Glossary of Terms: Virtual Machines
Definition: A virtual server or virtual machine (VM) is a software based computer architecture that emulates the user experience of a hardware based server. VMs allow the user to run multiple operating systems on the same physical machine. They allow users to allocate critical resources such as compute, storage, networking as needed without the constraints of physical servers.
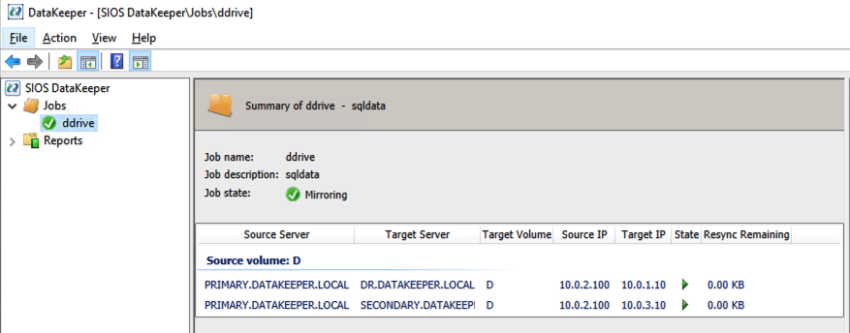
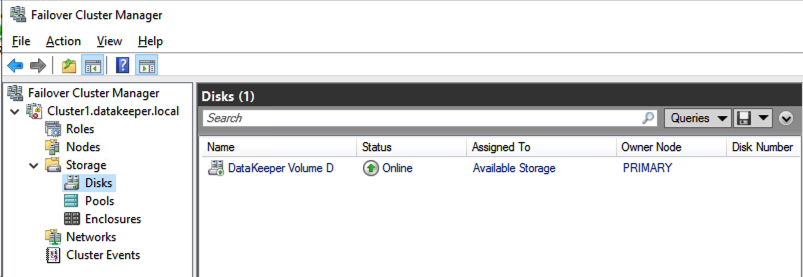
Reproduced from SIOS