Why is AWS EC2 Application Monitoring So Hard?
Congratulations! You’ve migrated your core applications to the AWS cloud. Or, you are developing new “cloud-native” applications and hosting them in the cloud. Perhaps you are taking advantage of Amazon EC2’s scalability and its elastic architecture. Either way, you now want to ensure that those applications stay up and running, or that you are alerted quickly if and when something happens.
Because something will happen. Our customer data shows that companies using only three EC2 instances experience downtime at least once a month. That means unhappy users unable to access their applications. You need a monitoring solution to tell you what’s going on.
How to narrow down EC2 application monitoring solutions
The first step in your search for the perfect EC2 monitoring solution should be to understand your requirements and your own technical capabilities. Monitoring solutions are not all alike.
Are you interested in a feature-rich solution that monitors a wide array of systems? Or one that focuses on a core set of systems, such as your EC2 environment?
What do you want to do with the output from your application monitoring solution? Do you want as much information as possible to help your developers’ troubleshoot issues? Or are you looking for quick alerts and assistance in remediating from any failures?
And what is your technical appetite to install and manage another application? Do you love scripting? Or do you want something that is “set-it-and-forget-it”?
A search for “application performance monitoring solutions” on Google returns 1,170,000,000 results! Jump into the Amazon AWS Marketplace and you’ll find 453 products listed in the DevOps – Monitoring category. Having a clear sense of your requirements and your own technical capabilities will help you narrow down your search.
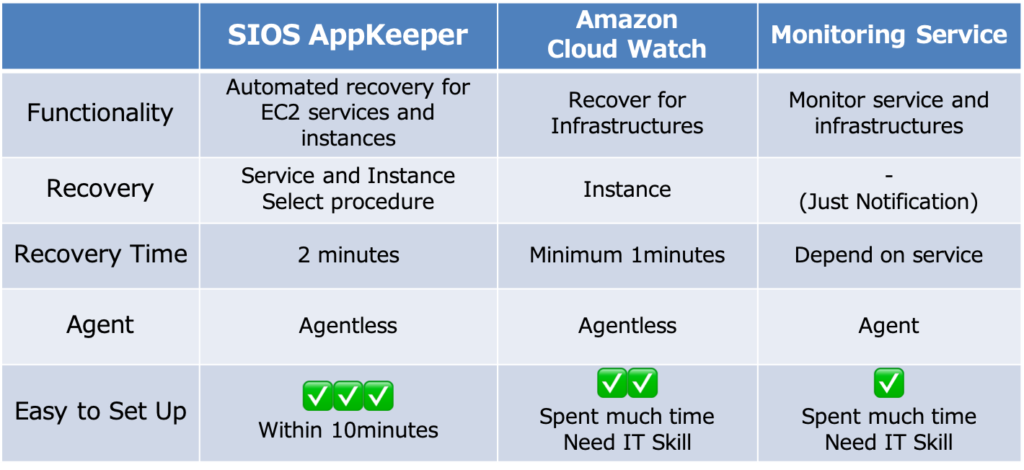
Monitoring applications running on Amazon EC2 with Amazon CloudWatch or other APM solutions
If you are hosting your applications on Amazon EC2, then you might consider using Amazon CloudWatch. How familiar are you with standard and custom metrics? You should know that you need quite a lot of technical expertise to run Amazon CloudWatch properly. Amazon CloudWatch is a great solution for users who need data and actionable insights to respond to system-wide performance changes, optimize resources and a unified view of their operational health. But this all comes at a price in terms of the knowledge and experience needed to configure and manage Amazon CloudWatch properly.
Another choice is for you to evaluate and acquire one of the many commercially available application performance monitoring (“APM”) solutions on the market, such as from AppDynamics, Datadog, Dynatrace, or New Relic. But keep in mind your requirements. How broadly do you need to monitor? And what do you intend to do with that information? Are you ready to be overwhelmed with alerts? And be aware that many APM solutions do nothing to help you recover beyond pinpointing the issue. You still have to drop everything to manually restart services or reboot your instances.
Monitor applications running on Amazon EC2 using SIOS AppKeeper
But there is another way. SIOS AppKeeper is a SaaS service that can be configured to automatically discover any EC2 instances and their services. It then automatically take any number of actions if and when downtime is experienced. So instead of getting alerts that something is wrong, you get notified that something happened and was automatically addressed.
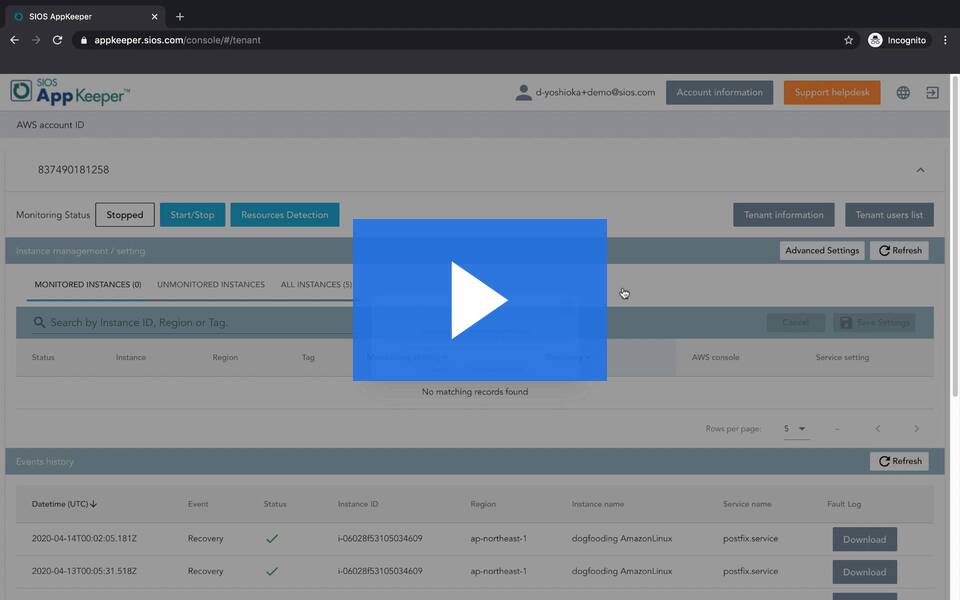
SIOS AppKeeper starts at only US $40 per instance per month. We invite you to view this short video to see how easy it is to install and use AppKeeper.
Why is AWS EC2 Application Monitoring So Hard?
One of our customers, Hobby Japan, a publishing company in Tokyo, was initially using Amazon CloudWatch but their understaffed IT team couldn’t respond fast enough to alerts. They wanted to leverage automation and moved to SIOS AppKeeper. Since moving to AppKeeper they haven’t experienced any issues or unexpected downtime with their EC2 instance. Here’s a link to a case study on Hobby Japan.
Monitoring your cloud applications shouldn’t be a full-time job. You want a monitoring solution that is easy to install and use, doesn’t overwhelm you with alerts, and hopefully takes care of systems impairments automatically. We encourage you to try a 14-day free trial of SIOS AppKeeper by signing up here.
Article reproduced with permission from SIOS



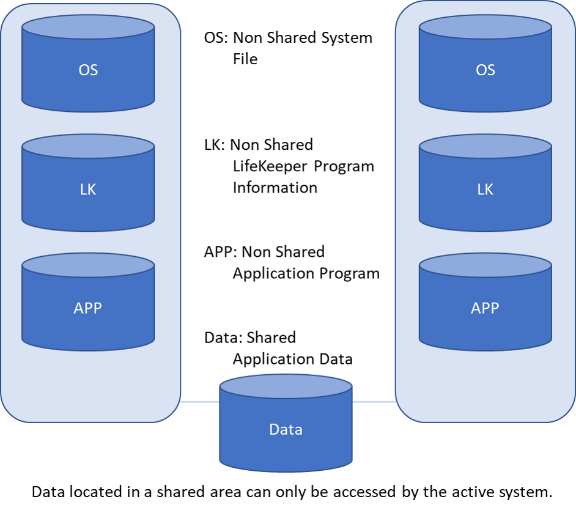
 High Availability Software is Insurance Against SAP Downtime
High Availability Software is Insurance Against SAP Downtime