Microsoft Build 2019 Pengumuman Dan Sesi Sesuai Permintaan
Ketinggalan Microsoft Build 2019 karena Anda tidak dapat pergi dari kantor untuk hadir? Anda akan senang mengetahui bahwa Microsoft telah menerbitkan semua sesi dan tersedia online tanpa biaya.

Menjadi konferensi yang berfokus pada pengembang, sebagian besar pengumuman ditujukan untuk pengembang. Anda dapat melihat daftar lengkap pengumuman yang dapat dicari di sini. https://azure.microsoft.com/en-us/updates/?updatetype=microsoft-build&Page=1
Apa itu Infrastruktur sebagai Kode?
Saya lebih dari seorang pria infrastruktur. Beberapa pengumuman yang lebih menarik bagi saya adalah sebagai berikut.
Solusi Azure VMware sekarang tersedia secara umum
Jika saya banyak berinvestasi di VMware dan ingin memperluas ke Azure, ketersediaan Solusi Azure VMware tentu akan membuka beberapa kemungkinan menarik. Sepertinya jika saya menggunakan contoh bare-metal atau contoh khusus, saya pada dasarnya dapat memiliki host ESX yang berjalan di Azure. Ini masuk akal bagi mereka yang merencanakan penyebaran cloud-hybrid dan ingin dengan mudah memindahkan beban kerja bolak-balik antara on-prem dan Azure. Tinggalkan saya komentar untuk memberi tahu saya mengapa ini menggairahkan Anda.
Azure Quickstart Center memungkinkan pelanggan baru untuk membangun proyek cloud dengan percaya diri
Saya belum melihat ini. Namun, ini terlihat SANGAT menarik bagi saya jika memang itu yang saya pikirkan. Seiring adopsi cloud terus tumbuh, demikian pula keahlian yang diperlukan dari profesional TI. Seorang profesional TI yang bijak ingin menjadi nyaman dengan Infrastruktur sebagai Kode (IaC). Hanya dua tahun yang lalu, rangkaian keterampilan ini tidak ada. Konsultan IT atau penyedia cloud yang lebih besar mungkin memiliki sedikit atau bahkan tidak memiliki pengalaman sama sekali. Selama setahun terakhir saya telah melihat keahlian ini menjadi lebih umum dengan pelanggan yang bekerja dengan saya. Ini sering merupakan metode penyebaran yang disukai. Pada saat yang sama, teknologi IaS juga telah matang. Saya memperkirakan bahwa jika Anda belum mengelola penyebaran cloud Anda dengan IaC, Anda akan berada dalam waktu dekat. Saya berharap bahwa penawaran baru dari Microsoft ini dapat menjadi pengantar yang bagus bagi para profesional TI yang ingin mendapatkan pengalaman dan pengetahuan IaC. Saya akan memposting artikel tindak lanjut setelah saya melihatnya.


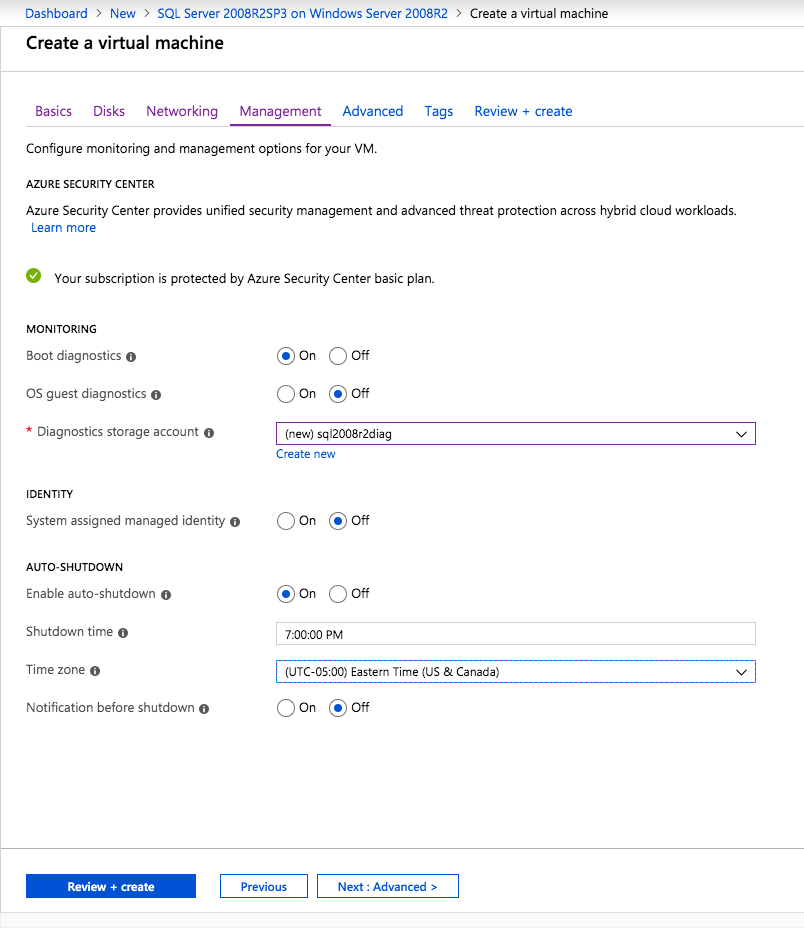
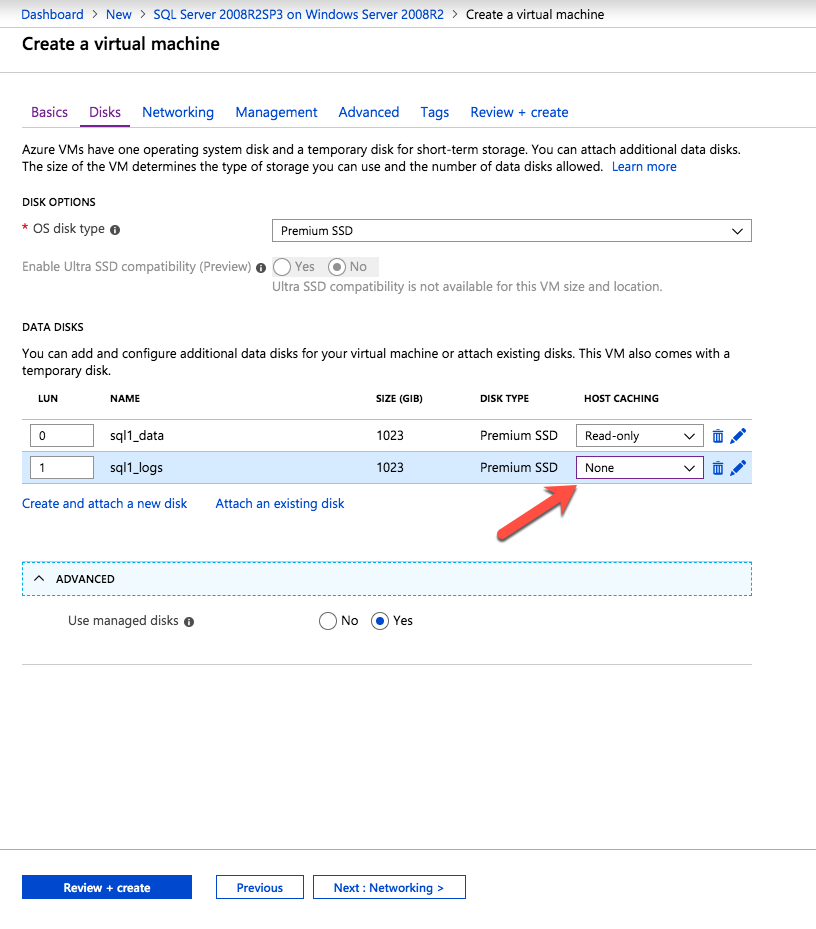
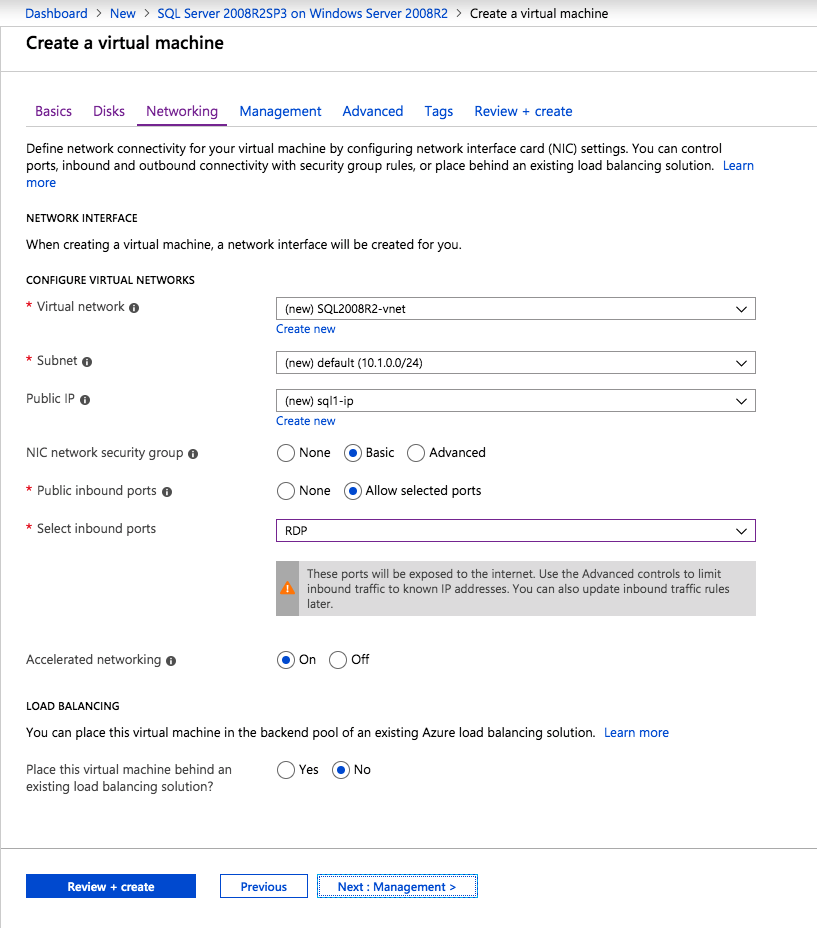
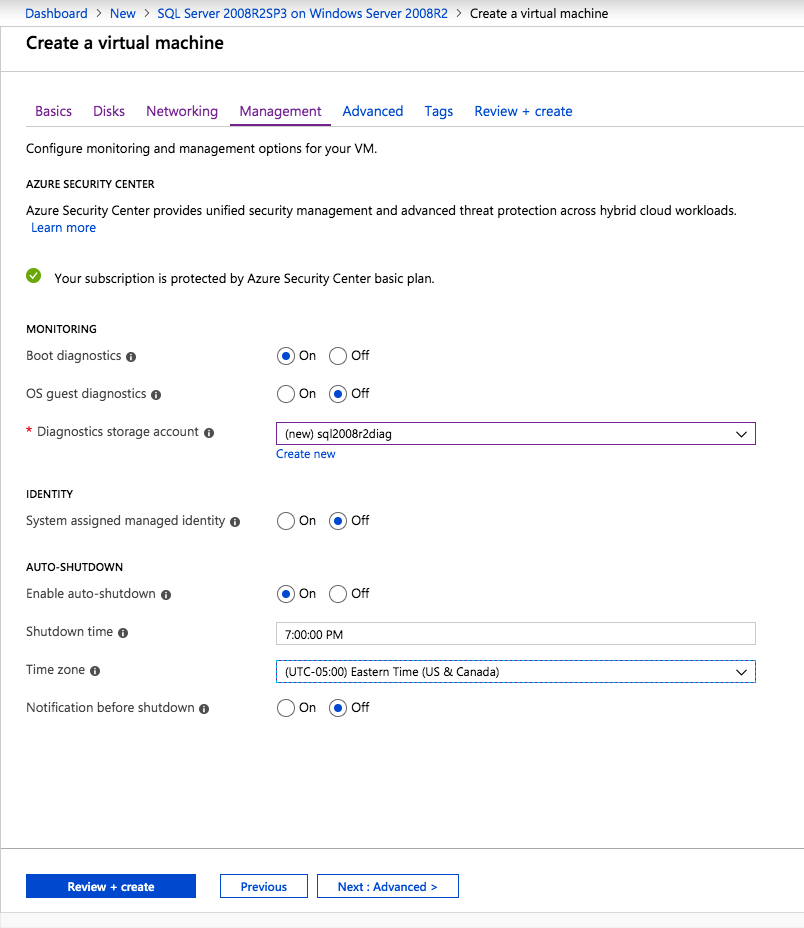
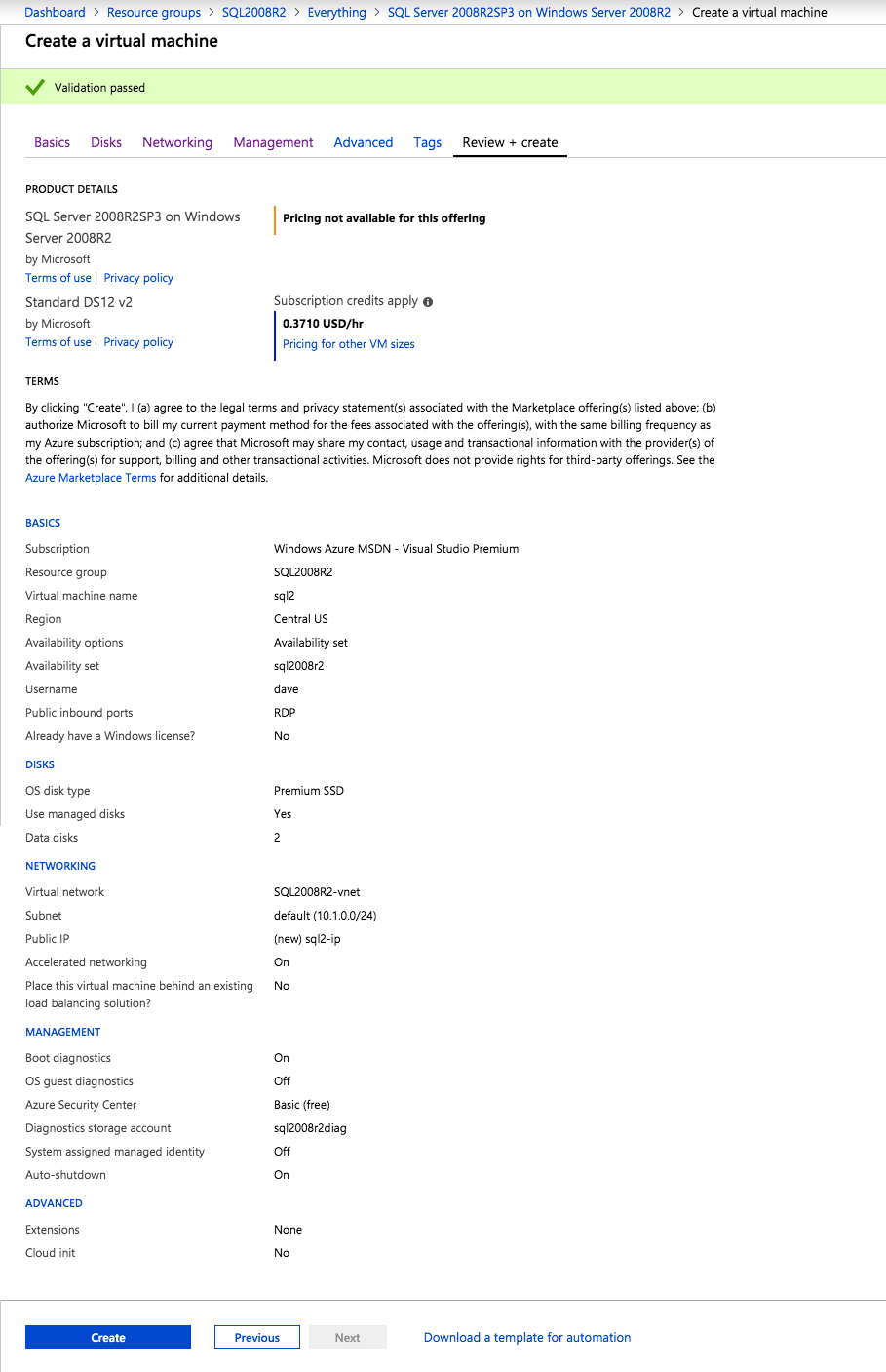
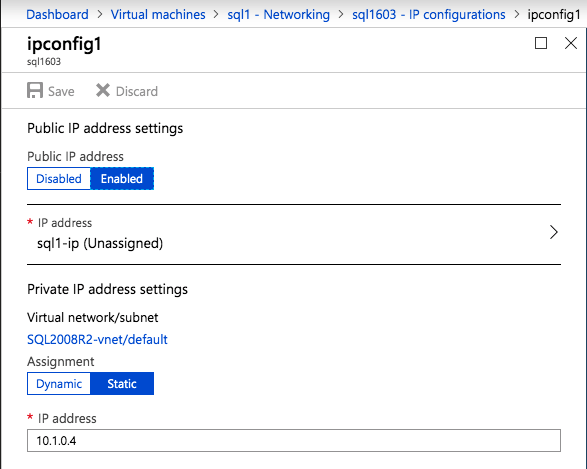
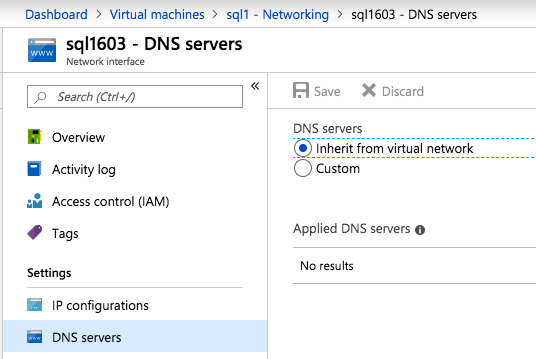
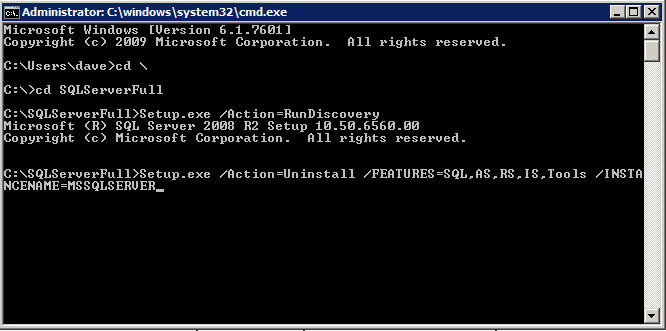

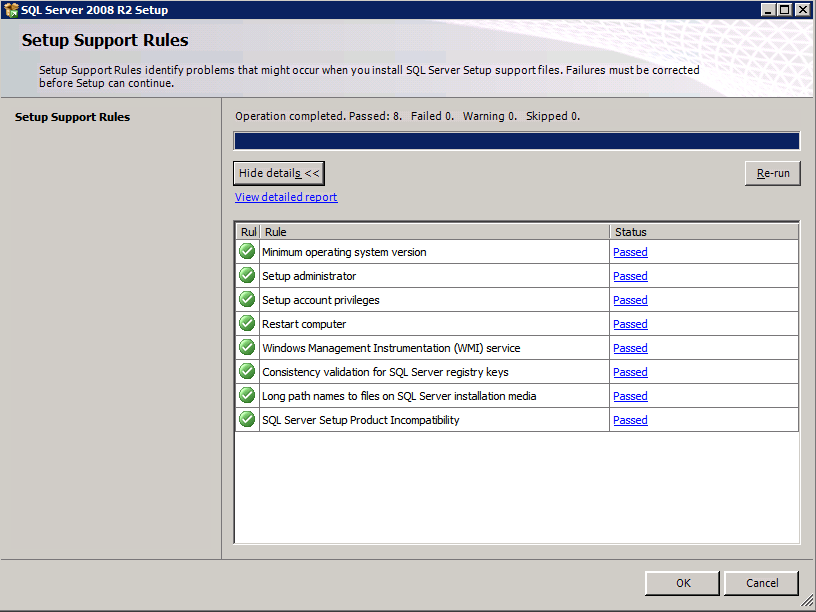
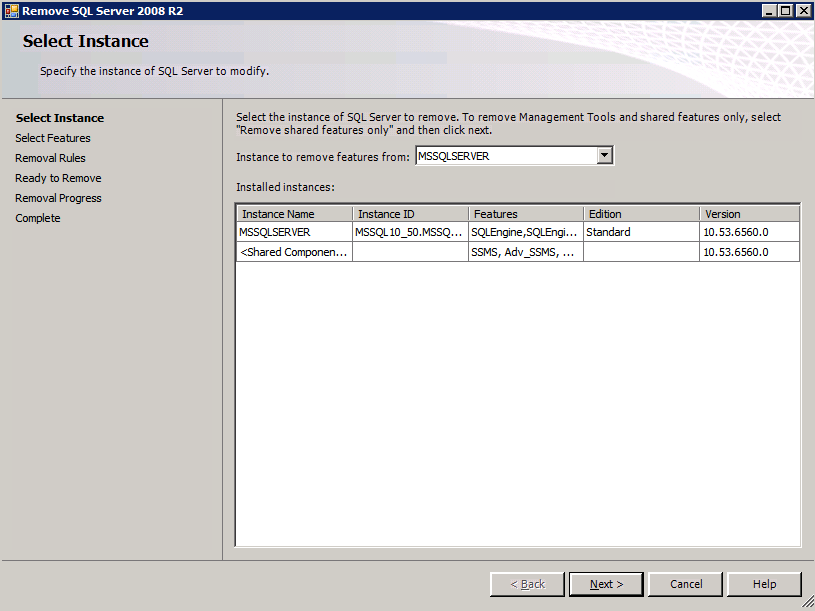
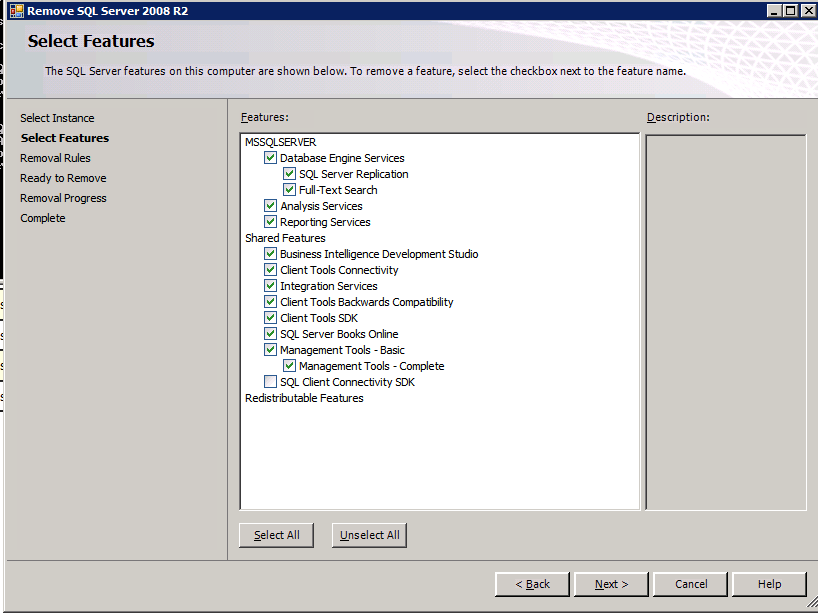
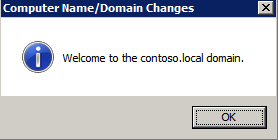
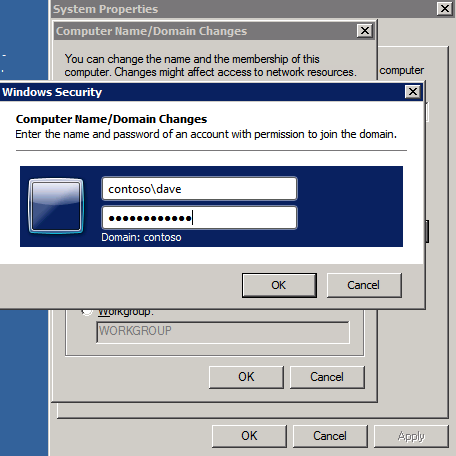
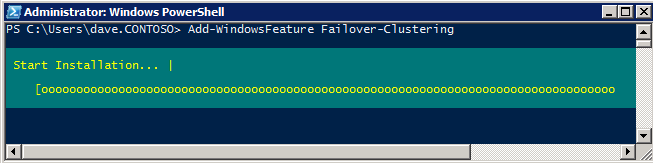
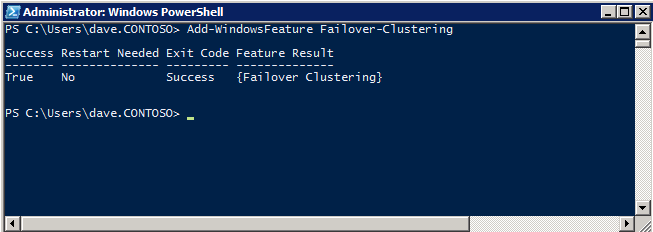
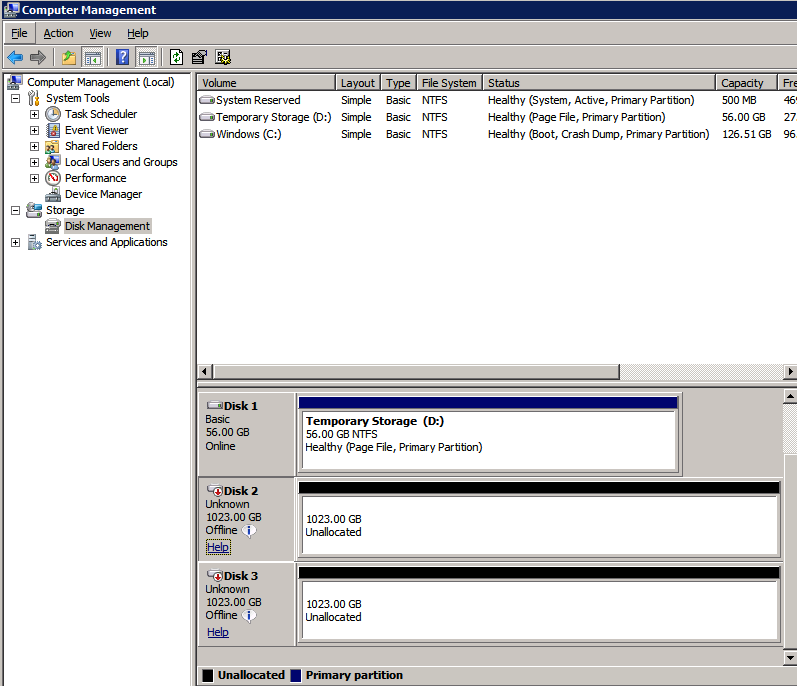
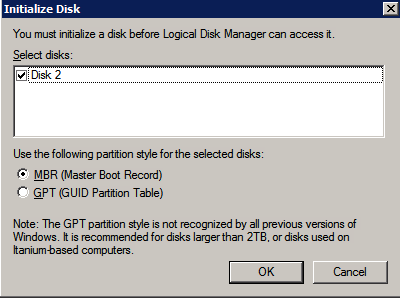
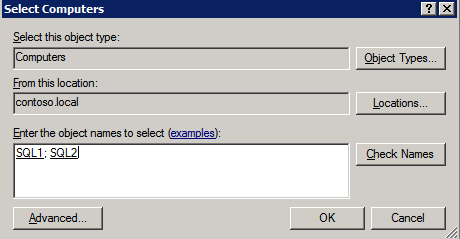
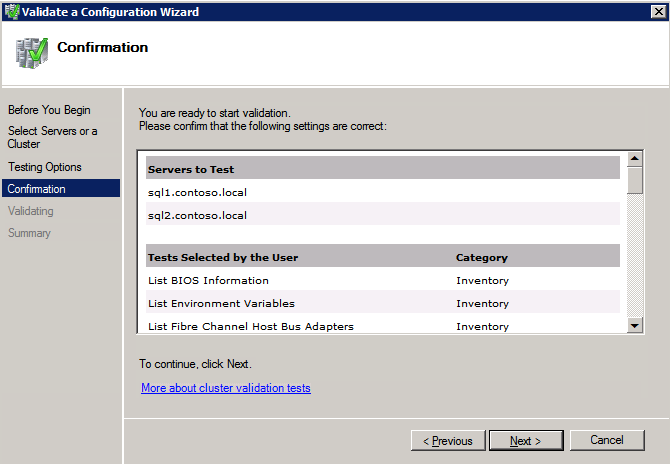
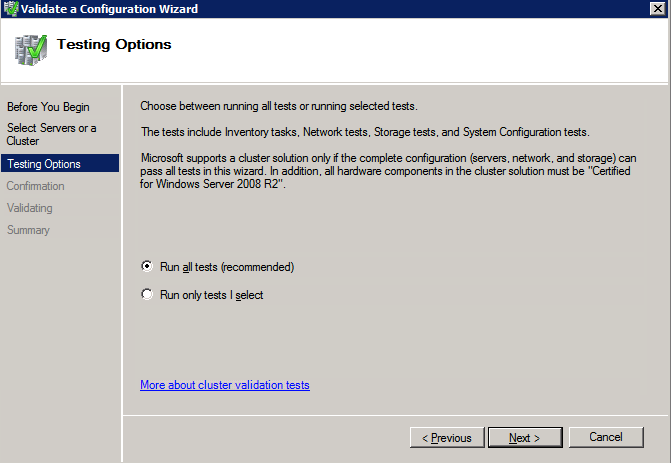
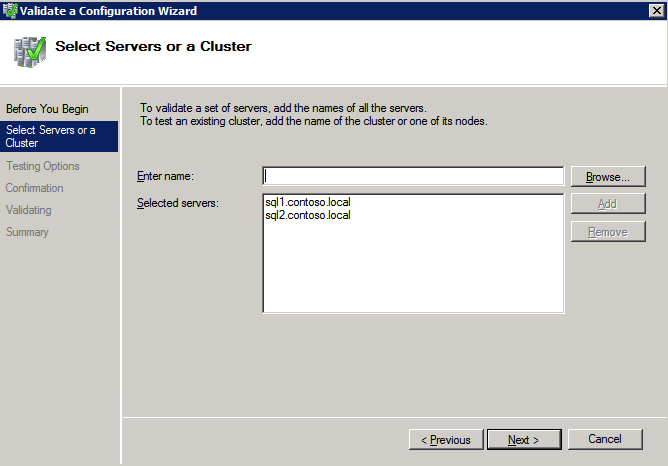
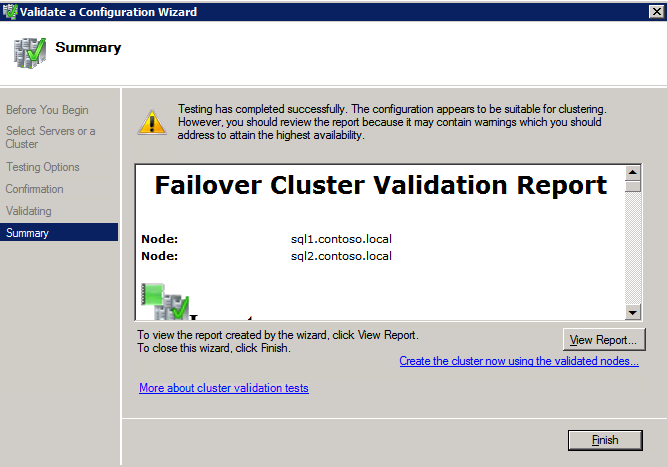
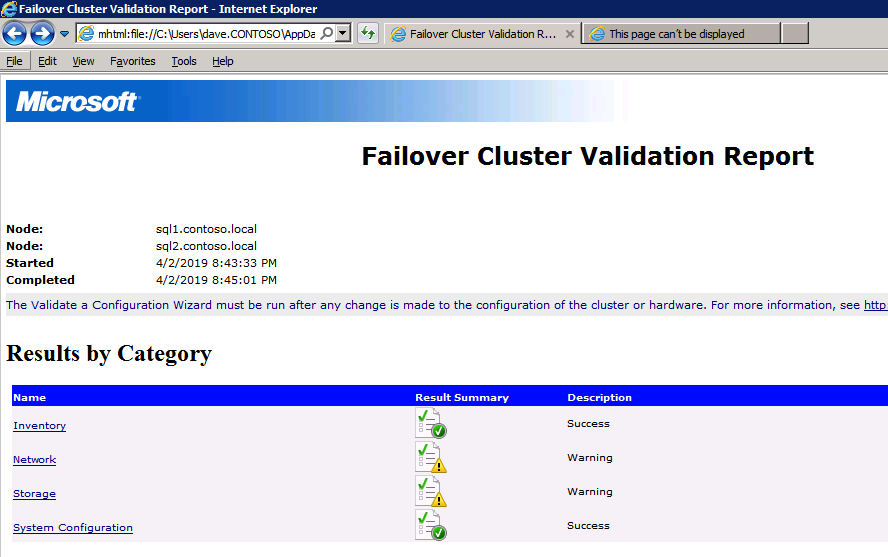
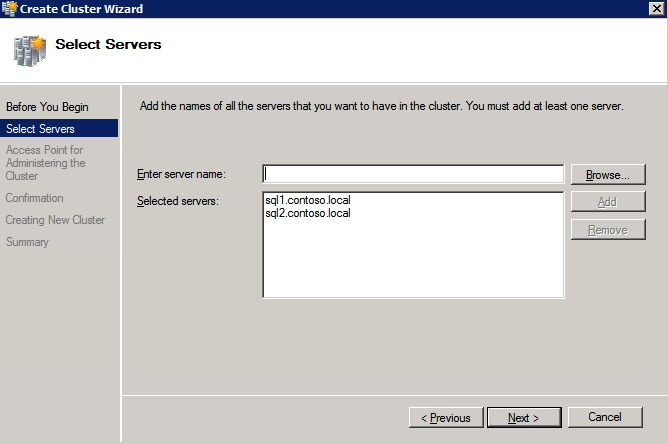
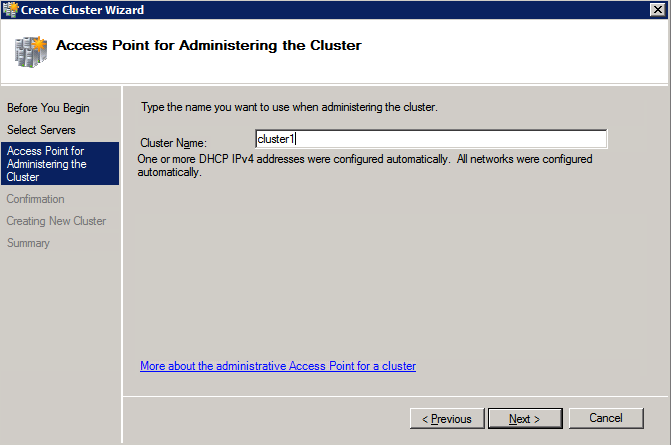
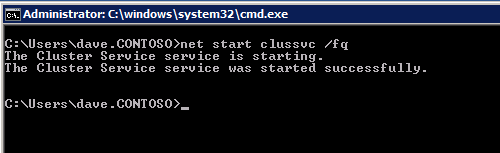
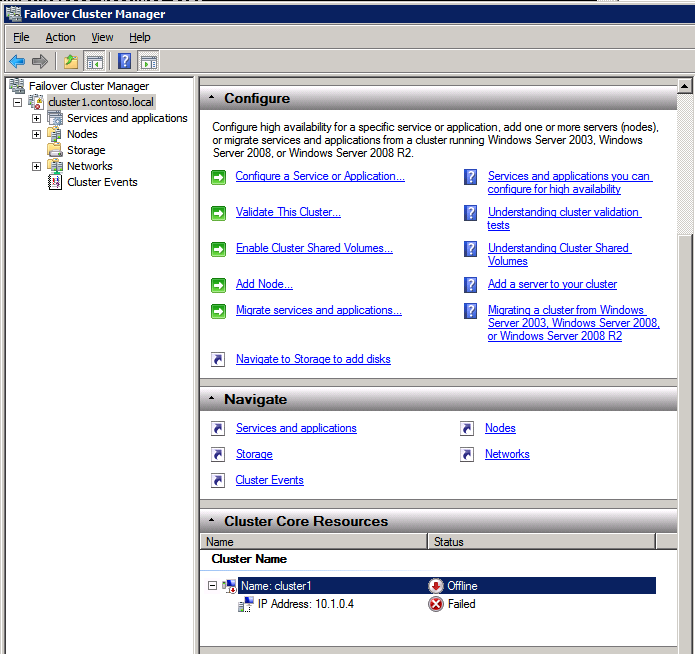
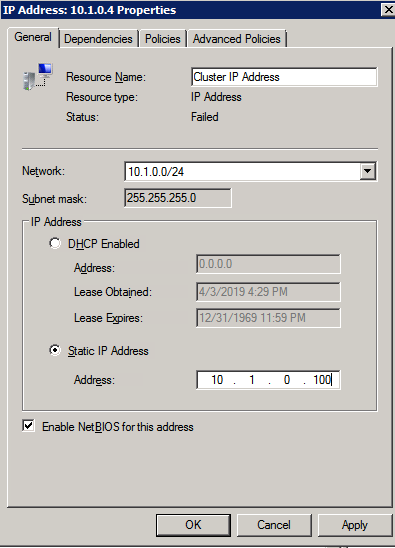
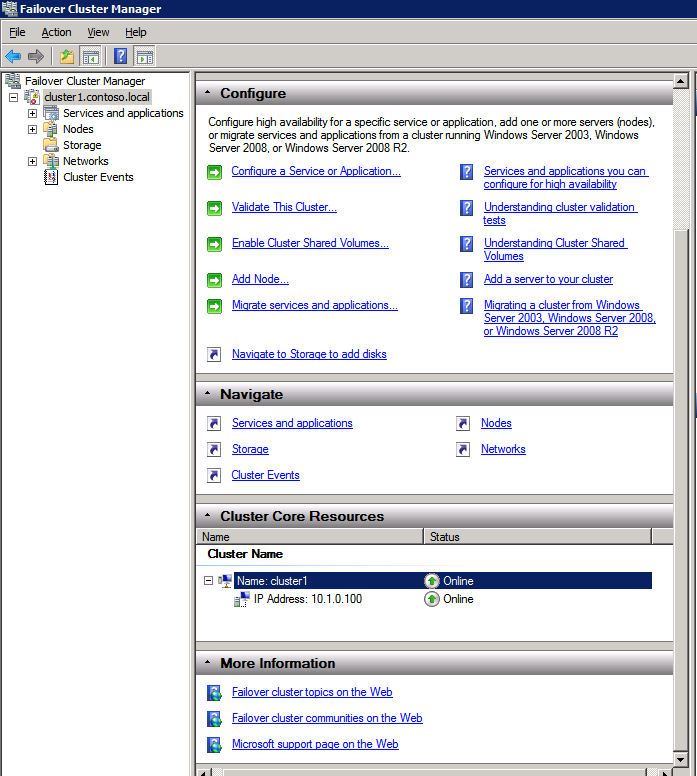
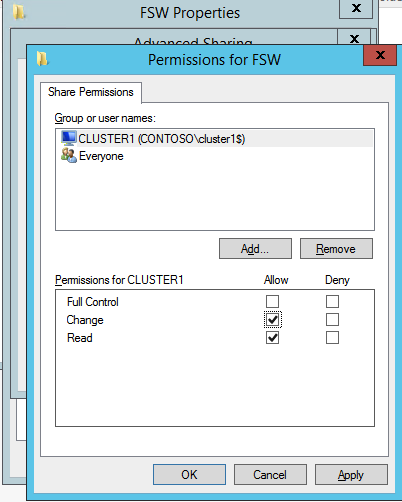
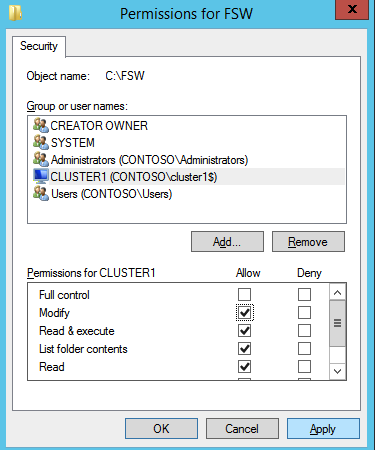
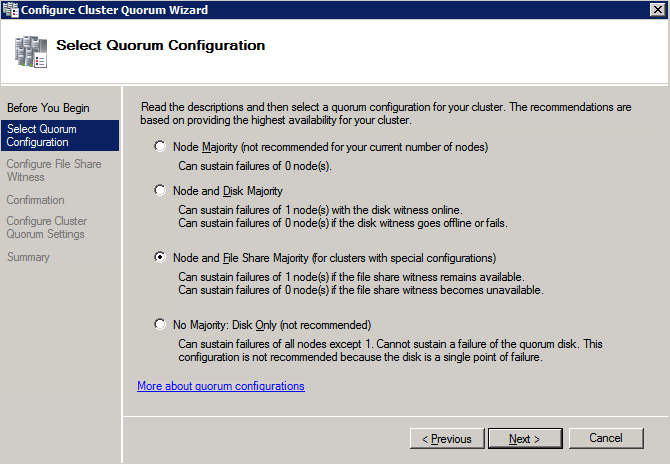
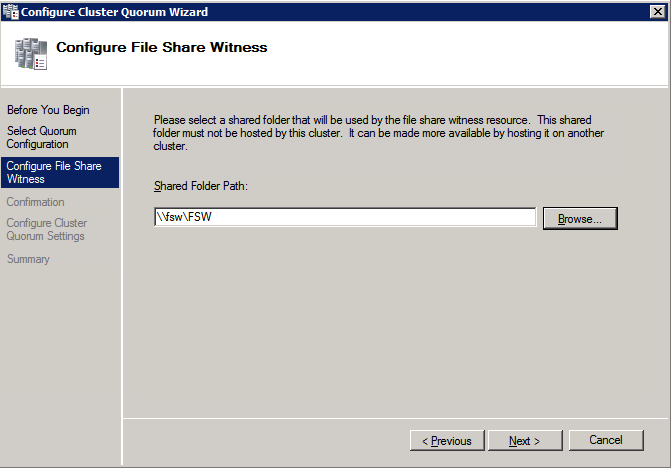
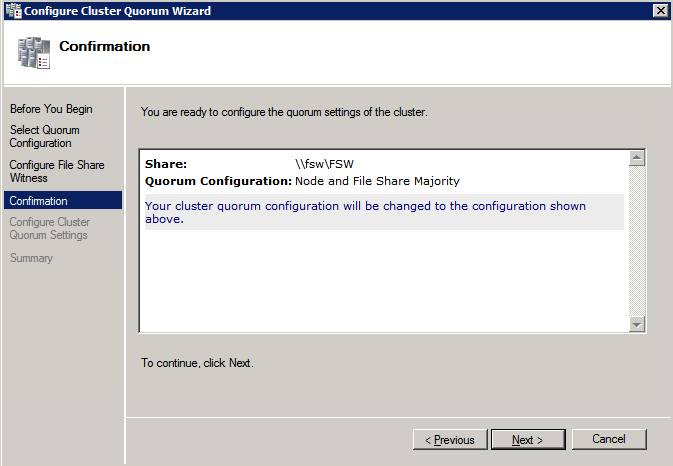
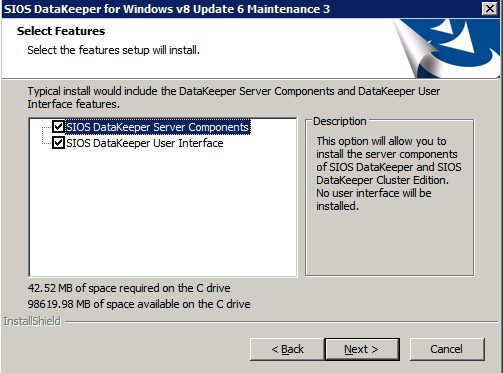
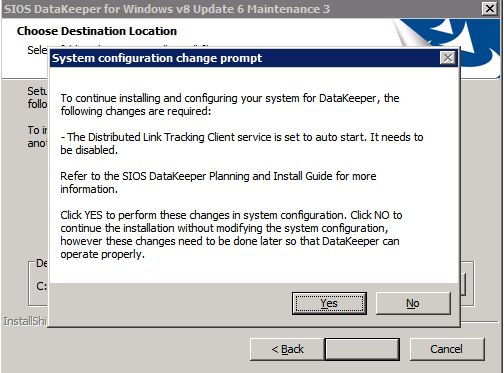
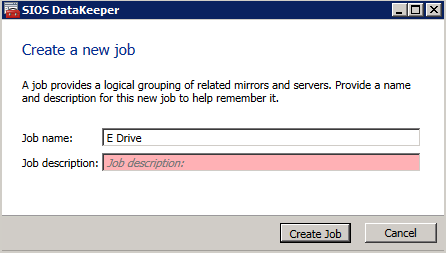
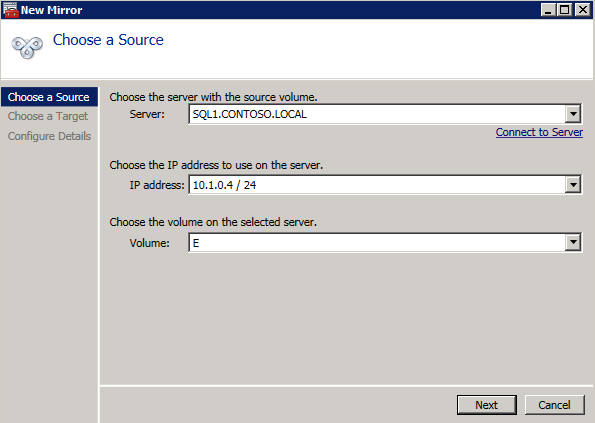
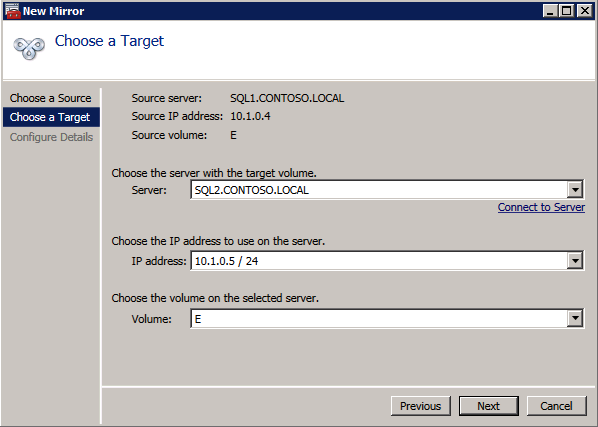
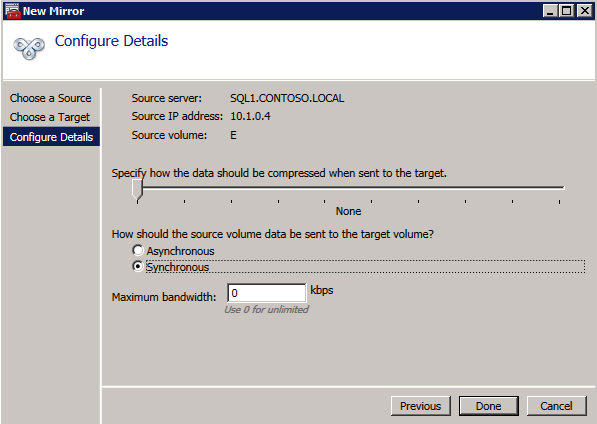
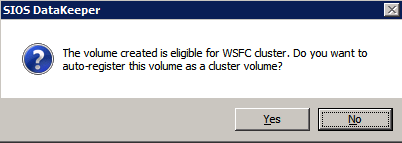
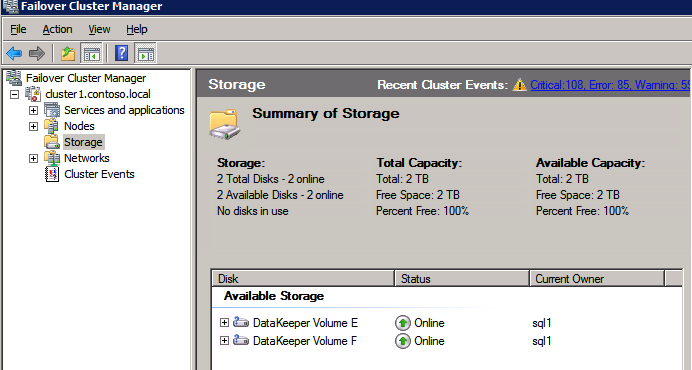
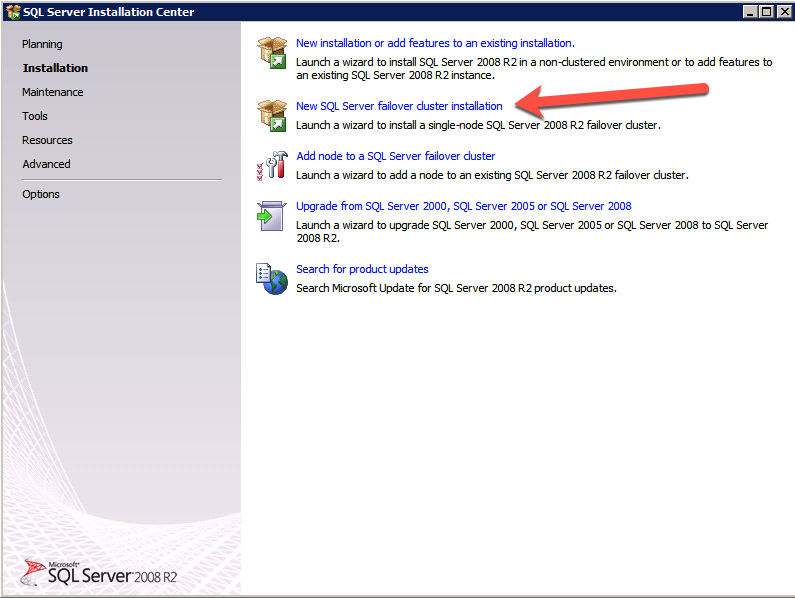
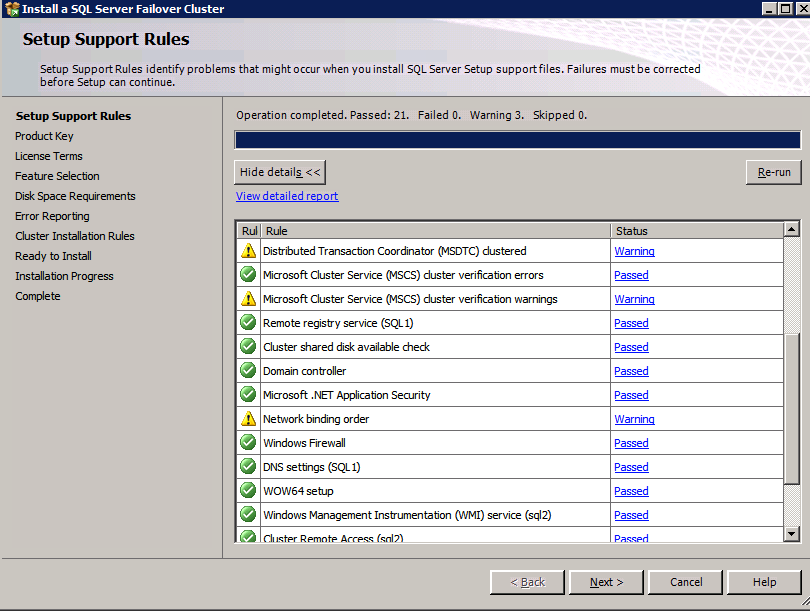
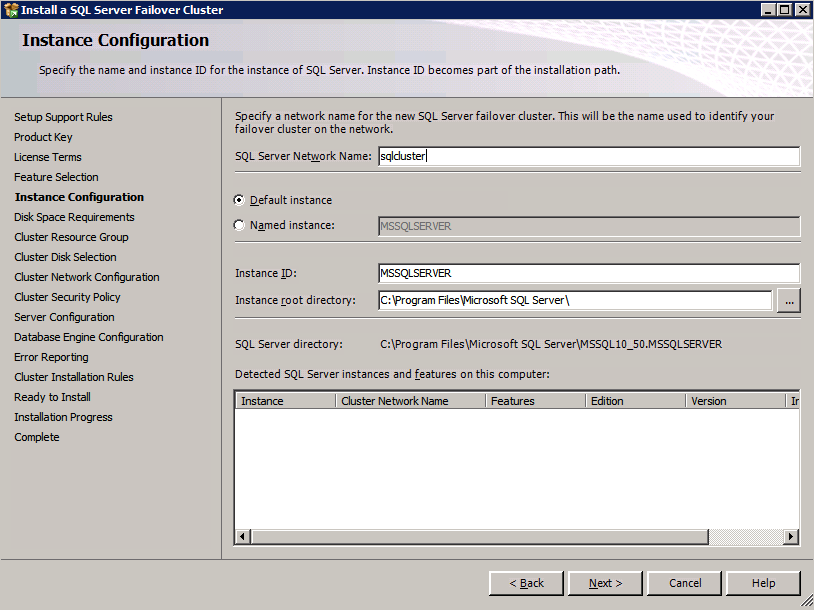
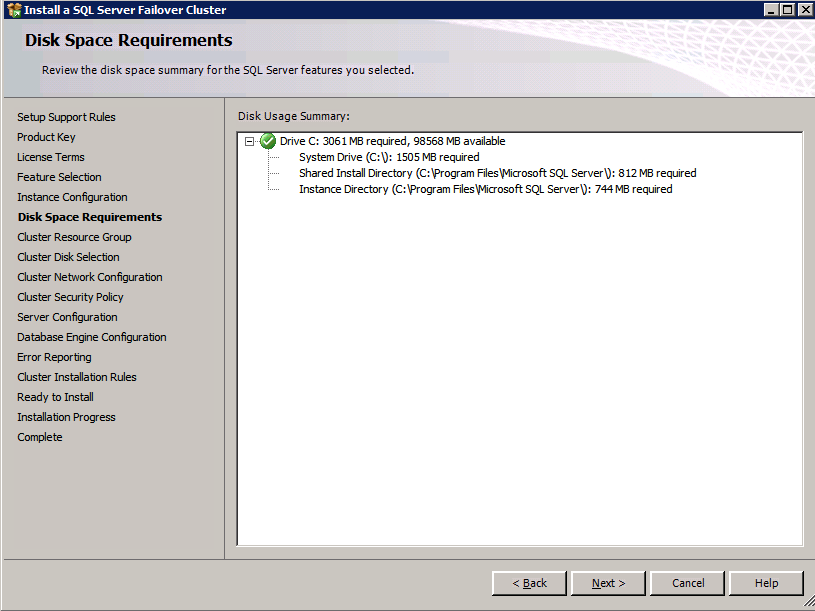
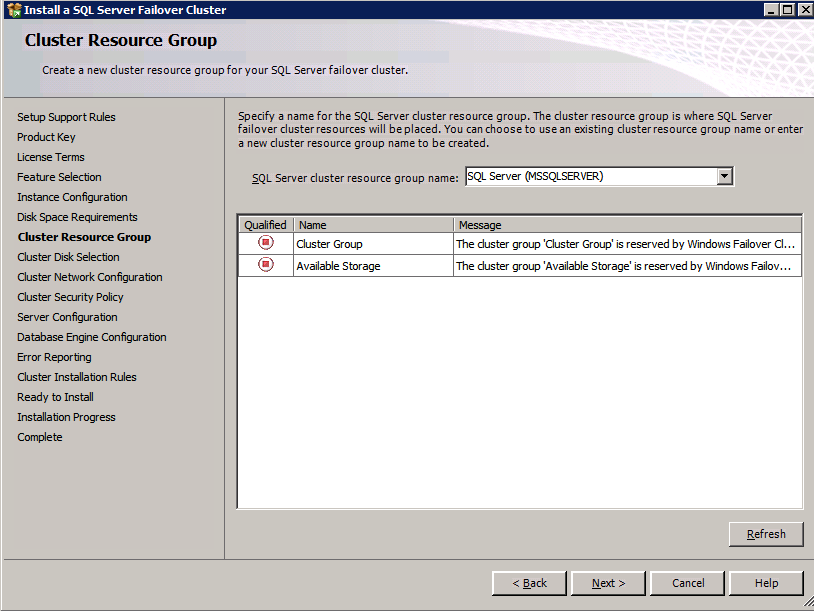
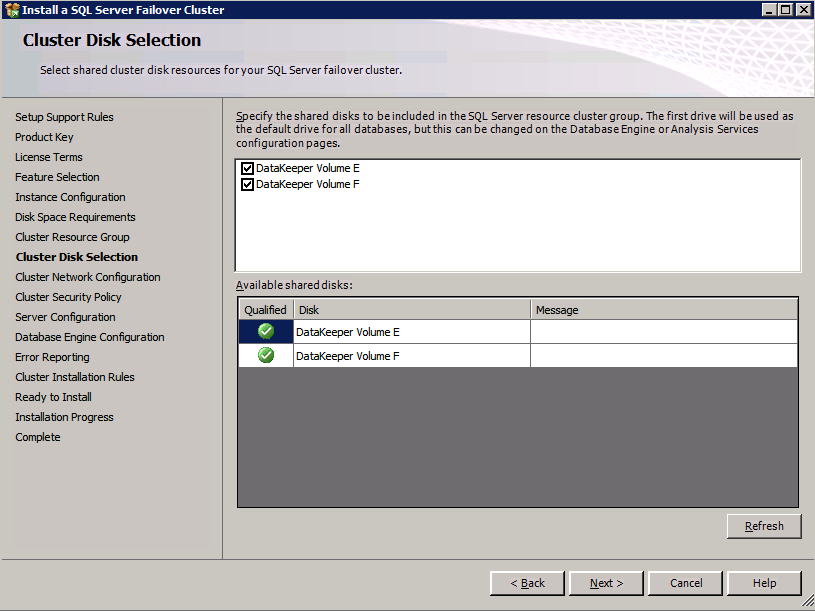
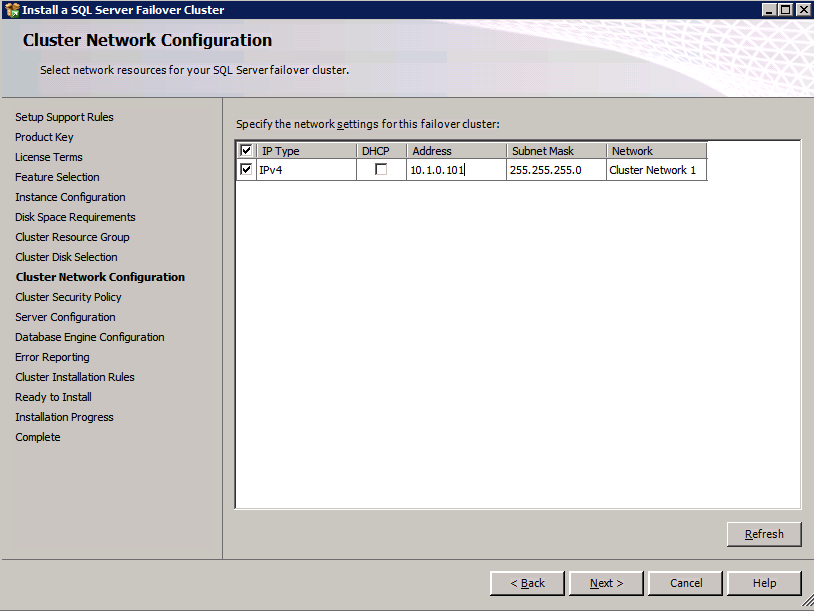
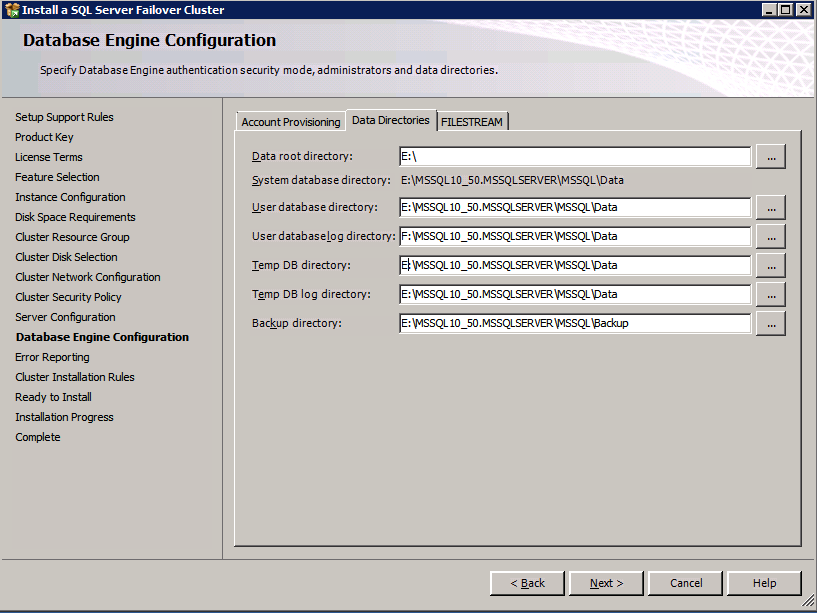
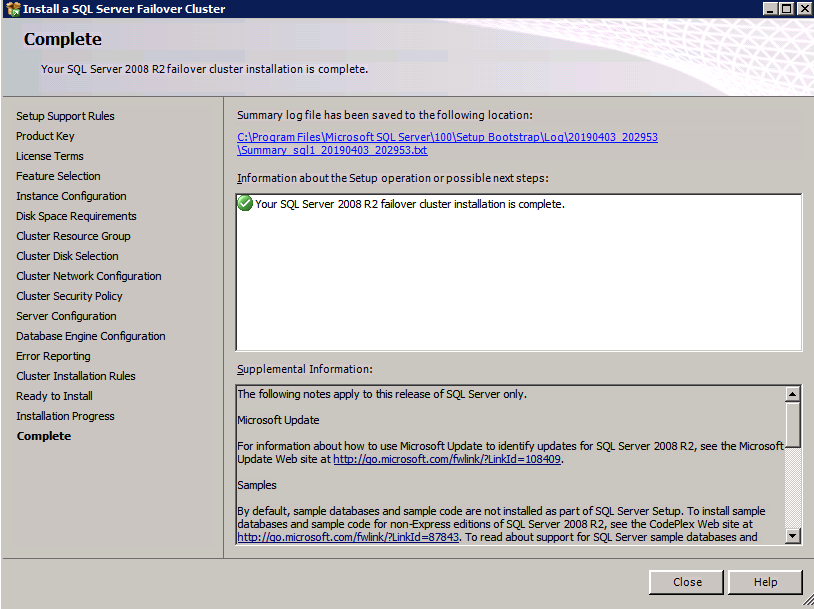
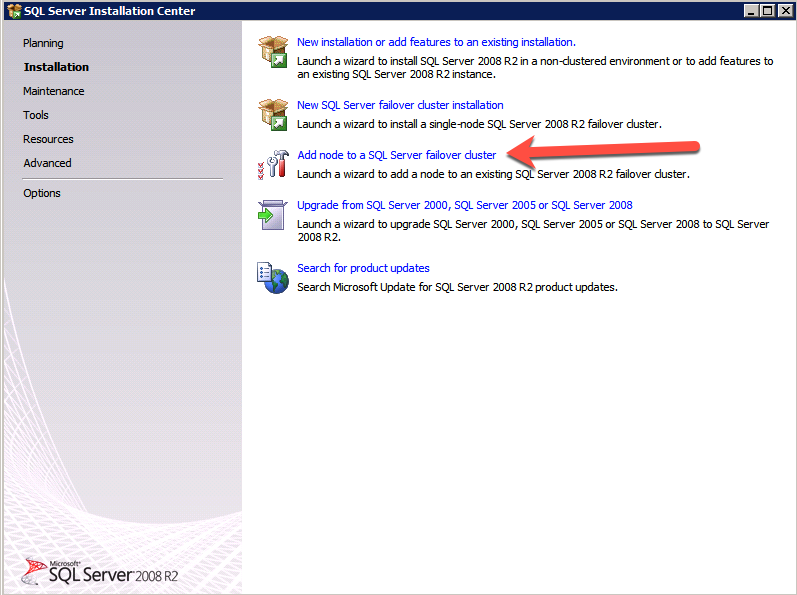
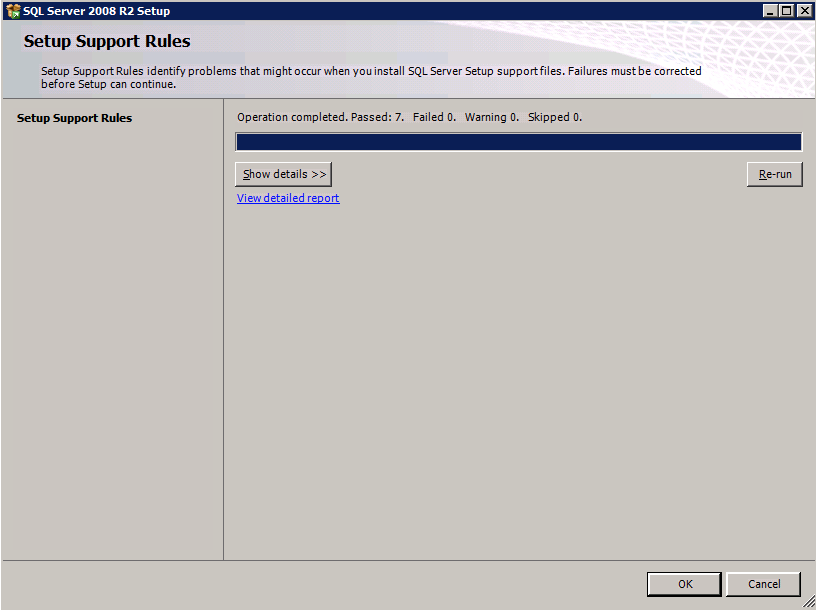
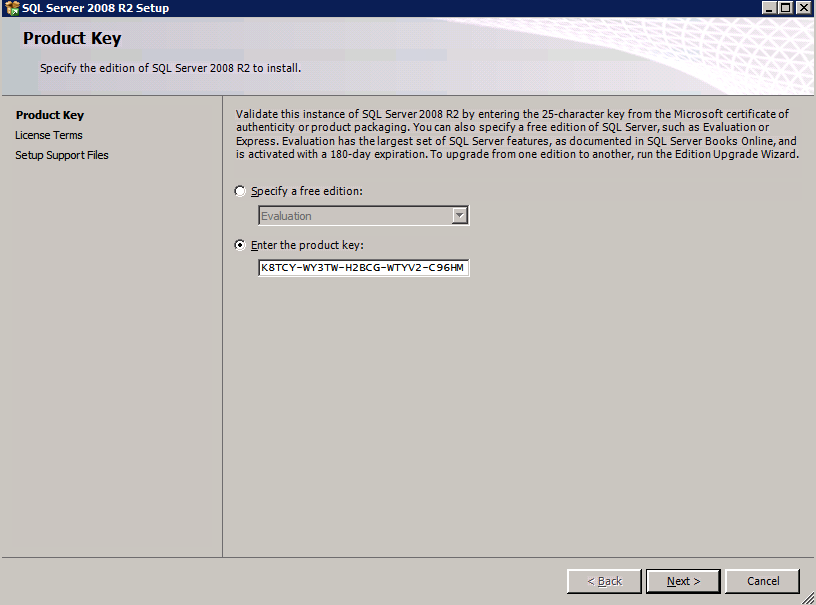
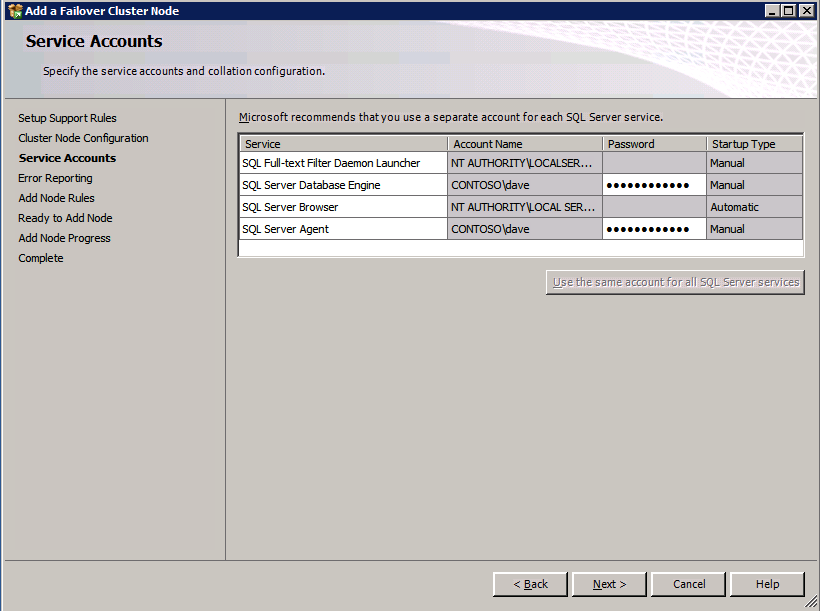
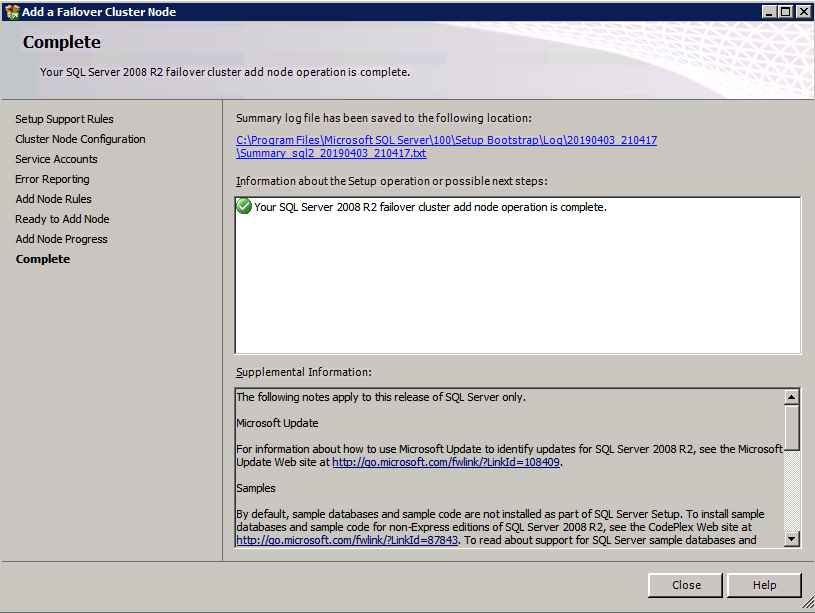
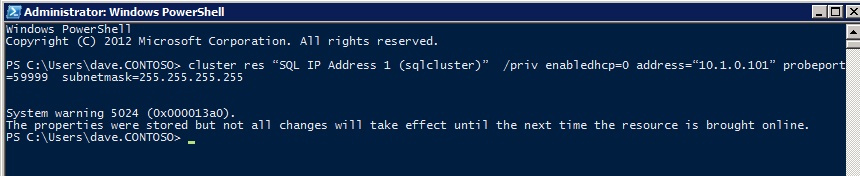
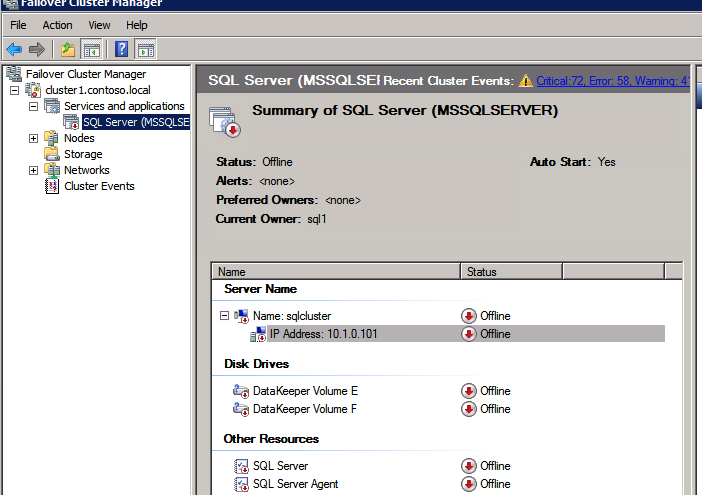
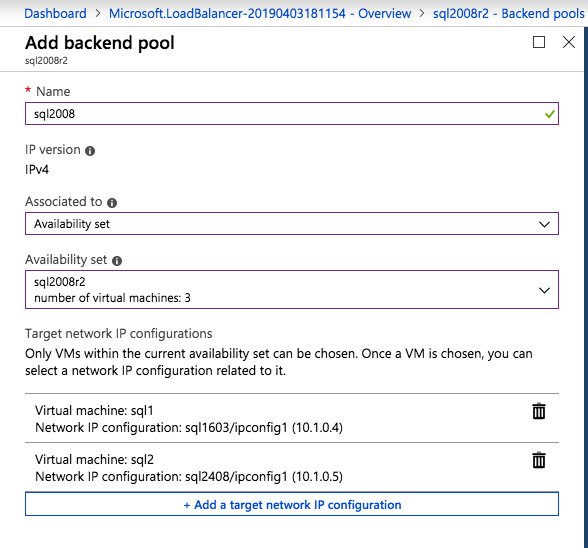
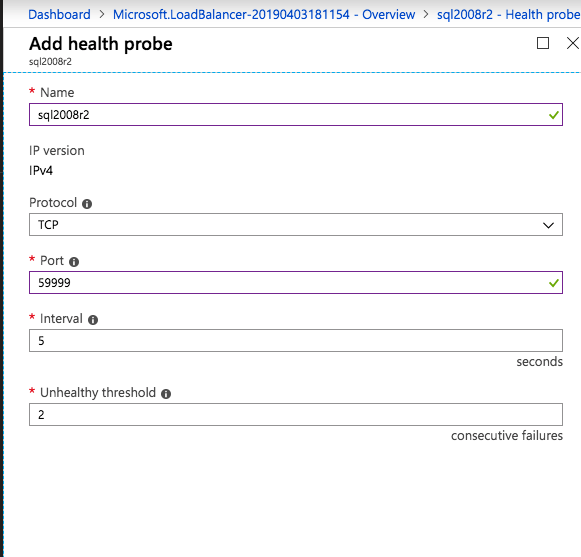
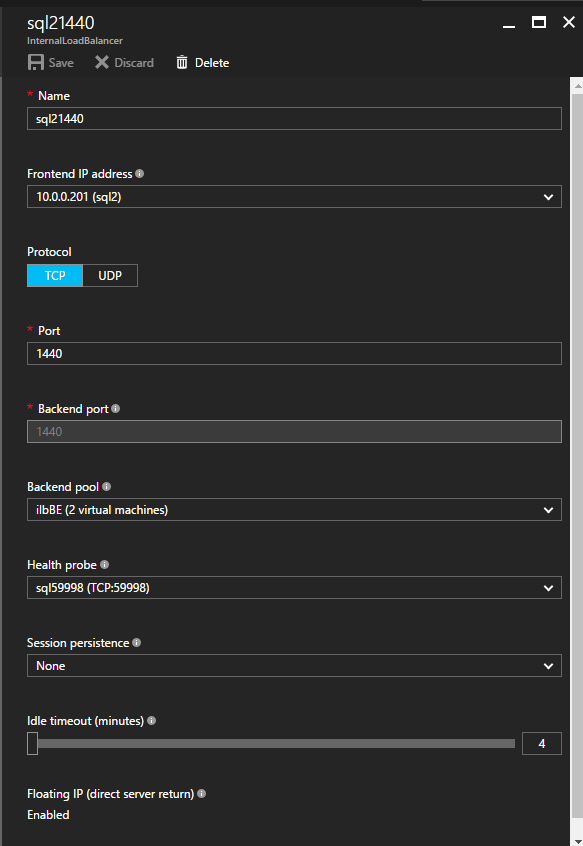
 Selanjutnya, kita perlu menambahkan probe lain karena instance dapat berjalan di server yang berbeda. Seperti yang ditunjukkan di bawah ini, saya menambahkan probe yang memeriksa port 59998 (bukan 59999 yang biasa). Kita perlu memastikan aturan baru merujuk pada penyelidikan ini. Kita juga perlu mengingat nomor port itu karena kita perlu memperbarui alamat IP yang terkait dengan instance ini selama langkah terakhir dari proses ini.
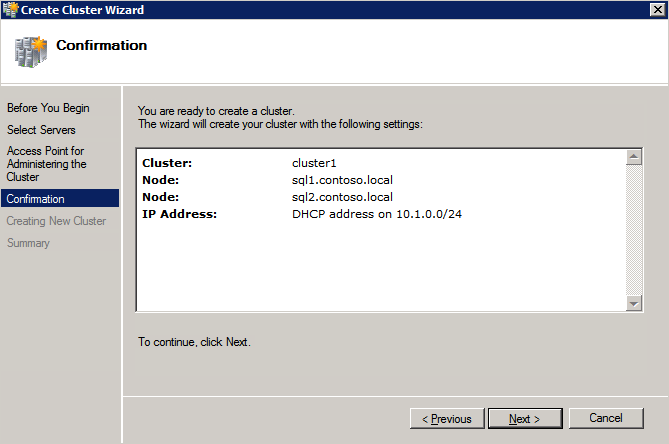
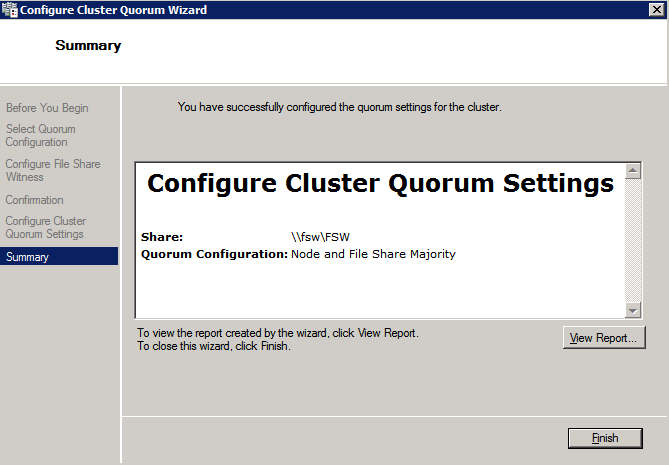
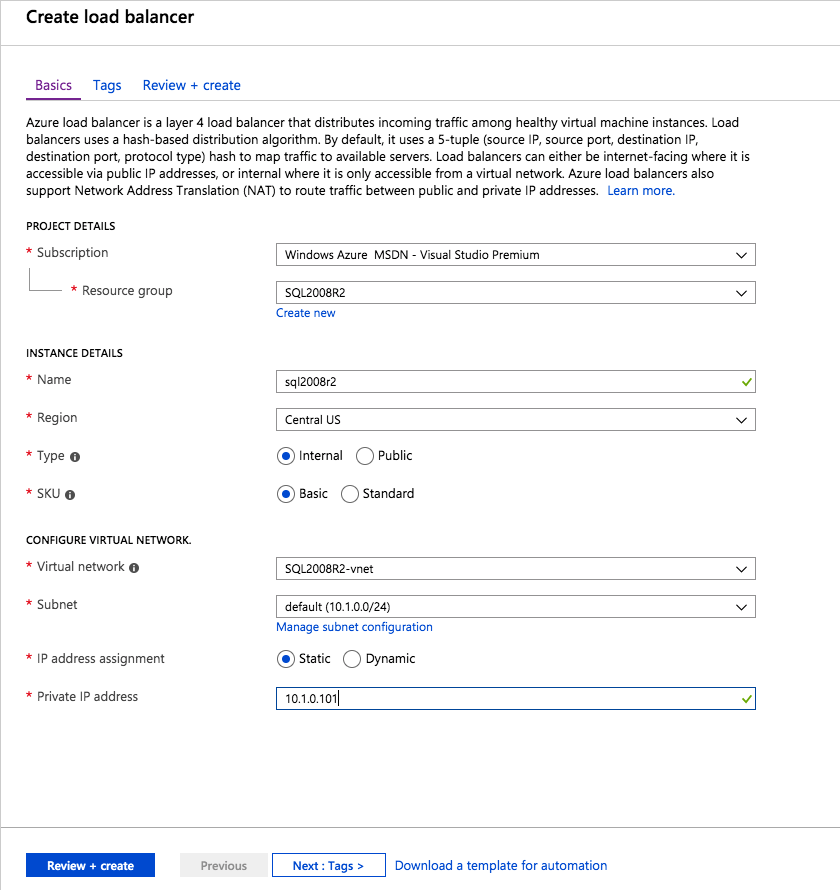
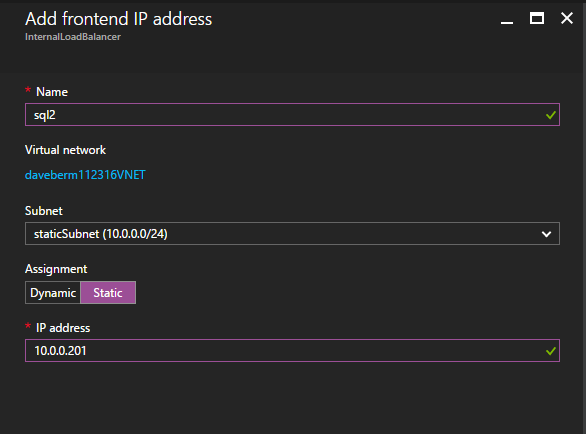
Selanjutnya, kita perlu menambahkan probe lain karena instance dapat berjalan di server yang berbeda. Seperti yang ditunjukkan di bawah ini, saya menambahkan probe yang memeriksa port 59998 (bukan 59999 yang biasa). Kita perlu memastikan aturan baru merujuk pada penyelidikan ini. Kita juga perlu mengingat nomor port itu karena kita perlu memperbarui alamat IP yang terkait dengan instance ini selama langkah terakhir dari proses ini.  Sekarang kita perlu menambahkan dua aturan baru ke ILB untuk mengarahkan lalu lintas yang ditujukan untuk ke-2 SQL ini. Tentu saja kita perlu menambahkan aturan untuk mengarahkan kembali port TCP 1440 (port yang saya gunakan untuk instance bernama SQL), tetapi karena kita sekarang menggunakan instance bernama kita juga perlu memiliki port untuk mendukung Layanan Browser SQL Server, Port UDP 1434. Pada gambar di bawah ini yang menggambarkan aturan untuk Layanan Browser SQL Server, perhatikan bahwa Alamat IP Front End merujuk pada alamat FrontendIP baru (10.0.0.201), port UDP 1434 untuk Port dan Backend Port. Di pool, Anda perlu menentukan dua server di cluster, dan akhirnya pastikan Anda memilih Health Probe yang baru saja kita buat.
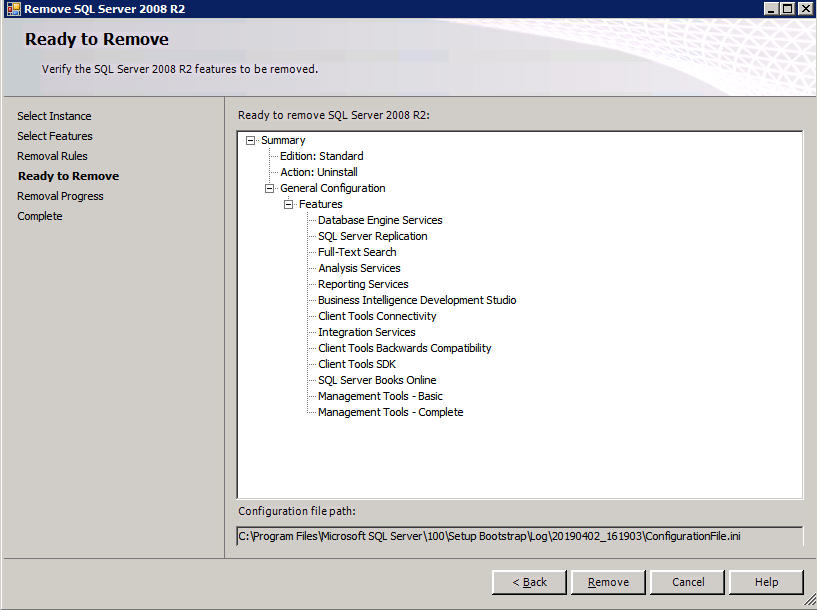
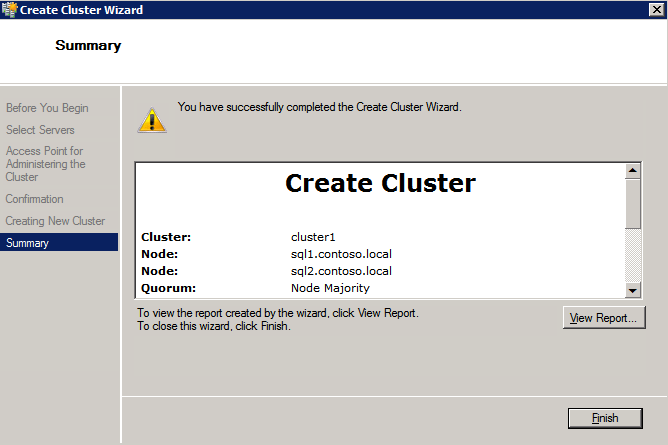
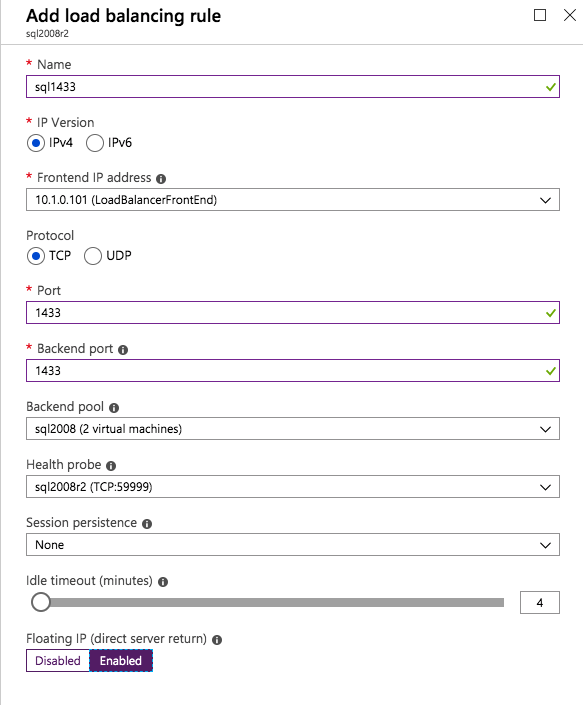
Sekarang kita perlu menambahkan dua aturan baru ke ILB untuk mengarahkan lalu lintas yang ditujukan untuk ke-2 SQL ini. Tentu saja kita perlu menambahkan aturan untuk mengarahkan kembali port TCP 1440 (port yang saya gunakan untuk instance bernama SQL), tetapi karena kita sekarang menggunakan instance bernama kita juga perlu memiliki port untuk mendukung Layanan Browser SQL Server, Port UDP 1434. Pada gambar di bawah ini yang menggambarkan aturan untuk Layanan Browser SQL Server, perhatikan bahwa Alamat IP Front End merujuk pada alamat FrontendIP baru (10.0.0.201), port UDP 1434 untuk Port dan Backend Port. Di pool, Anda perlu menentukan dua server di cluster, dan akhirnya pastikan Anda memilih Health Probe yang baru saja kita buat. 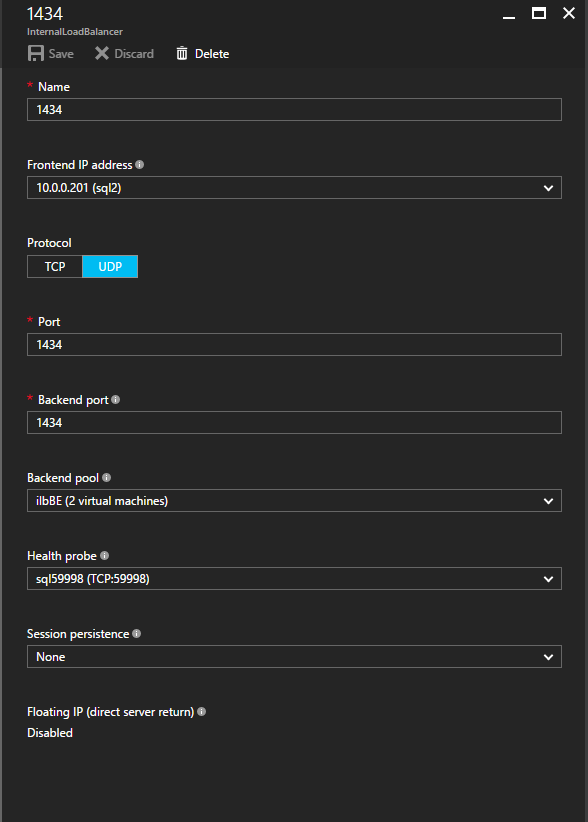 Kami sekarang akan menambahkan aturan untuk TCP / 1440. Seperti yang ditunjukkan pada gambar di bawah ini, tambahkan aturan baru untuk port TCP 1440, atau port apa pun yang dikunci untuk instance bernama SQL Server. Sekali lagi, pastikan untuk memilih Alamat IP FrontEnd baru dan Probe Kesehatan baru (59998). Juga, pastikan IP Terapung (pengembalian server langsung) diaktifkan.
Kami sekarang akan menambahkan aturan untuk TCP / 1440. Seperti yang ditunjukkan pada gambar di bawah ini, tambahkan aturan baru untuk port TCP 1440, atau port apa pun yang dikunci untuk instance bernama SQL Server. Sekali lagi, pastikan untuk memilih Alamat IP FrontEnd baru dan Probe Kesehatan baru (59998). Juga, pastikan IP Terapung (pengembalian server langsung) diaktifkan.