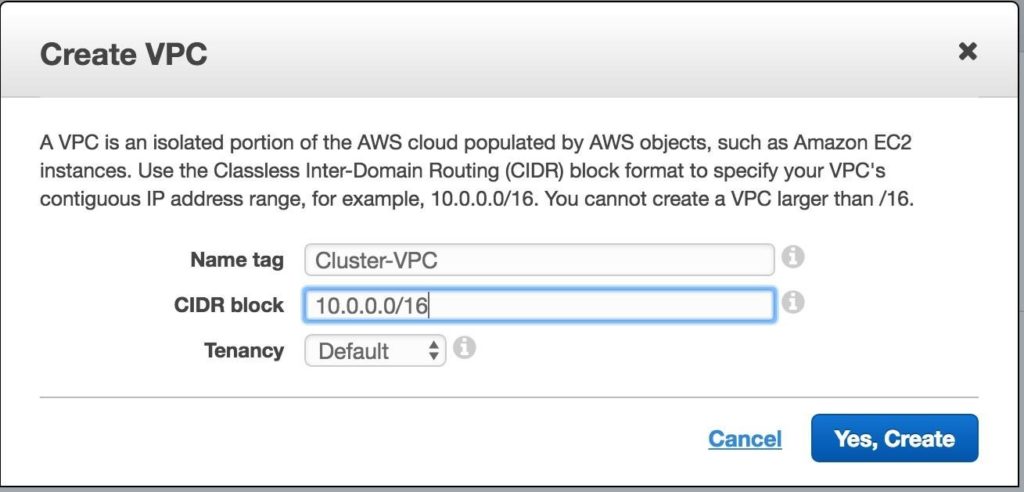
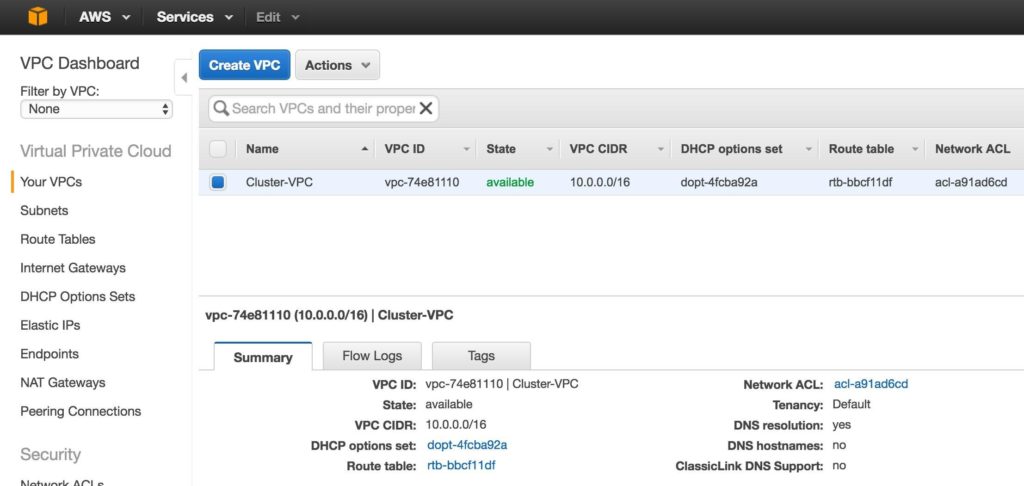
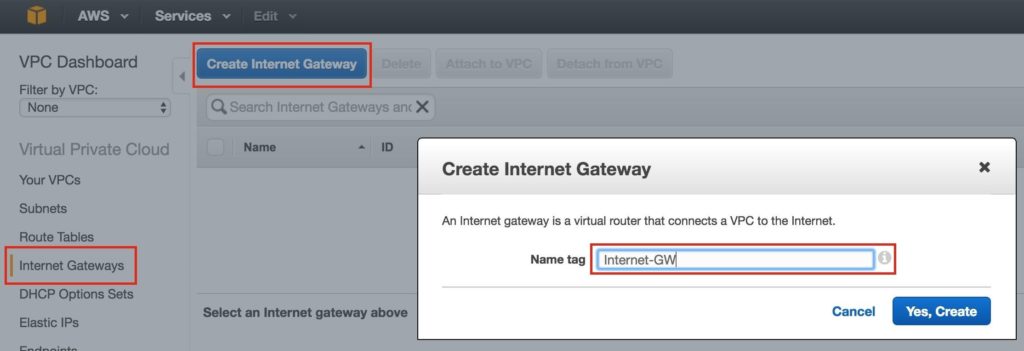
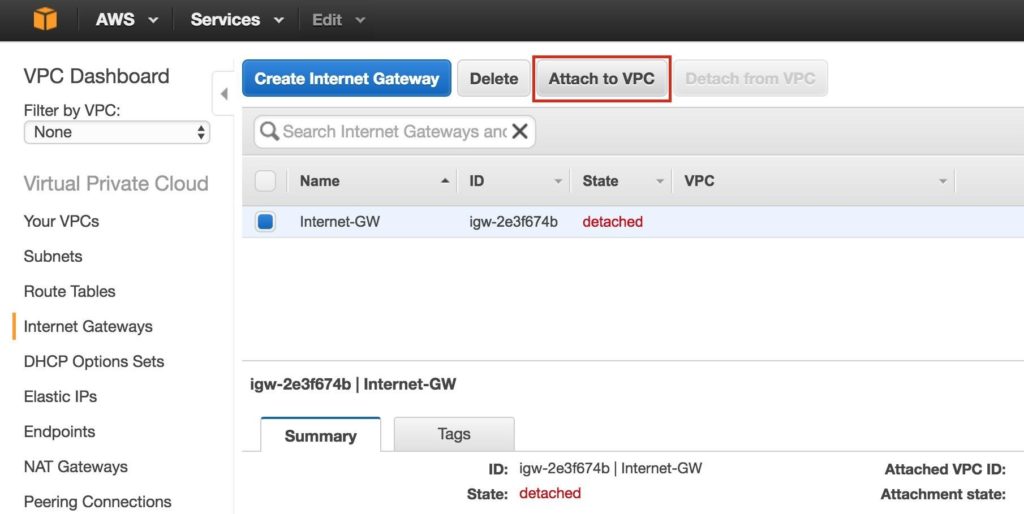
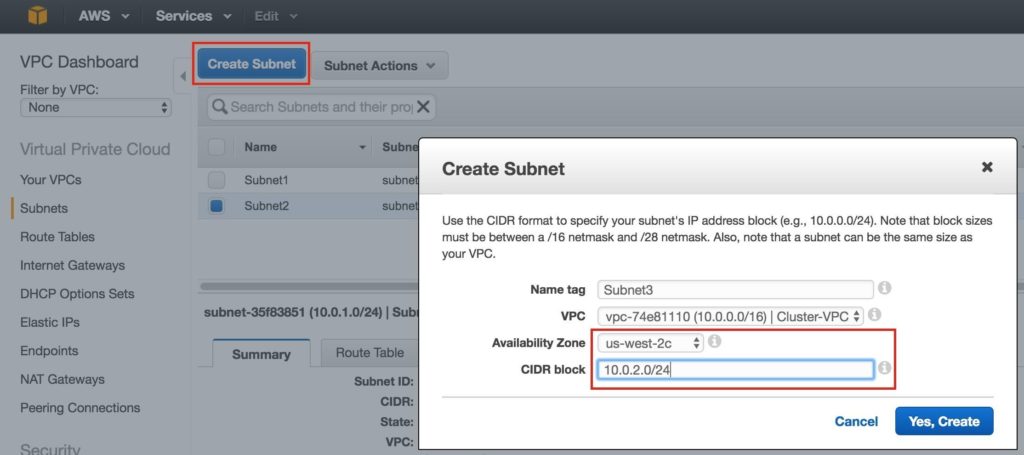
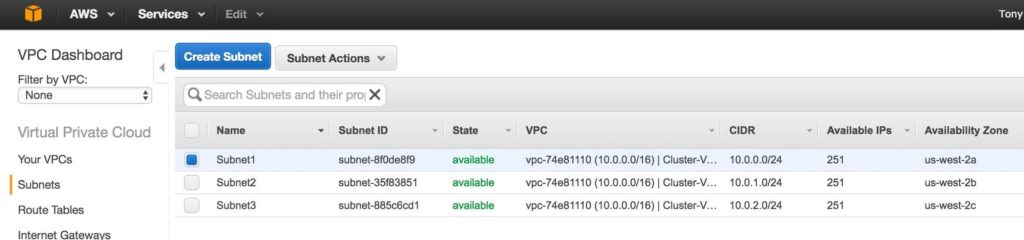
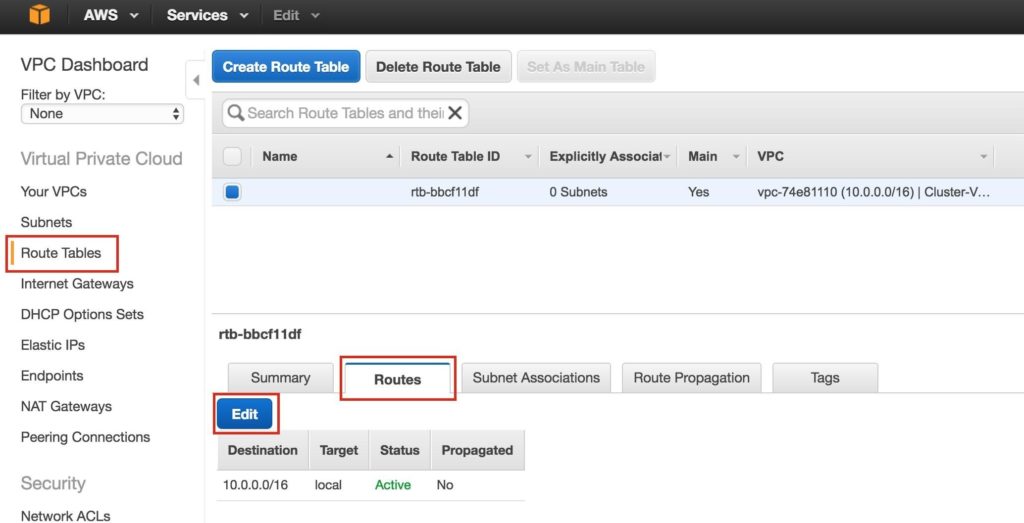
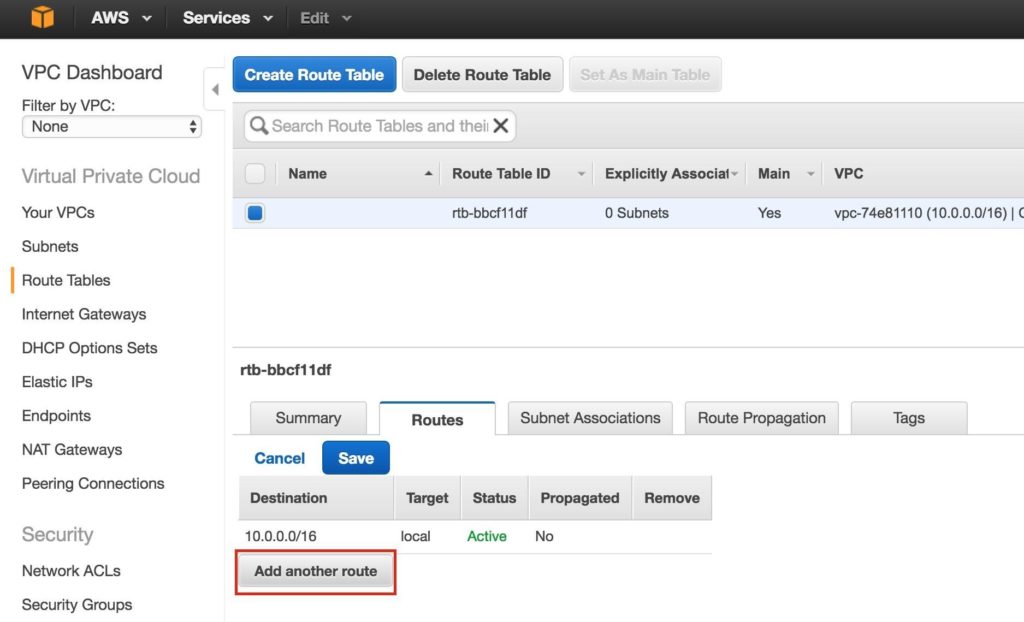
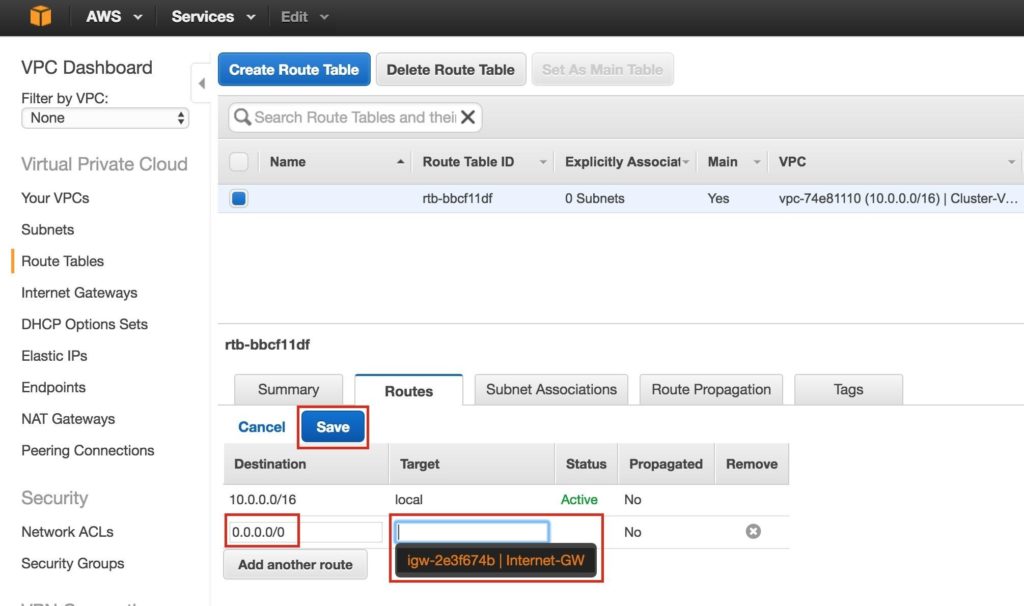
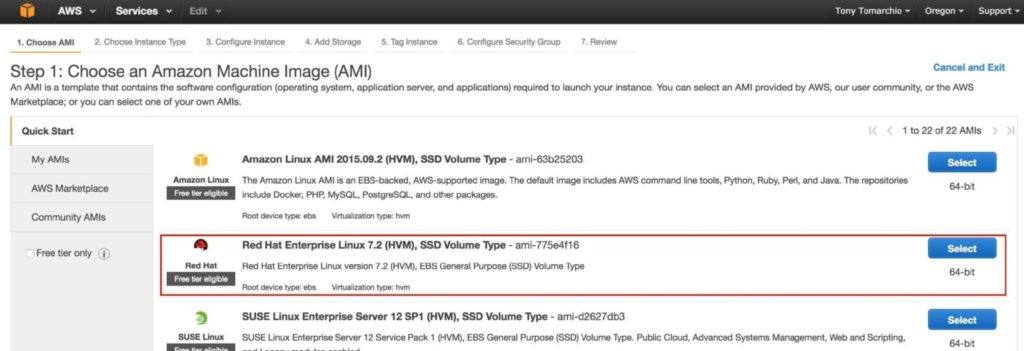
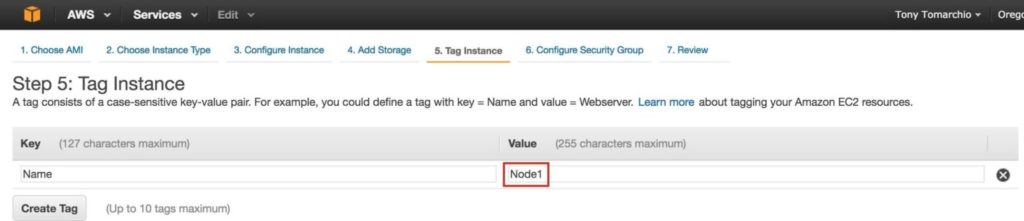
Tips for Restoring SIOS Protection Suite for Linux Configuration Specifics
Nice job “Random Co-worker”! And by nice job, I didn’t really mean nice job. And by “Random Coworker” I mean the guy who checked the box that shouldn’t be checked, or unchecked the box that should be checked, the man or woman who skipped the message and the warning, and the “Please confirm” safety measures and just wrecked your SIOS Protection Suite for Linux configuration.
We’ve all been there. It was an accident. However it happened, it happened. Suddenly you are scrambling to figure out what to do to recover the configuration, the data, and the “whatever” before the boss finds out.
As the VP of Customer Experience at SIOS Technology Corp. our teams are actively working with partners and customers to architect and implement enterprise availability to protect their systems from downtime. Accidents happen, and a recent customer experience reminded me that even with our multiple checks and warnings, even the SIOS Protection Suite for Linux product isn’t immune to accidental configuration changes, but there is a simple tip for faster recovery from the “Random Coworker’s” accidental blunder.
How to Recover SIOS Protection Suite for Linux After Accidental Configuration Changes
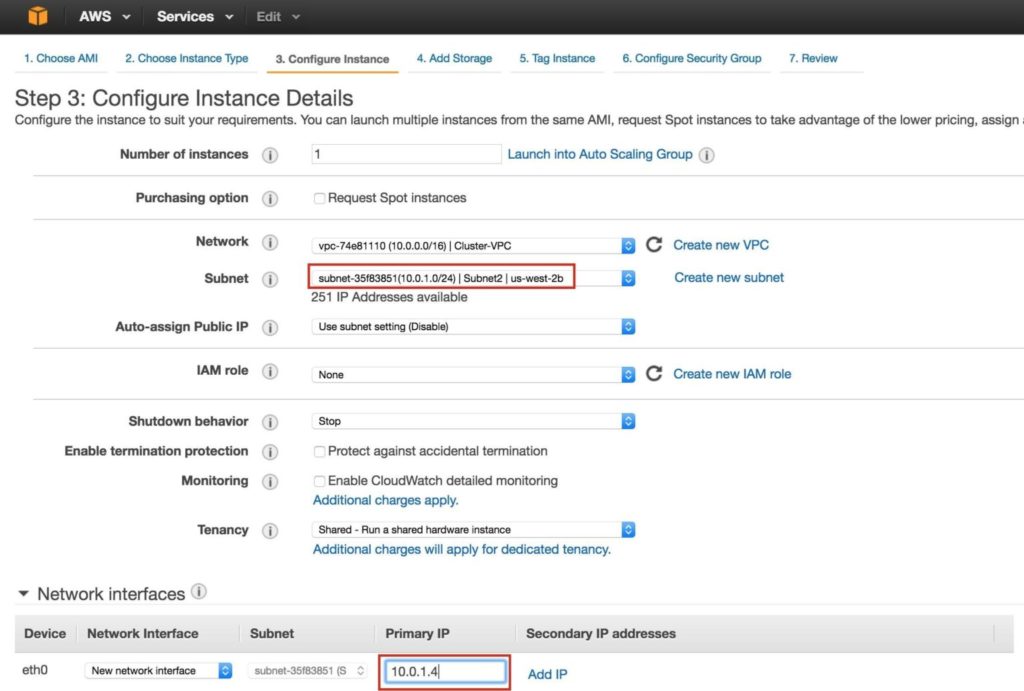
Native to the SIOS Protection Suite for Linux (SPS-L) is a tool called lkbackup, located under /opt/LifeKeeper/bin/lkbackup. The tool, as the name might suggest, creates a backup of the SPS-L configuration details. Note: This tool does not backup all of the application data, but it does create a backup of all the data for the SPS-L configuration such as: resource definitions, tunables configured in the /etc/default/LifeKeeper file, customer created generic application scripts, flags associated with the state of the cluster, communication path/cluster definitions, and more.
[root@baymax ~ ] # /opt/LifeKeeper/bin/lkbackup -c -f /root/mylkbackup-5.15.2020-v9.4.1 –cluster –ssh
Example: : lkbackup create syntax
This creates a backup file named mylkbackup-5.15.2020-v9.4.1 under the /root folder. The –cluster tells lkbackup to create the same file on each cluster node. The –ssh uses ssh protocol to connect to each cluster node. Additional lkbackup details are here:
Our Customer Experience Services Team recommends taking a backup before making SPS-L configuration changes, such as upgrades, resource removal or addition, or configuration changes.
So when you need to restore the SPS-L configuration, the change is as simple as running lkbackup again.
[root@baymax ~ ] # /opt/LifeKeeper/bin/lkbackup -x -f /root/mylkbackup-5.15.2020-v9.4.1 –cluster –ssh
Example: lkbackup restore syntax
Autobackup Feature Automatically Captures a lkbackup File
But, what do you do if you forgot to run lkbackup to create this file before your “Random Coworker” blundered away hours of SPS-L setup and configuration? What do you do if the “Guy” or “Gal” who set up SPS-L is on vacation, paternity or maternity leave? What if you are the “Random Coworker” and Steve from the Basis Team is heading down the hallway to see how things are going? For most installations, SIOS enables an autobackup feature during the installation. This autobackup feature will automatically capture a lkbackup file for you at 3am local time, under /opt/LifeKeeper/config/auto-backup.#.tgz
[root@baymax ~]# ls -ltr /opt/LifeKeeper/config/auto-backup.*
-
- -rw-r–r–. 1 root root 31312 May 6 03:00 /opt/LifeKeeper/config/auto-backup.3.tgz
-
- -rw-r–r–. 1 root root 31310 May 7 03:00 /opt/LifeKeeper/config/auto-backup.4.tgz
- -rw-r–r–. 1 root root 31284 May 8 03:00 /opt/LifeKeeper/config/auto-backup.5.tgz
- -rw-r–r–. 1 root root 31290 May 9 03:00 /opt/LifeKeeper/config/auto-backup.6.tgz
- -rw-r–r–. 1 root root 31291 May 10 03:00 /opt/LifeKeeper/config/auto-backup.7.tgz
- -rw-r–r–. 1 root root 31295 May 11 03:00 /opt/LifeKeeper/config/auto-backup.8.tgz
- -rw-r–r–. 1 root root 31280 May 12 03:00 /opt/LifeKeeper/config/auto-backup.9.tgz
- -rw-r–r–. 1 root root 31333 May 13 03:00 /opt/LifeKeeper/config/auto-backup.0.tgz
- -rw-r–r–. 1 root root 31325 May 14 03:00 /opt/LifeKeeper/config/auto-backup.1.tgz
- -rw-r–r–. 1 root root 31359 May 15 03:00 /opt/LifeKeeper/config/auto-backup.2.tgz
Example. Output from config/auto-backup listing
If your system has been installed and configured properly, the autobackups have been running each night, ready to cover you when your “Random Coworker” strikes. Find the SPS-L auto-backup.#.tgz before the blunder, and using the SPS-L lkbackup tool, retrieve and restore your SIOS Protection Suite for Linux Configuration to the previously configured state.
[root@baymax ~ ] # lkstop; /opt/LifeKeeper/bin/lkbackup -c -f /opt/LifeKeeper/config/auto-backup.0.tgz
Example: lkbackup restore syntax for auto-backup
Repeat this on the other nodes in the cluster as required.
Note. If your system doesn’t appear to be configured to generate the auto-backup files and protect you from your own “Random Coworker”, SIOS offers installation and configuration services, and configuration health checks performed by a SIOS Professional Services Engineer.
— Cassius Rhue, VP, Customer Experience
Reproduced with permission from SIOS