
Lessons in Cloud High Availability from the Movies
Joseph Lalonde of jmlalonde.com has a blog highlighting the leadership lessons from popular movies such as Hancock, The Greatest Showman, and Frozen II. In credit to Joseph’s inspiring leadership lessons, here are four high availability lessons on cloud migration from Disney’s Frozen II.
Disney’s Frozen II and Cloud Migration Lessons
In Disney’s animated adventure Frozen II the characters Anna, Elsa, Kristoff, Olaf and Sven leave Arendelle to travel to an ancient, autumn-bound forest of an enchanted land. In the adventure, they set out to find the origin of Elsa’s powers in order to save their kingdom. Aside from being fun for a father of six girls, the movie is also ripe with leadership, life, and high availability lessons.
1. You can’t go into cloud migration without the proper help.
When Elsa, Anna, Kristoff, Olaf and Sven arrive at the place where the mysterious voice has been calling them, they stand outside an enormous cloud. When Olaf and Kristoff attempt to enter, they are bounced back and repelled. It is only when Elsa approaches the cloud with her magic that the portal opens and they enter.
When migrating to the cloud, there will be a lot of voices calling you. Some will beckon you to AWS, or Azure or GCP, or a myriad of others. But, no matter which you intend to go with, know that you will need the proper help for a successful entry. This help should include:
- Architects knowledgeable of the platform, especially the networking aspects
- Application administrators who understand the applications installation, configuration, operation and maintenance characteristics
- Security and OS administrators
- A cloud partner representative
- A knowledgeable availability expert for deploying critical applications in highly available architecture
2. Things will not make sense when you are older, so document and iterate.
While walking through the enchanted forest, Olaf begins experiencing the strange phenomenon and magic of the forest. As he does, he begins to sing:
- This will all make sense when I am older
Someday I will see that this makes sense - One day, when I’m old and wise
- I’ll think back and realize
- That these were all completely normal events
- I’ll have all the answers when I’m older
The song concludes with the rousing finish of:
- ‘Cause when you’re older
- Absolutely everything makes sense
- This is fine
Stop. If things don’t make sense to you when you are starting out in your cloud journey, take the time to make them make sense. If you are using an agile mindset, launch an investigation spike on the singular topic or topics of confusion. For example, if you don’t understand the magic of the VPC, Security Group, Availability Zone or Set, Region, or Region to Region concepts today, they will make even less sense later down the road when you return to this configuration months later. If the test results don’t make sense, don’t move on, run them again. Also, remember to document the architecture, not just the details you think are important, but the details that the older you who have moved through six other projects and is facing a deadline would want to know to make it all make sense.
3. Don’t go running into the fire. Choose the right cloud high availability solution.
After a brush with the wind spirit, the enchanted forest is set ablaze by the fire spirit. As the fire spirit spreads chaos, and fire, Elsa charges off with icy blasts to cool the fire and calm this spirit. In her zeal, Anna runs into the fire behind her sister and has to be saved. When at last the two are reunited, Elsa admonishes her sister- “You can’t just follow me into fire”. The feisty Anna replies, “You don’t want me following you into fire? Then don’t run into fire!”
Migrating to the cloud and choosing the right availability solution for you can be stressful enough without complicating it by making unrealistic schedules with untested theories and scenarios. No leader of a deployment team wants his or her team in a fire drill, so don’t knowingly run into one. Create a plan. Establish checkpoints and milestones. Include realistic risk and risk management strategies. Communicate frequently with vendors and partners, and especially with your team. Test well, and understand backup and backout plans.
4. Don’t get stuck in the past re: what you bring in your cloud migration.
There is a song woven throughout the movie, “All is Found” with the chilling chorus – “Dive down deep into her sound / But not too far or you’ll be drowned.” Elsa dives down into the deep as the movie peaks and her search and exploration of the past leave her Frozen, her last gasp a burst of flurries to warn and inform her sister.
As one of the heads of our Customer Experience Team at SIOS Technology Corp., I have witnessed too many deployments and migrations get stuck in a comparison trap. The phrase goes like this, “In our old data center, we” or “The old system could do that.” It may be true that your old system of fixed systems, dedicated resources, large teams, specific networking, and high cost, high feature SAN storage could do that. (Although, truthfully, sometimes I’ve seen the curtain peeled back and on-premise didn’t really do that either). As you migrate to the cloud, understand what makes sense to mimic in the cloud and what doesn’t. Understand why the system was architected that way on-premises and using the help, “lesson 1, and the learning of lesson 2, make decisions that make sense.
Which leads me to the final lesson.
5. There will always be two kingdoms: on-premises and in the cloud.
At the end of the movie, Anna becomes queen of Arendelle once ruled by her sister Elsa, while Elsa stays and leads the people of the Northuldra. There is one who stays in or near the forest once surrounded by mystery and cloud, while the other returns to the familiar land.
As you consider migration to the cloud and your High Availability strategy, remember there will always be two kingdoms. Your migration strategy would do well to remember that you will always have a need for an on-premise data center to partner with your cloud deployments. Perhaps it isn’t as sprawling as it once was, but not every workload or critical infrastructure can be repurposed and packaged for the cloud. Having an HA solution and strategy that can equip and enable both “kingdoms” is essential.
Going to the cloud takes the right team, the right tools and the right solutions, and a strategy and plan to get there, without going through fire. As you migrate to the cloud, be willing to confront the past, understand it, and remember not to get stuck there. And, like the two sisters of Disney’s Frozen II, you’ll do well to remember every beautiful enterprise story has two sides, on-premise and cloud just might be yours.
— Cassius Rhue, VP, Customer Experience
Reproduced with permission from SIOS

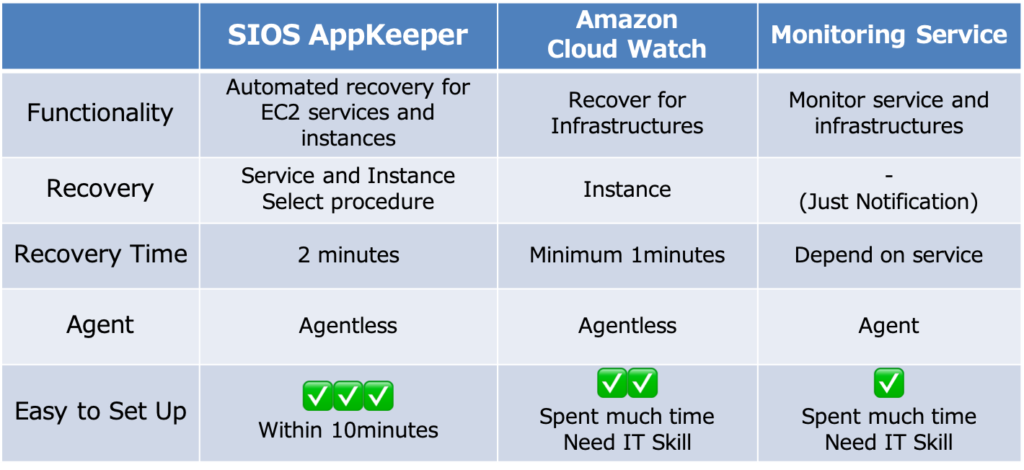



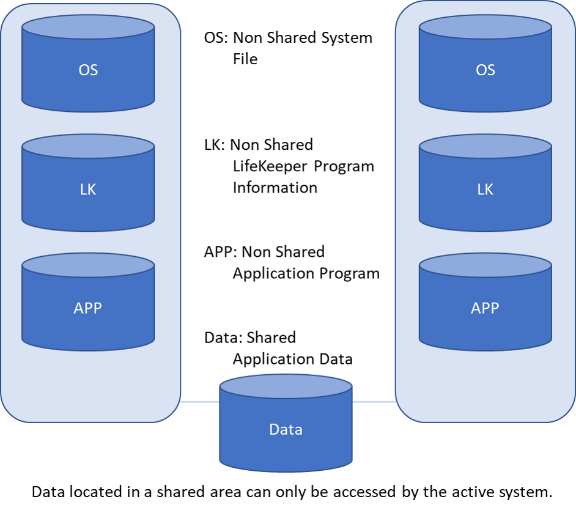
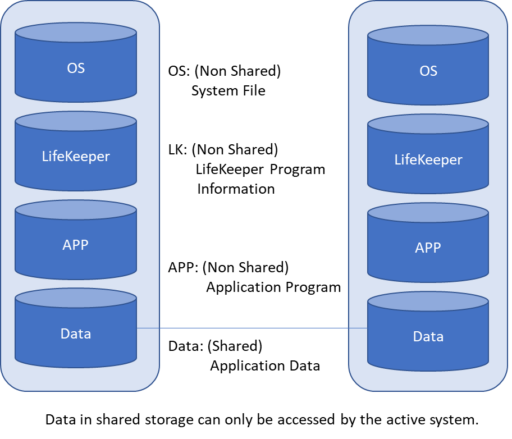
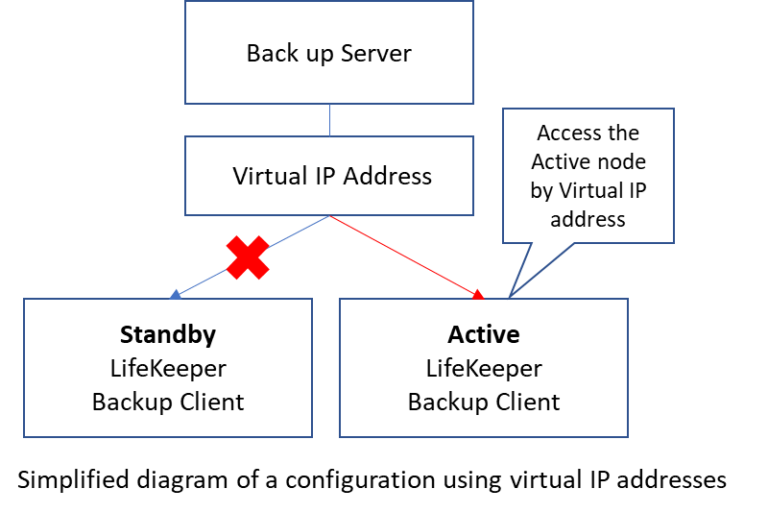
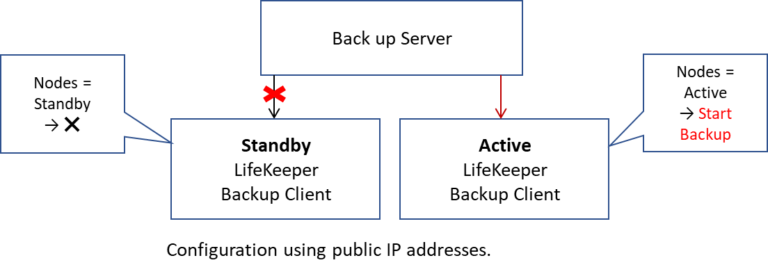
 High Availability Software is Insurance Against SAP Downtime
High Availability Software is Insurance Against SAP Downtime