Availability SLAs: FT, High Availability and Disaster Recovery – Where to start
 It’s fair to say that in this modern era where many aspects of our lives are technology-driven, we live in a very instantaneous world. For example, at a click of a button, our weekly grocery order arrives on our doorstep. We can instantly purchase tickets for events or travel. Or even these days, order a brand-new car without having to go anywhere near a showroom and deal with a pushy salesperson. We are spoilt in this world of convenience.
It’s fair to say that in this modern era where many aspects of our lives are technology-driven, we live in a very instantaneous world. For example, at a click of a button, our weekly grocery order arrives on our doorstep. We can instantly purchase tickets for events or travel. Or even these days, order a brand-new car without having to go anywhere near a showroom and deal with a pushy salesperson. We are spoilt in this world of convenience.
But let’s spare a thought for all the vendors and the service providers who must underpin this level of service. They have to maintain a high level of investment to ensure that their underlying infrastructures (and specifically their IT infrastructures) are built and operated in a way where they can support this “always-on” expectation. Applications and databases have to be always running, to meet both customer demand and maximise company productivity and revenue. The importance of IT business continuity is as critical as it’s ever been.
Many IT availability concepts are floated about such as fault tolerance (FT), high availability (HA) and disaster recovery (DR). But this can raise further questions. What’s the difference between these availability concepts? Which of them will be right for my infrastructure? Can they be combined or interchanged? The first and foremost step for any availability initiative is to establish a clear application/database availability service level agreement (SLA). This then defines the most suitable availability approach.
What is an SLA?
To some extent, we all know what an SLA is, but for this discussion, let’s make sure we’re all on the same wavelength. The availability SLA is a contract between a service provider and their end-user that defines the expected level of application/database uptime and accessibility a vendor is to ensure and outlines the penalties involved (usually financial) if the agreed-upon service levels are not met. In the IT world, the SLA is forged from two measures of criticality to the business – Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO). Very simply, the RTO defines how quickly we need the application operation to be restored in the event of a failure. The RPO defines how current our data needs to be in the event of a recovery scenario. Once you can identify these metrics for your applications and databases, this will then define your SLA. The SLA is measured as a percentage, so for example, you may come across terms such as 99.9% or 99.99% available. These are measures of how many minutes of uptime and availability IT will guarantee for the application in a given year. In general, more protection means more cost. It’s therefore critical to estimate the cost of an hour of downtime for the application or database and use this SLA as a tool for selecting a solution that makes good business sense.
Once we have our SLA, we can make a business decision about which type of solution – FT, HA, DR, or a combination thereof — is the most suitable approach for our availability needs.
What is Fault Tolerance (FT)?
FT delivers a very impressive availability SLA at 99.999%. In real-world terms, an FT solution will guarantee no more than 5.25 minutes of downtime in one year. Essentially, two identical servers are run in parallel to each other, processing transactions on both servers at the same time in an active-active configuration in what’s referred to as a “lockstep” process. If the primary server fails, the secondary server continues processing, without any interruption to the application or any data loss. The end-user will be blissfully unaware that a server failure has occurred.
This sounds fantastic! This sounds superb! Why would we need anything else? But hold on…as awesome as FT sounds on paper, there are some caveats to consider.
The “lockstep” process is a strange beast. It’s very fussy about the type of server hardware it can run on, particularly in terms of processors. This limited hardware compatibility list forces FT solutions to sit in the higher end of the cost bracket, which could very much be in the hundreds of thousands of dollars by the time you factor in two or more FT clusters with associated support and services.
Software Error Vulnerability
FT solutions are also designed with hardware fault tolerance in mind and don’t pay much attention to any potential application errors. Remember, FT solutions are running the same transactions and processes at the same time, so if there’s an application error on the primary server, this will get replicated on the secondary server too.
What is High Availability (HA)?
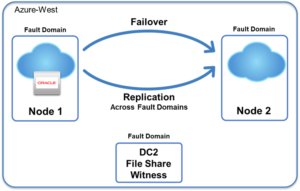
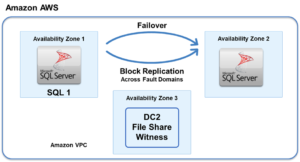
For most SLAs, FT is simply too expensive to purchase and manage for average use cases. In most cases, HA solutions are a better option. They provide nearly the same level of protection at a fraction of the cost. HA solutions provide a 99.99% SLA which equates to about 52 minutes of downtime in one year, by deploying in an Active-Standby manner. The reduced SLA is introduced as there’s a small period of downtime where the Active server has to switch over to the Standby server before operations are resumed. OK, this is not as impressive as an FT solution, but for most IT requirements, HA meets SLAs, even for supercritical applications such as CRM and ERP systems.
Equally important, High Availability solutions are more application agnostic, and can also manage the failover of servers in the event of an application failure as well as hardware or OS failures. They also allow a lot more configuration flexibility. There is no FT-like hardware compatibility list to deal with, as on most occasions they will run on any platform where the underlying OS is supported.
How does Disaster Recovery (DR) fit into the picture?
Like FT and HA, DR can also be used to support critical business functions. However, DR can be used in conjunction with FT and HA. Fault Tolerance and High Availability are focussed on maintaining uptime on a local level, such as within a datacentre (or cloud availability zone). DR delivers a redundant site or datacentre to failover to in the event a disaster hits the primary datacentre.
What does it all mean?
At the end of the day, there’s no wrong or right availability approach to take. It boils down to the criticality of the business processes you’re trying to protect and the basic economics of the solution. In some scenarios, it’s a no-brainer. For example, if you’re running a nuclear power plant, I’d feel more comfortable that the critical operations are being protected by an FT system. Let’s face it, you probably don’t want any interruptions in service there. But for most IT environments, critical uptime can also be delivered with HA at a much more digestible price point.
How to choose: FT, HA and DR?
- First and foremost, understand your business operations in detail and identify the cost of downtime.
- Once your SLAs are established, weigh up the costs of the availability solution of choice against the cost of any potential downtime.
- When choosing your availability solution, look at ease of deployment and ease of use, as these will also impact the overall TCO of the availability solution.
IT systems are robust, but they can go wrong at the most inconvenient times. FT, HA and DR are your insurance policies to protect you when delivering SLAs to customers in this instant and convenience-led world.
Reproduced with permission from SIOS