninterrupted operations for their critical applications.“
SIOS Products Awarded “Nutanix Ready Validated” Designation, include:
LifeKeeper for Linux provides HA for the widest spectrum of Linux OS distributions, versions, and platforms; on-prem, virtual, and cloud. SIOS’s portfolio of HA/DR products includes bandwidth efficient, host-based block-level replication, application recovery kits (ARKs) to enable application awareness for SAP, HANA, and other popular databases and applications as well as a generic customizable ARKs. LifeKeeper for Linux provides automated monitoring, issue detection and intelligent recovery for applications, databases, and storage to ensure critical systems and applications remain highly available.