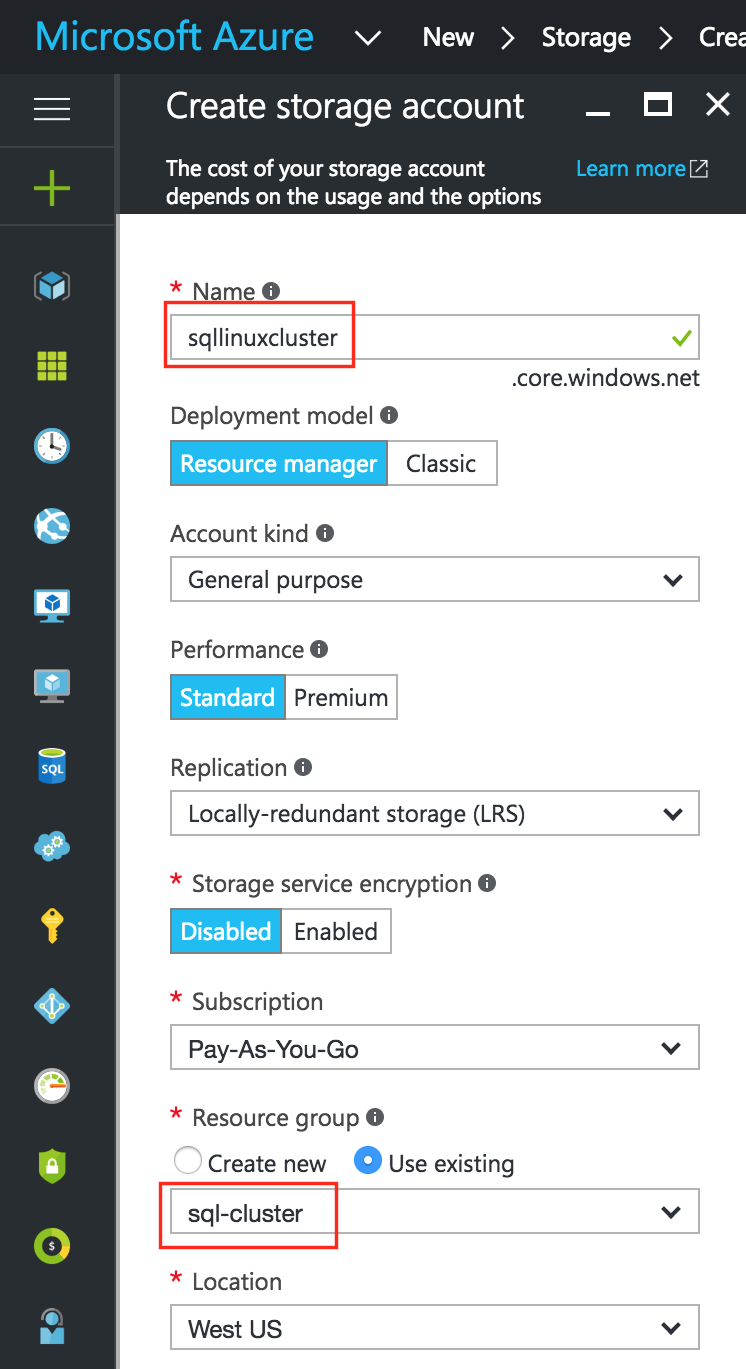
항상 가용성 그룹 및 SANless SQL Server 장애 조치 (Failover) 클러스터 인스턴스가 혼합 된 SQL Server 고 가용성, 재해 복구 구현
소개
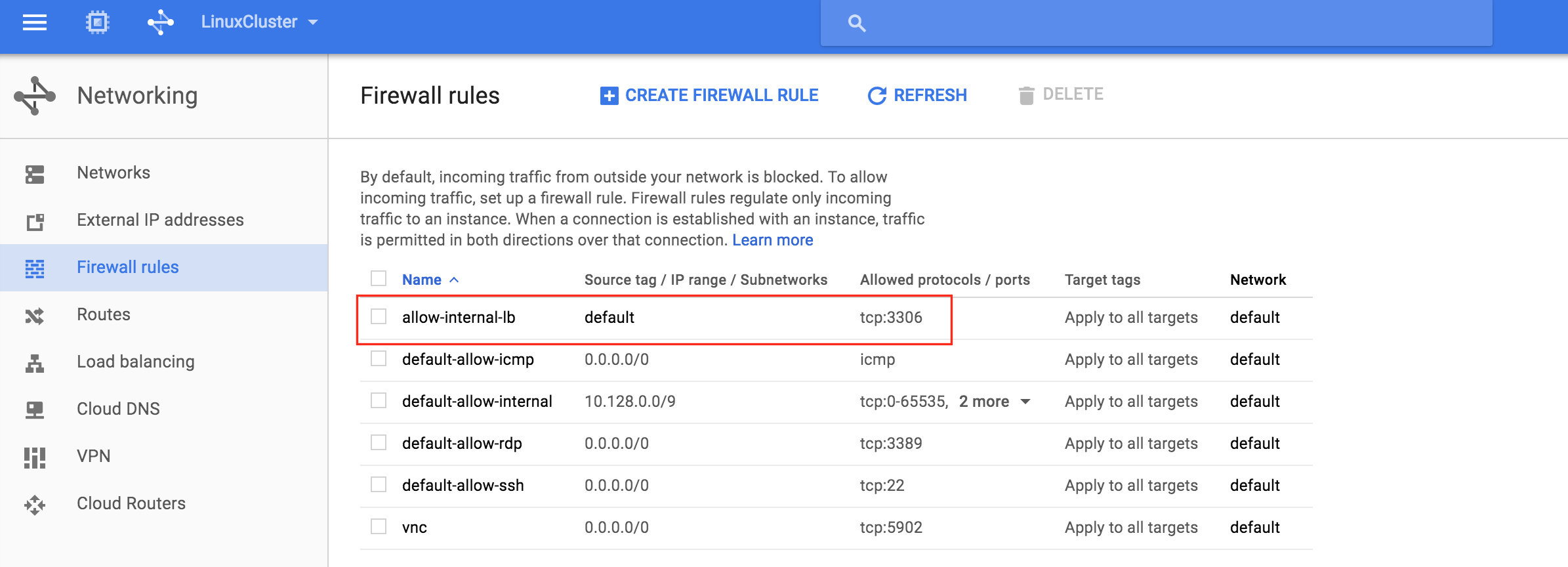
FCI (Always On Availability Groups)와 SQL Server 장애 조치 (FCI) 인스턴스를 함께 사용하는 것에 대한 내용은 잘 설명되어 있습니다. 그러나 솔루션의 SQL Server FCI 부분이 공유 저장소를 사용한다고 가정하는 사용 가능한 대부분의 설명서 문서 구성. Storage Spaces Direct (S2D)를 사용하여 SANless SQL Server FCI를 구축하려는 경우에도 SQL Server AG를 추가 할 수 있습니까? 불행히도이 질문에 대한 대답은 '아니오'입니다. 현재까지 S2D 기반 SQL Server FCI와 Always On AG의 조합은 지원되지 않습니다. 이전에이 S2D 제한 사항에 대해 이전에 블로그에 올렸습니다. 그러나 좋은 소식은 SIOS DataKeeper를 사용하여 SANless SQL Server FCI를 구축 할 수 있으며 읽을 수있는 보조 도메인과 같은 것들에 대해 Always On AG를 활용할 수 있다는 것입니다. 기존의 SAN 기반 SQL Server FCI와 Always On AG를 혼합 할 때 적용되는 것과 동일한 규칙을 준수해야하지만 SQL Server 고 가용성을 달성하기위한 대부분의 부분은 거의 같습니다. DataKeeper 동기식 복제는 일반적으로 동일한 데이터 센터 또는 클라우드 지역의 노드간에 사용되지만 재해 복구를 위해 다른 지역의 추가 노드에 비동기 적으로 복제하고자 할 수 있습니다. 이 경우 예기치 않은 오류가 발생한 후에 DR 노드를 온라인 상태로 전환해야하는 경우 Always On AG 구성을 폐기하고 재구성해야합니다. 이 요구 사항은 VM 내부에서 실행되는 SQL Server Always On AG의 비동기 스냅 샷 복원과 관련하여 Microsoft가 여기에서 발표 한 내용과 매우 유사합니다.
가용성 그룹
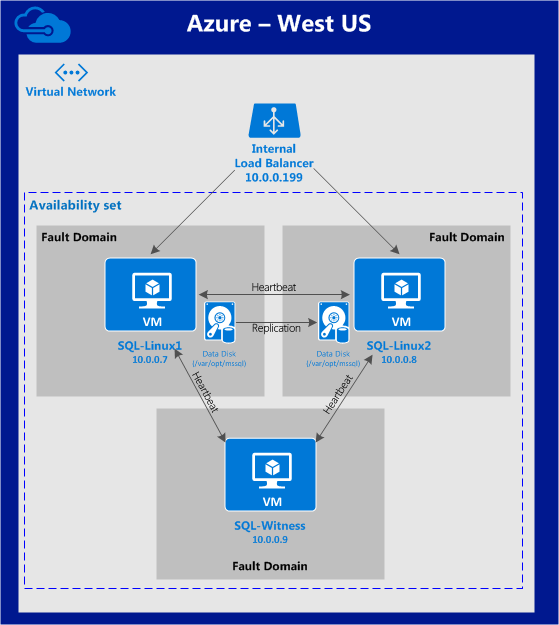
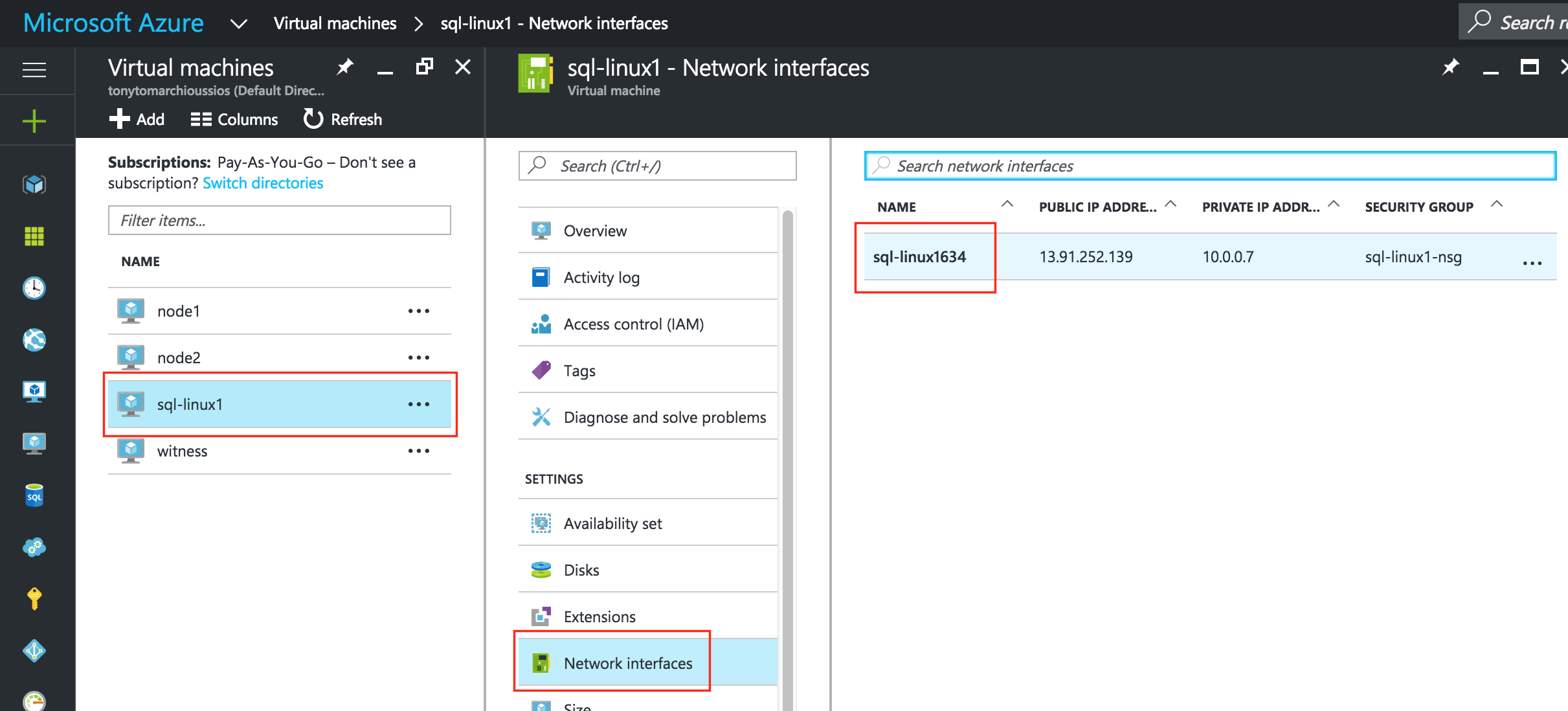
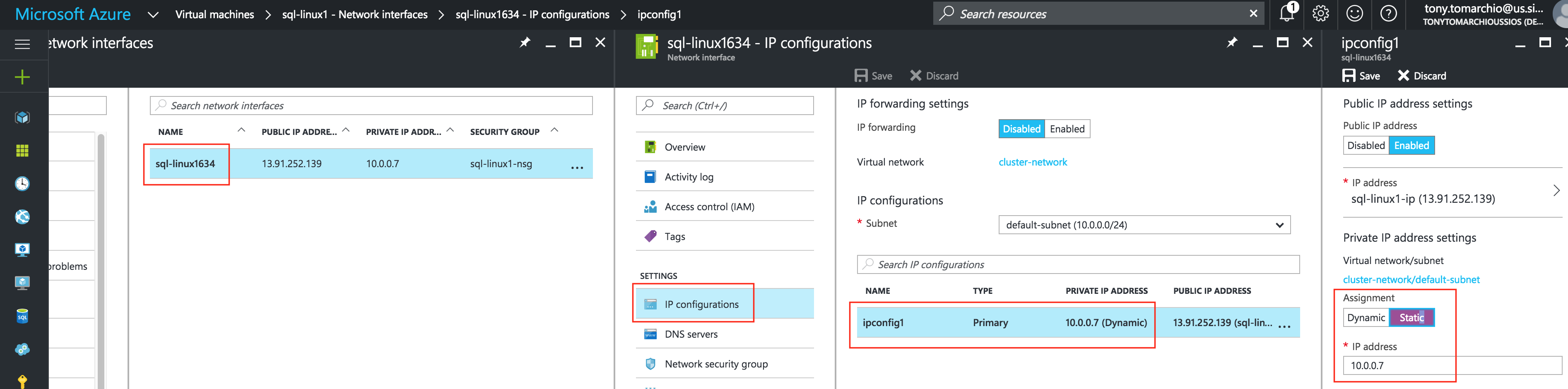
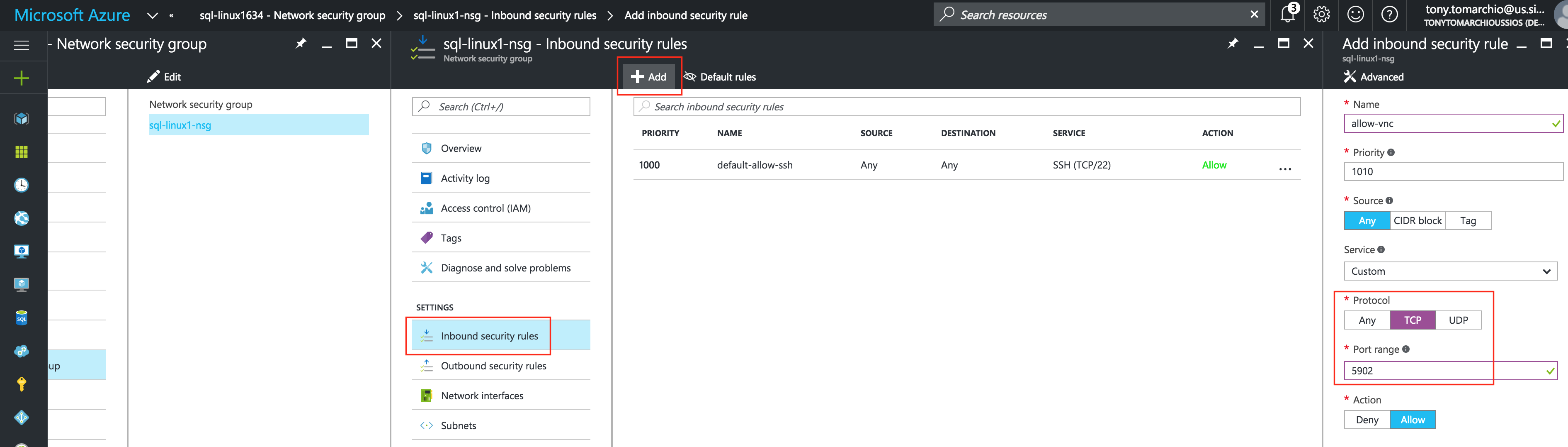
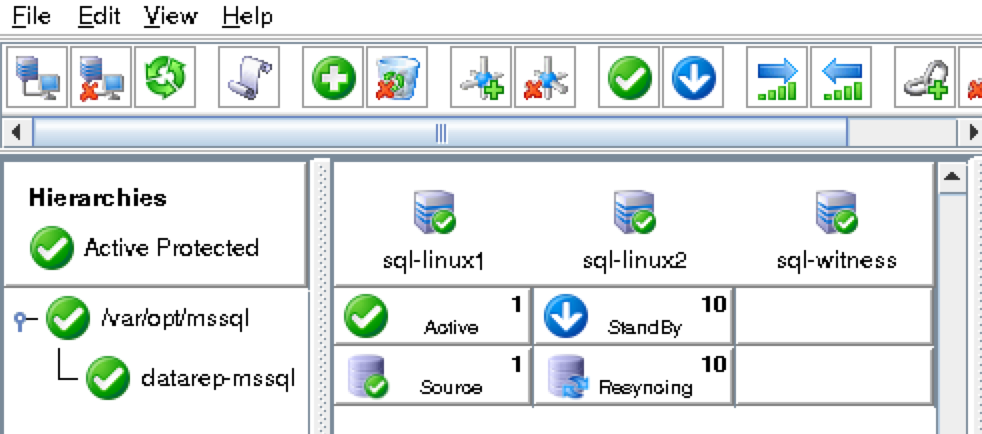
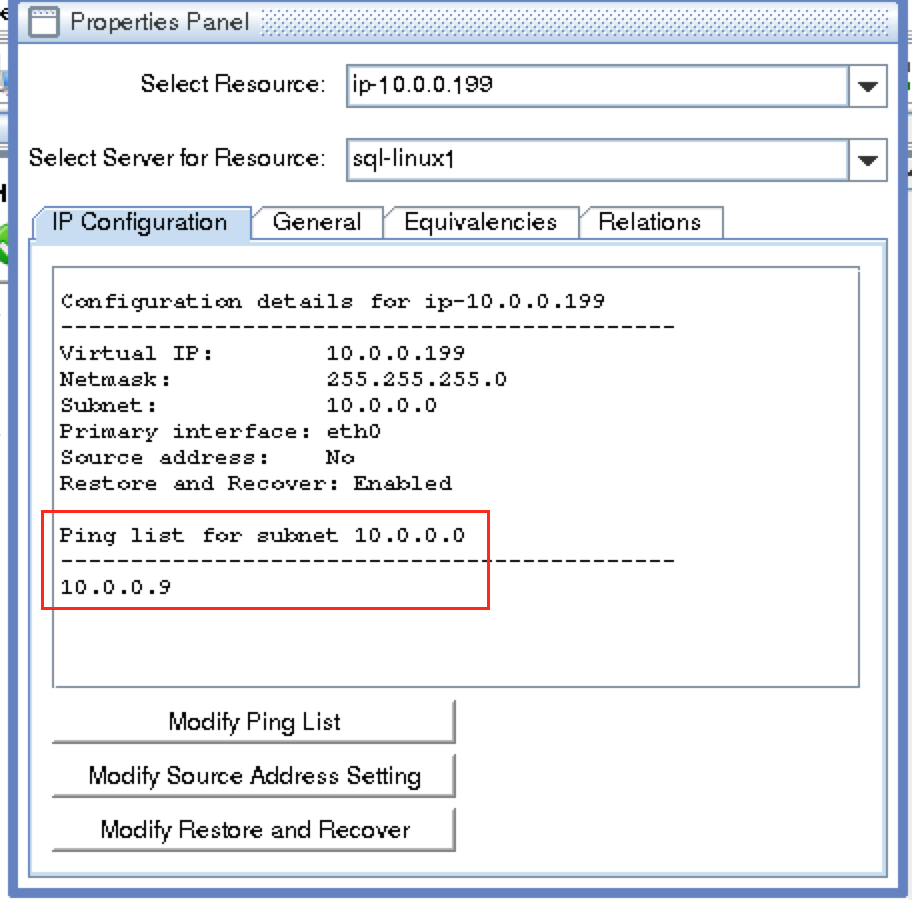
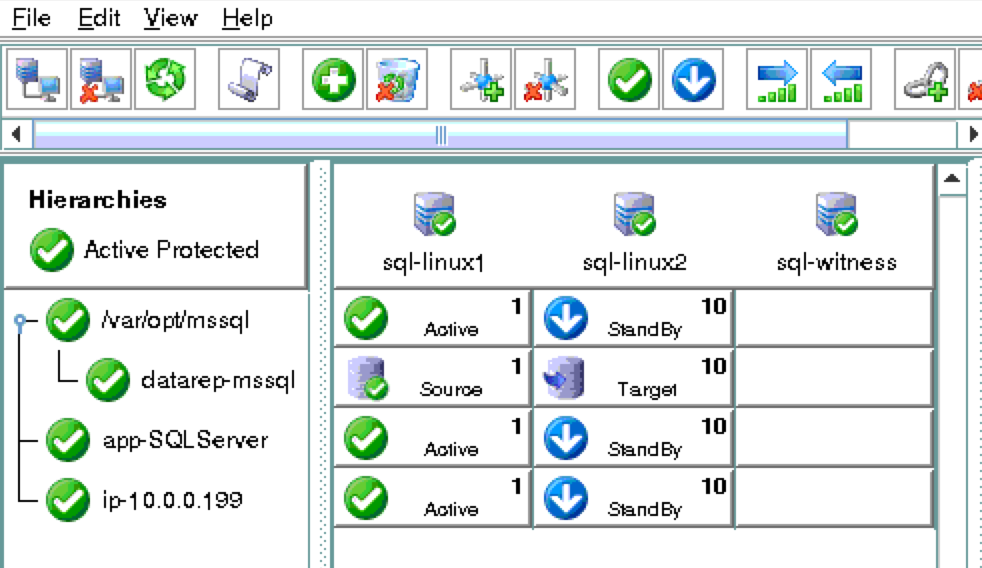
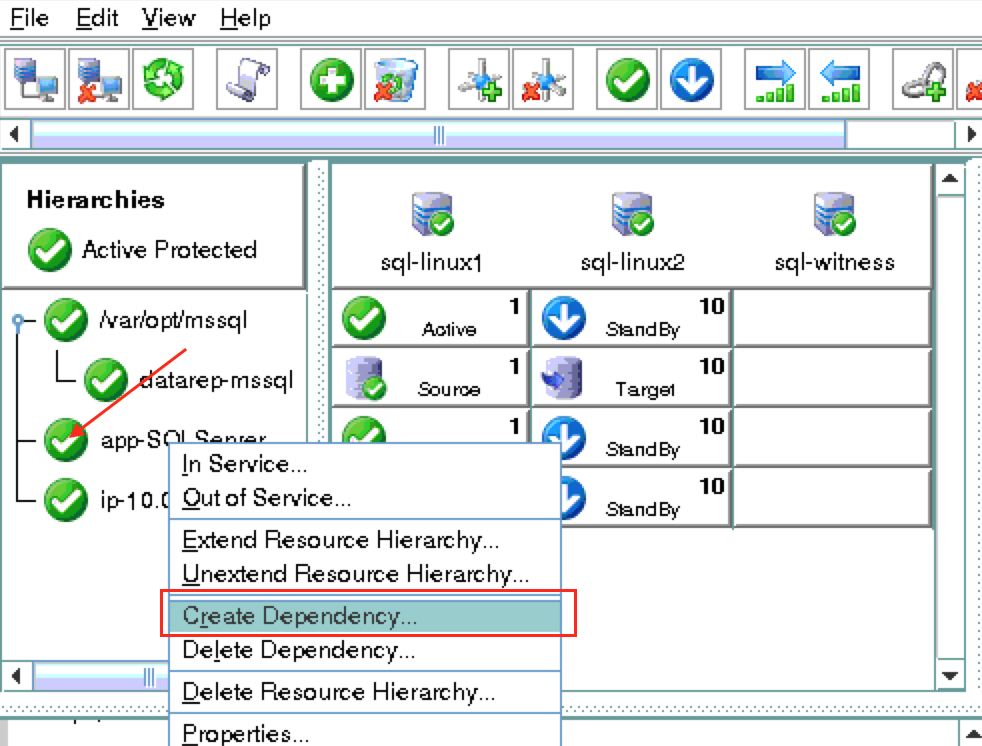
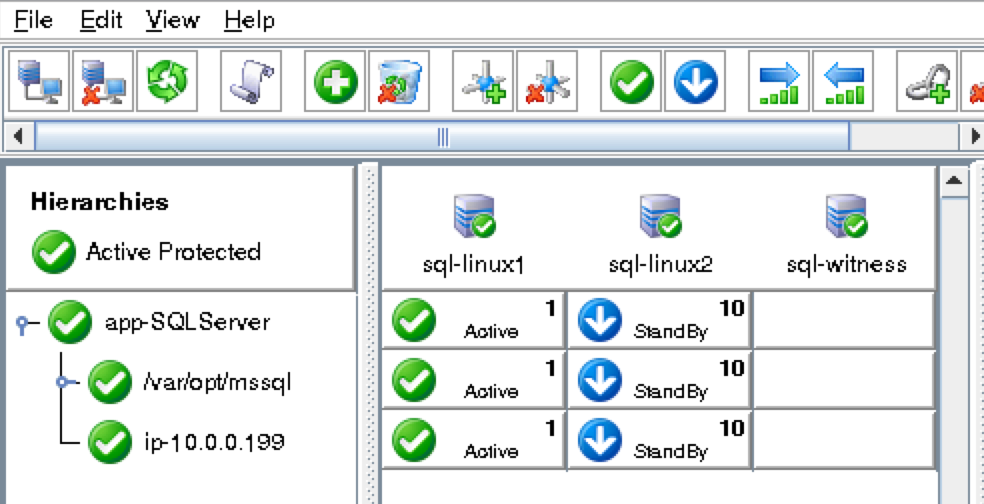
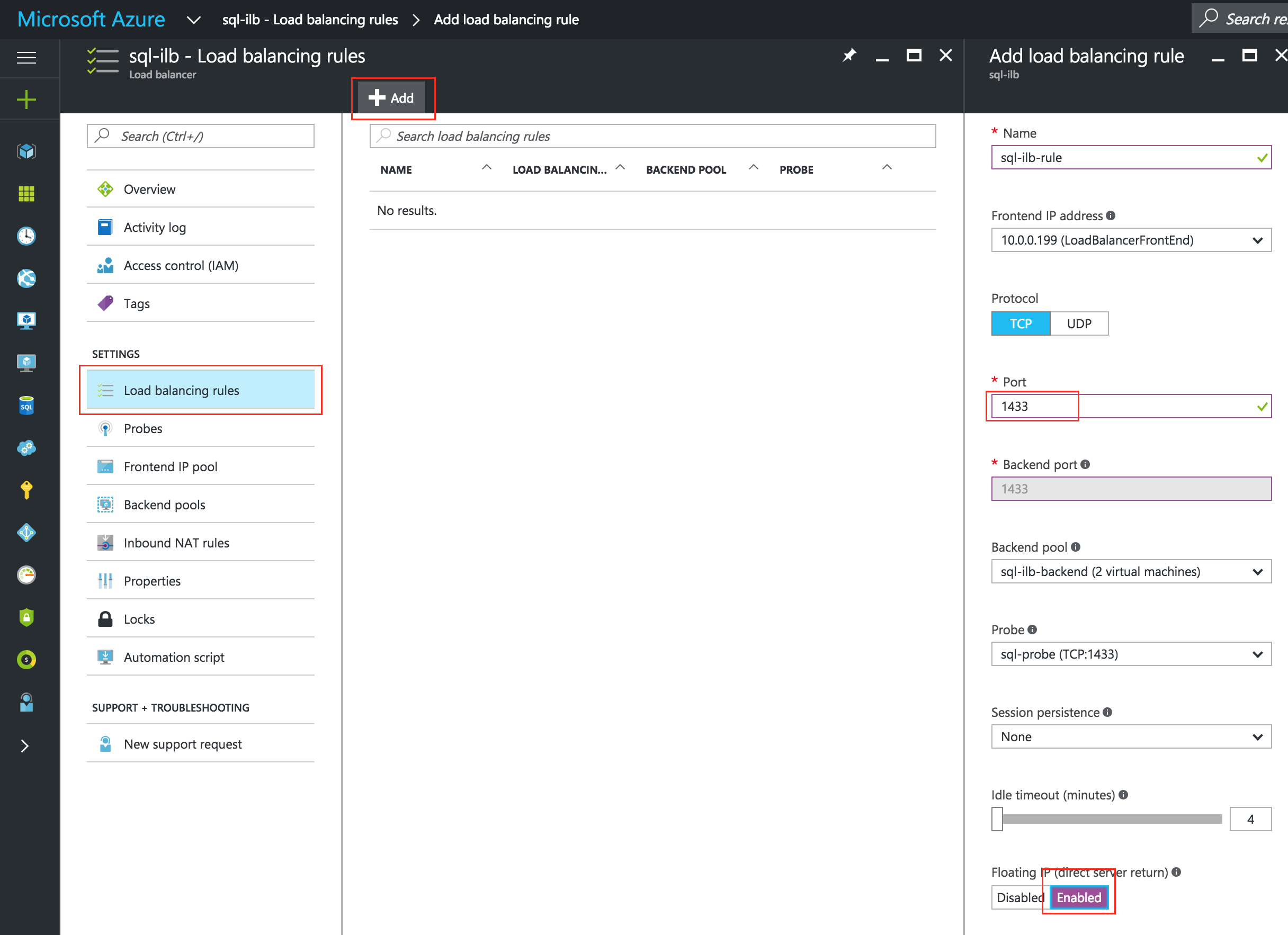
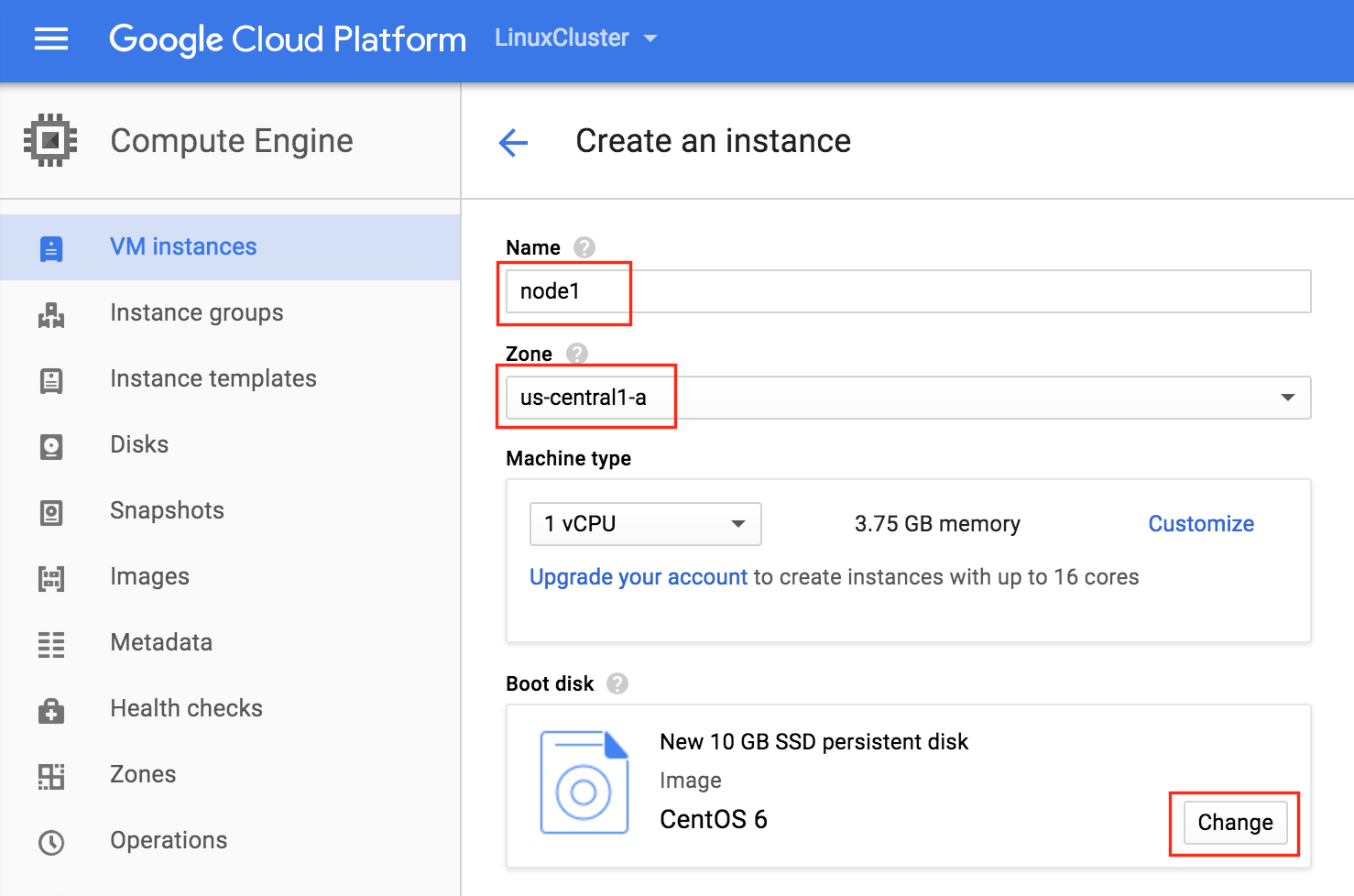
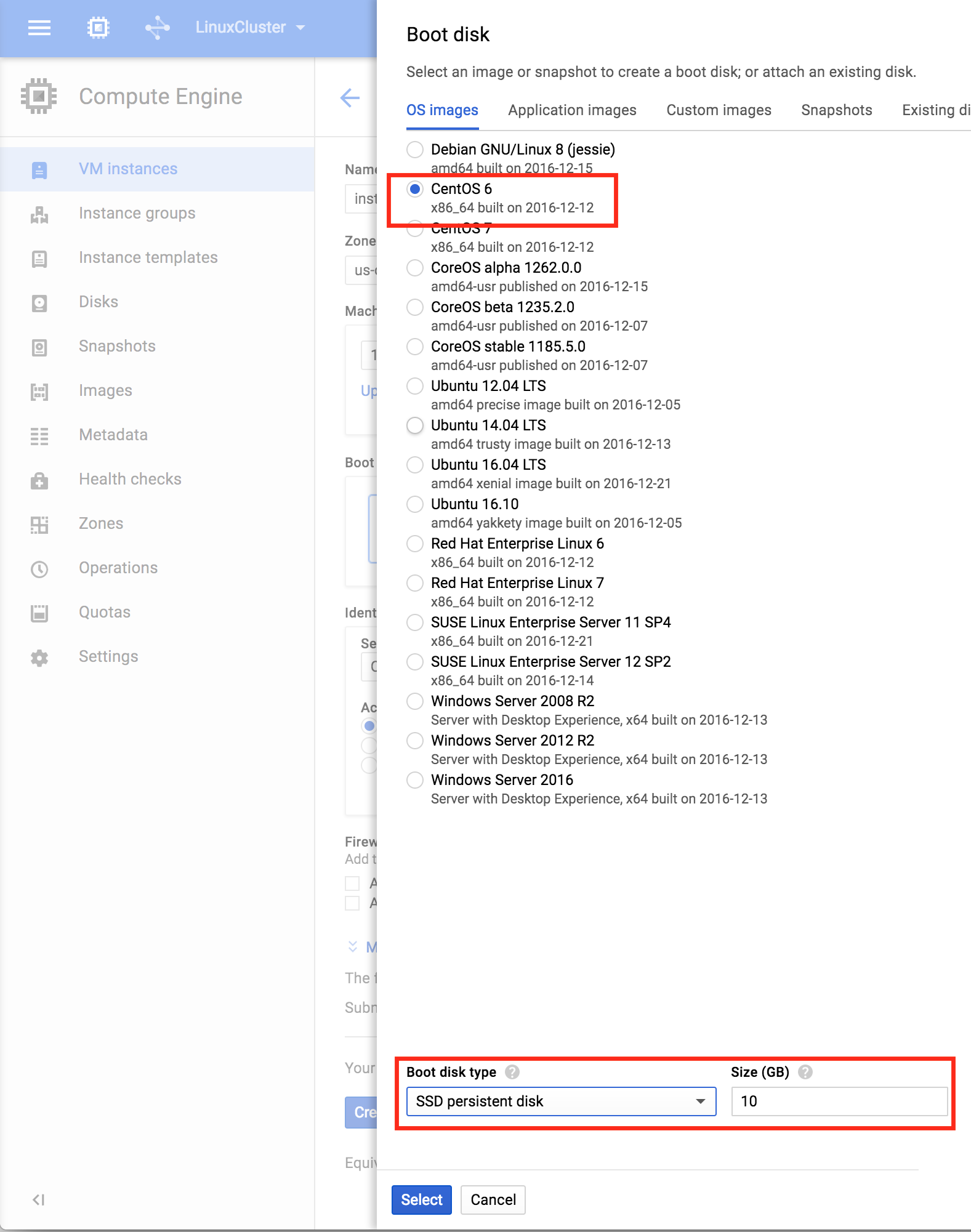
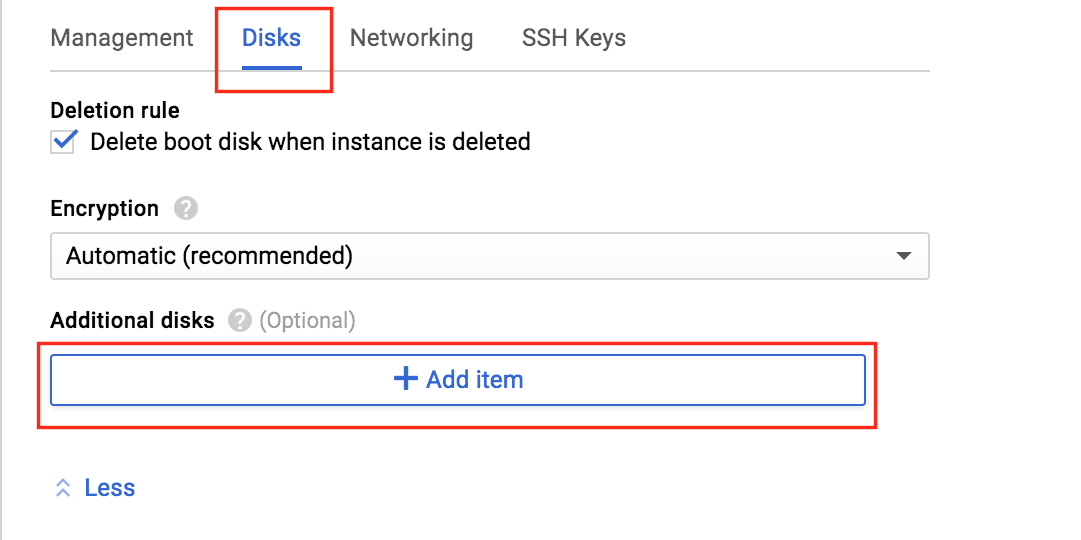
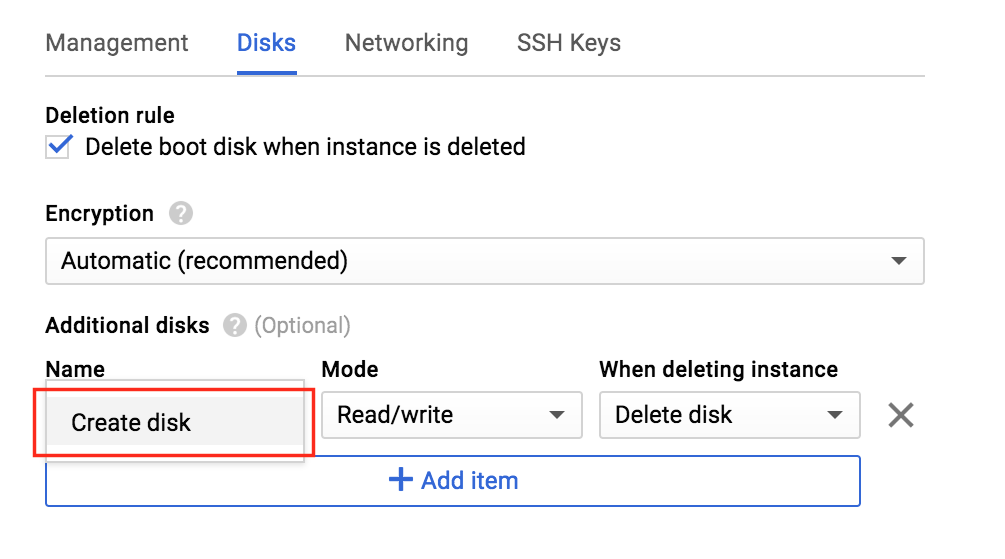
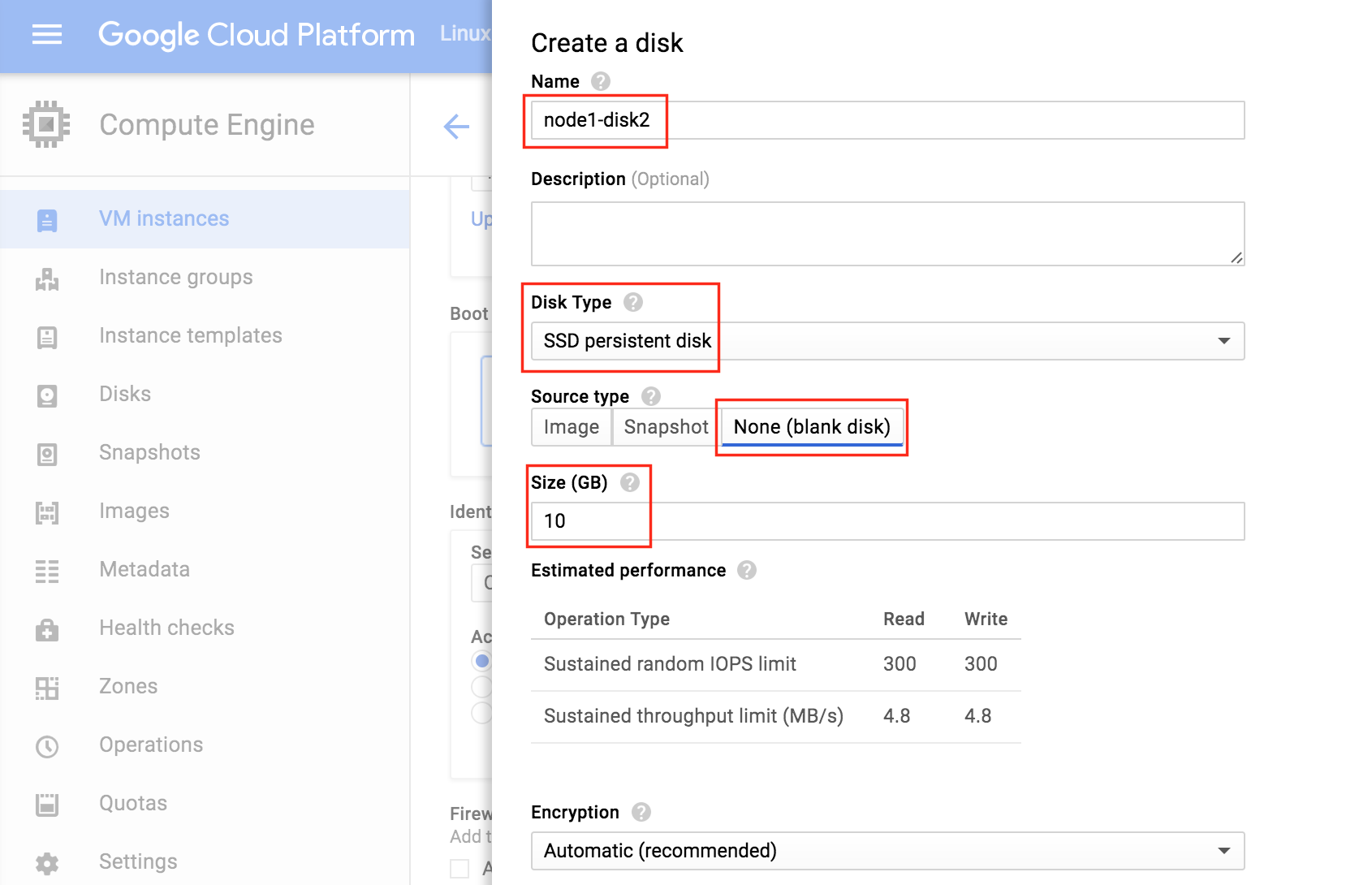
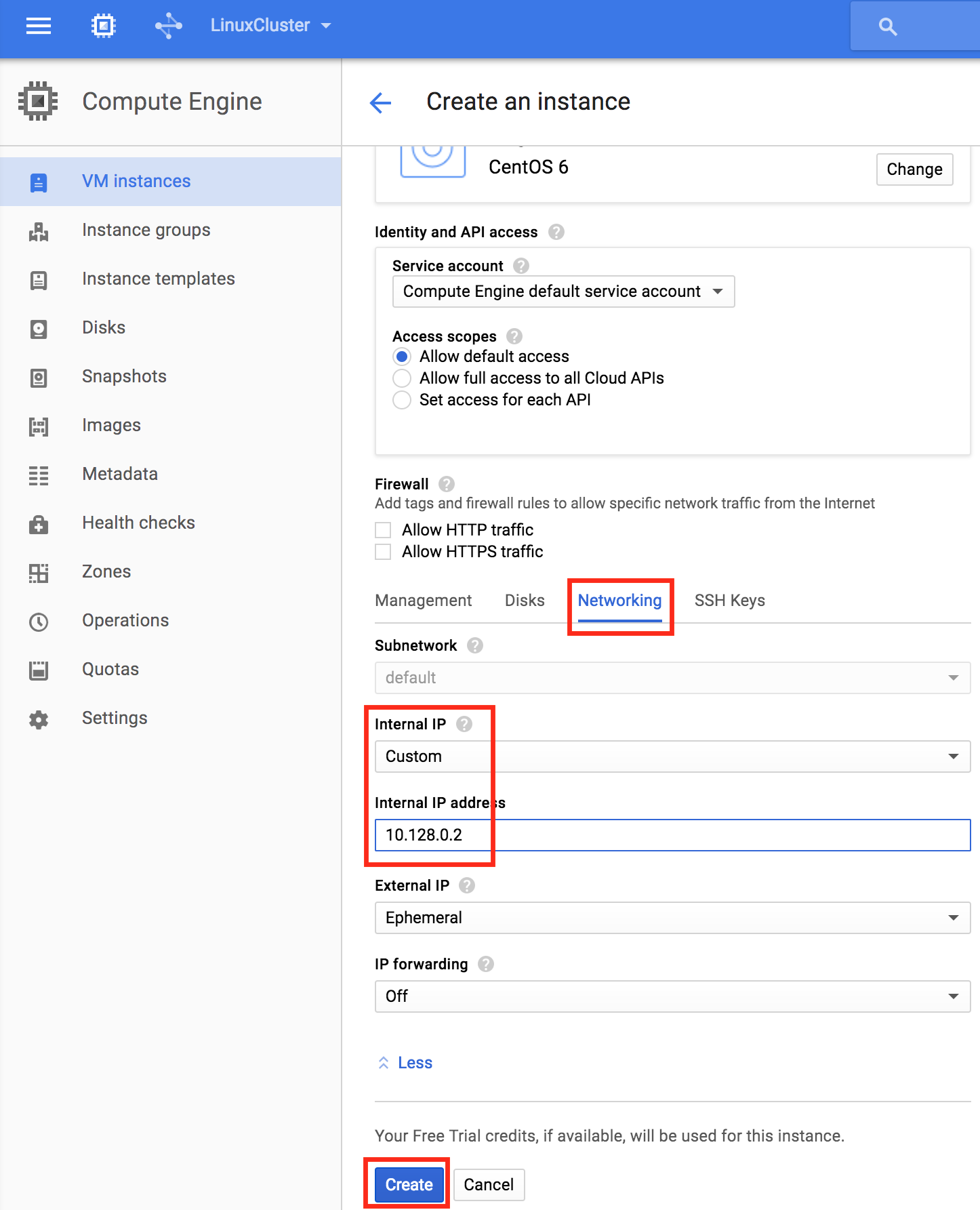
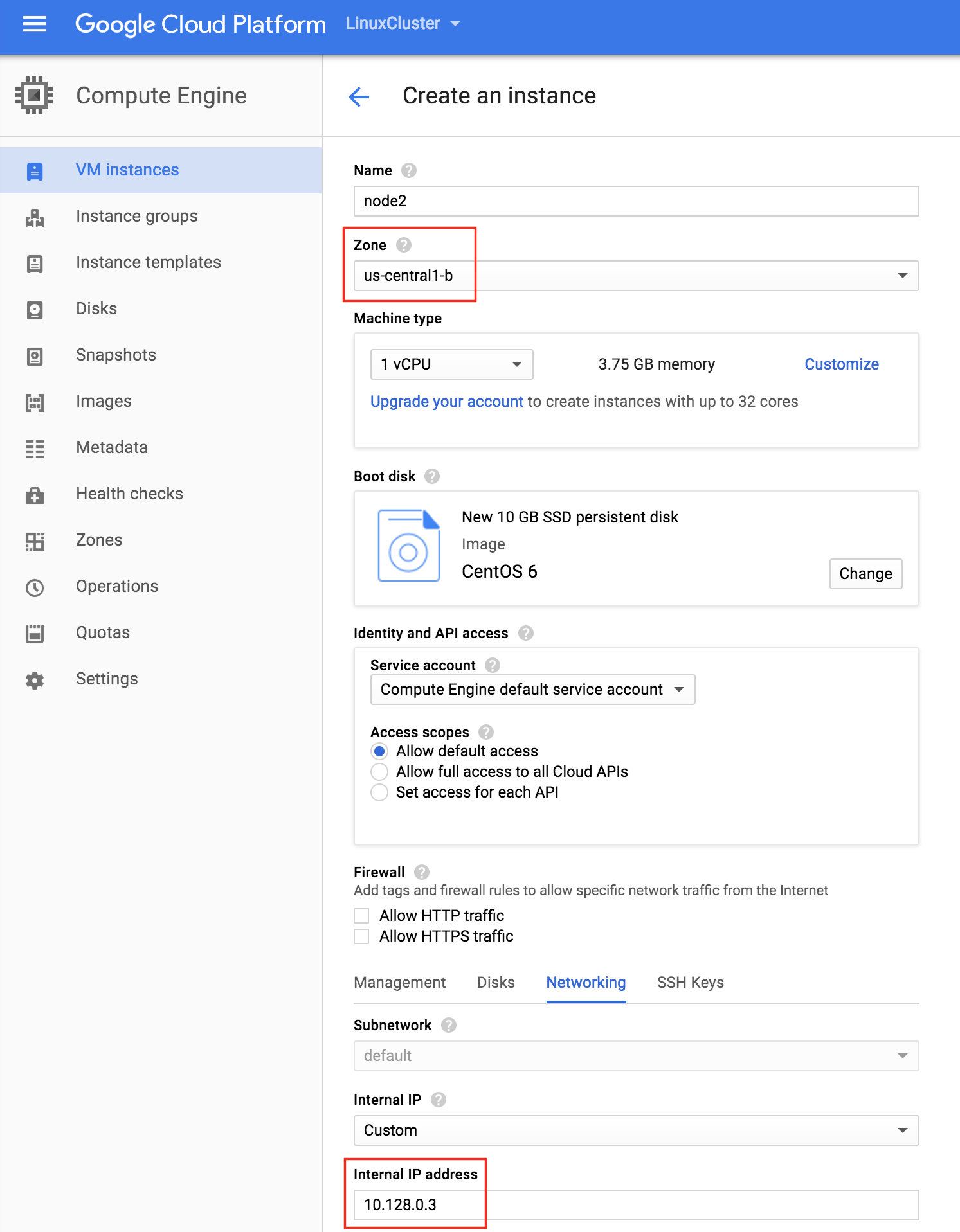
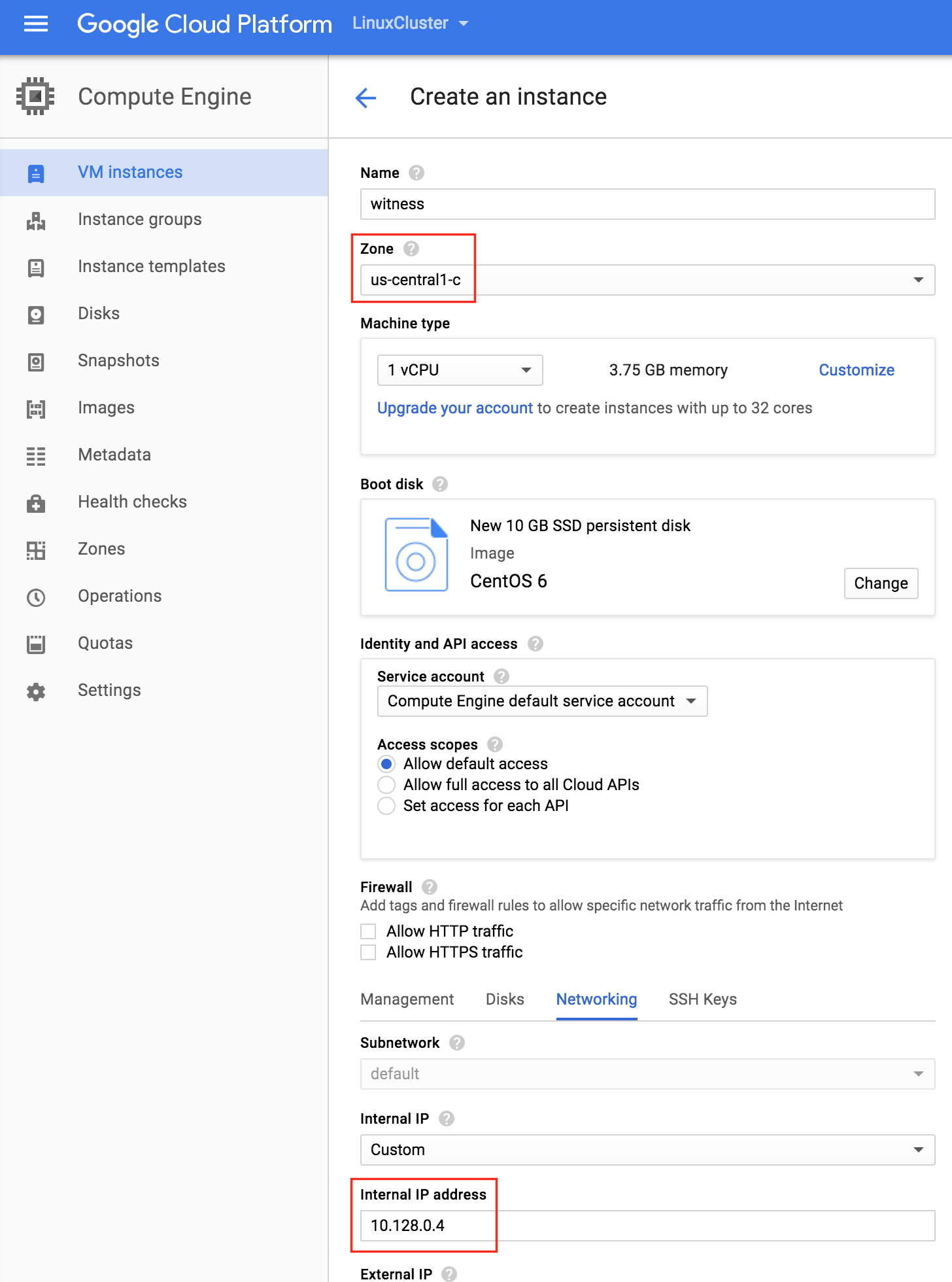
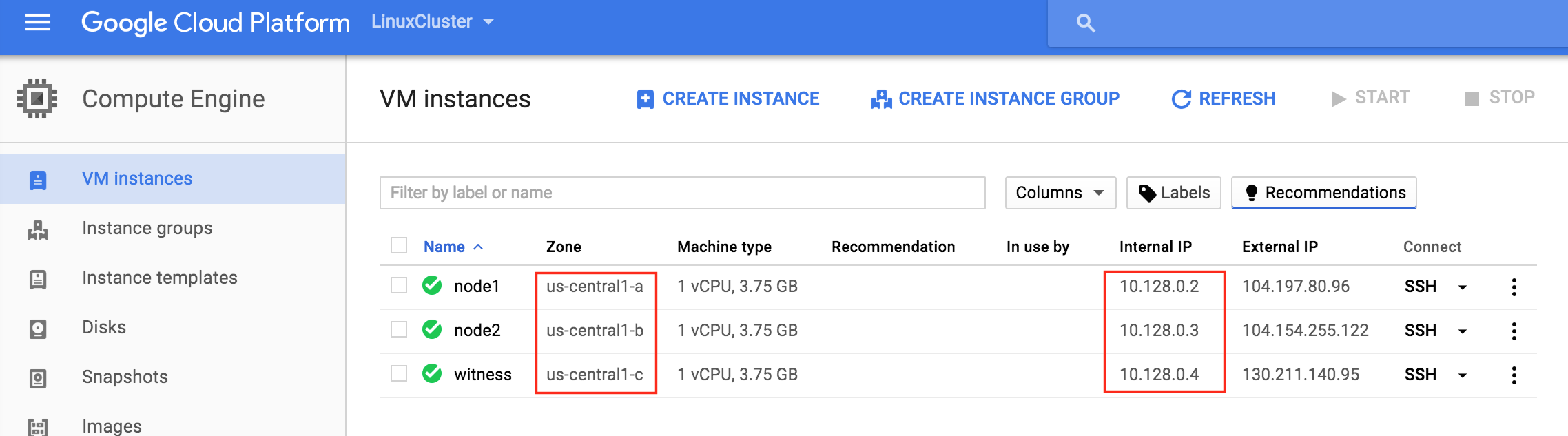
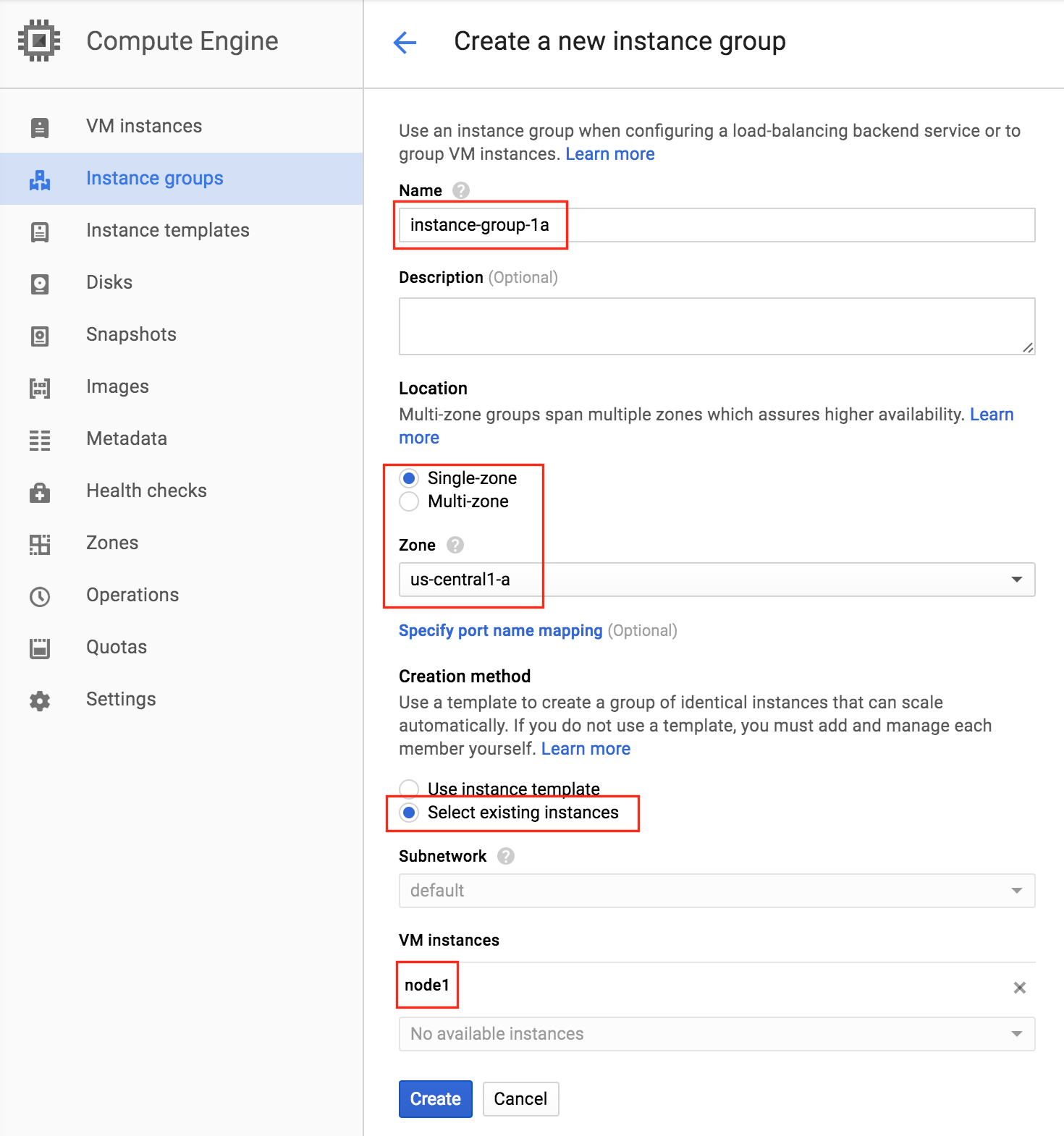
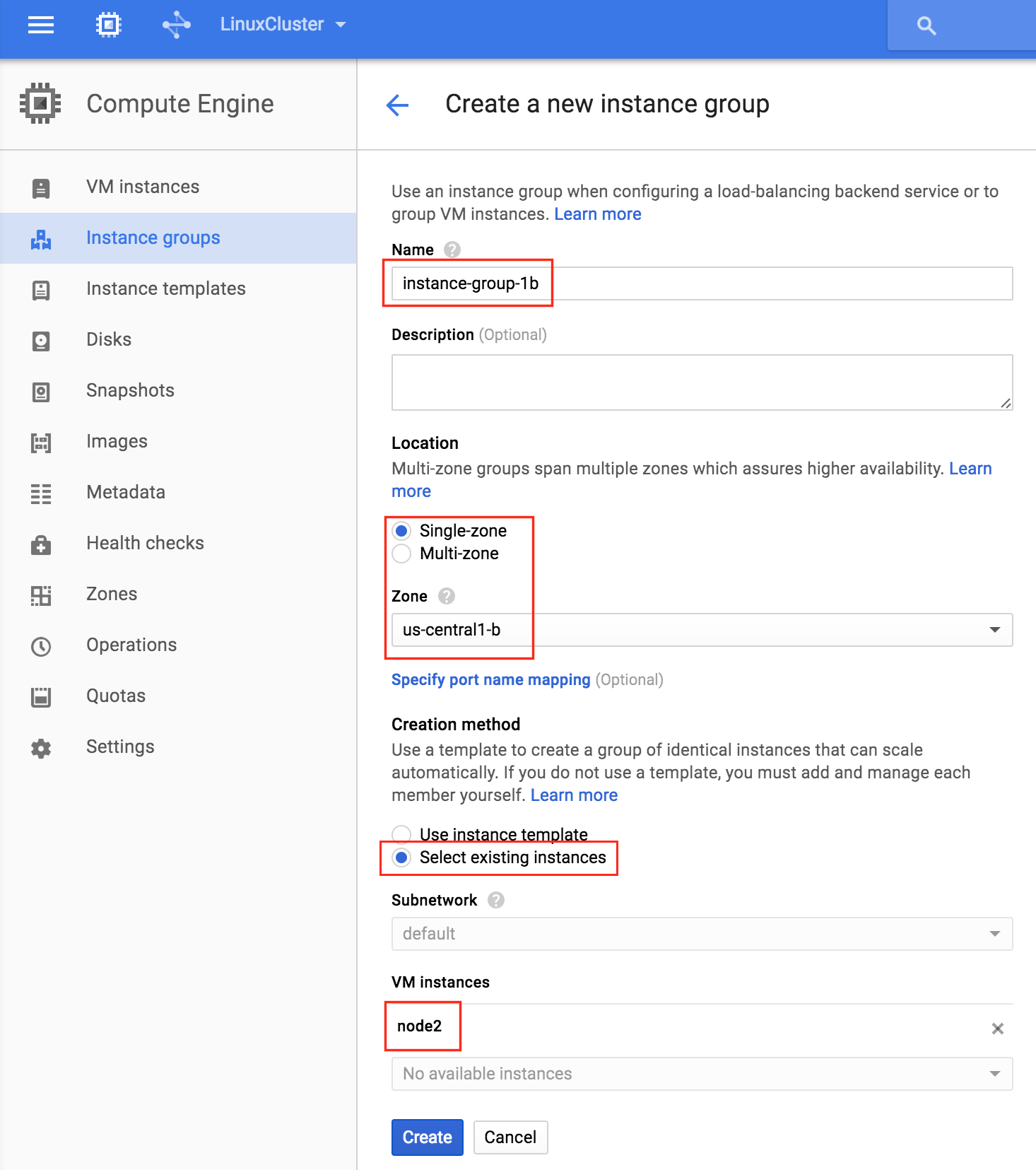
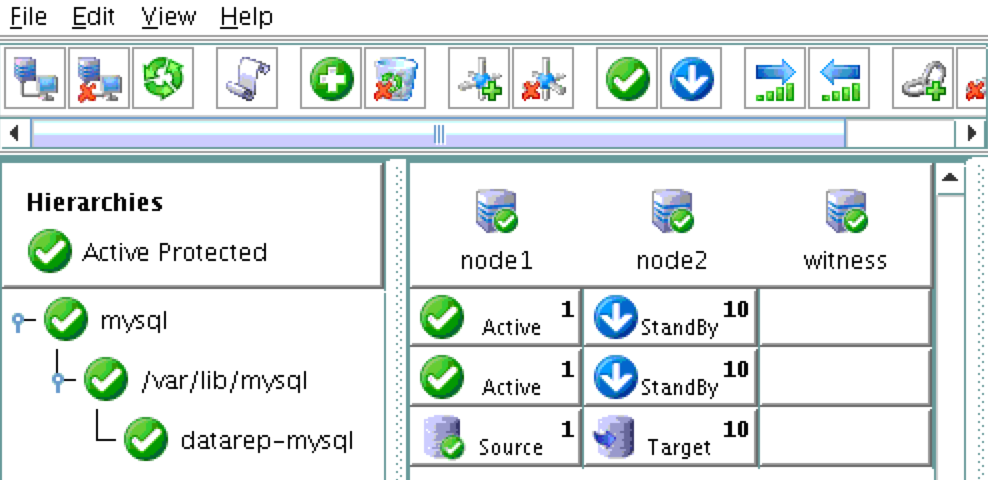
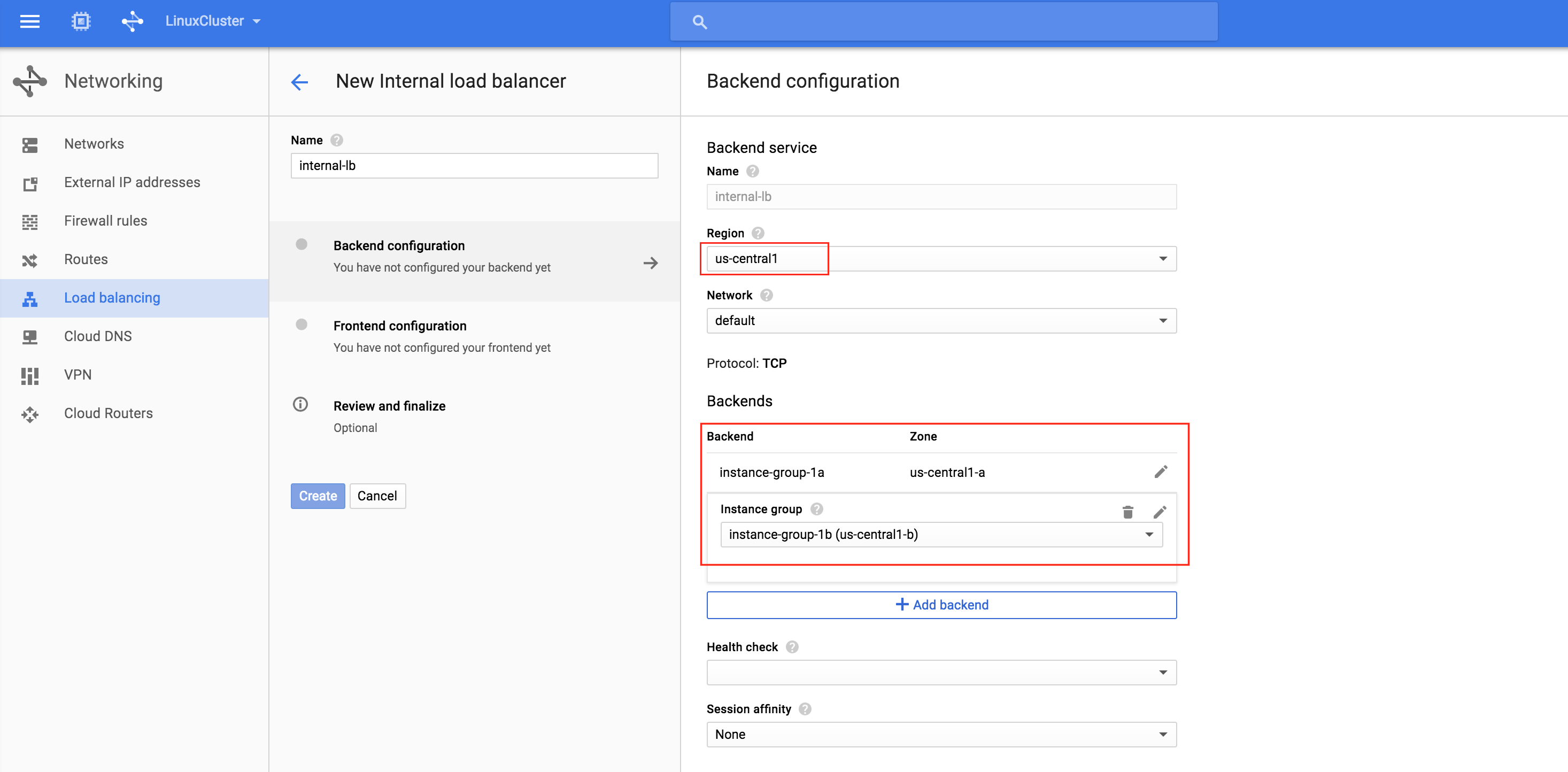
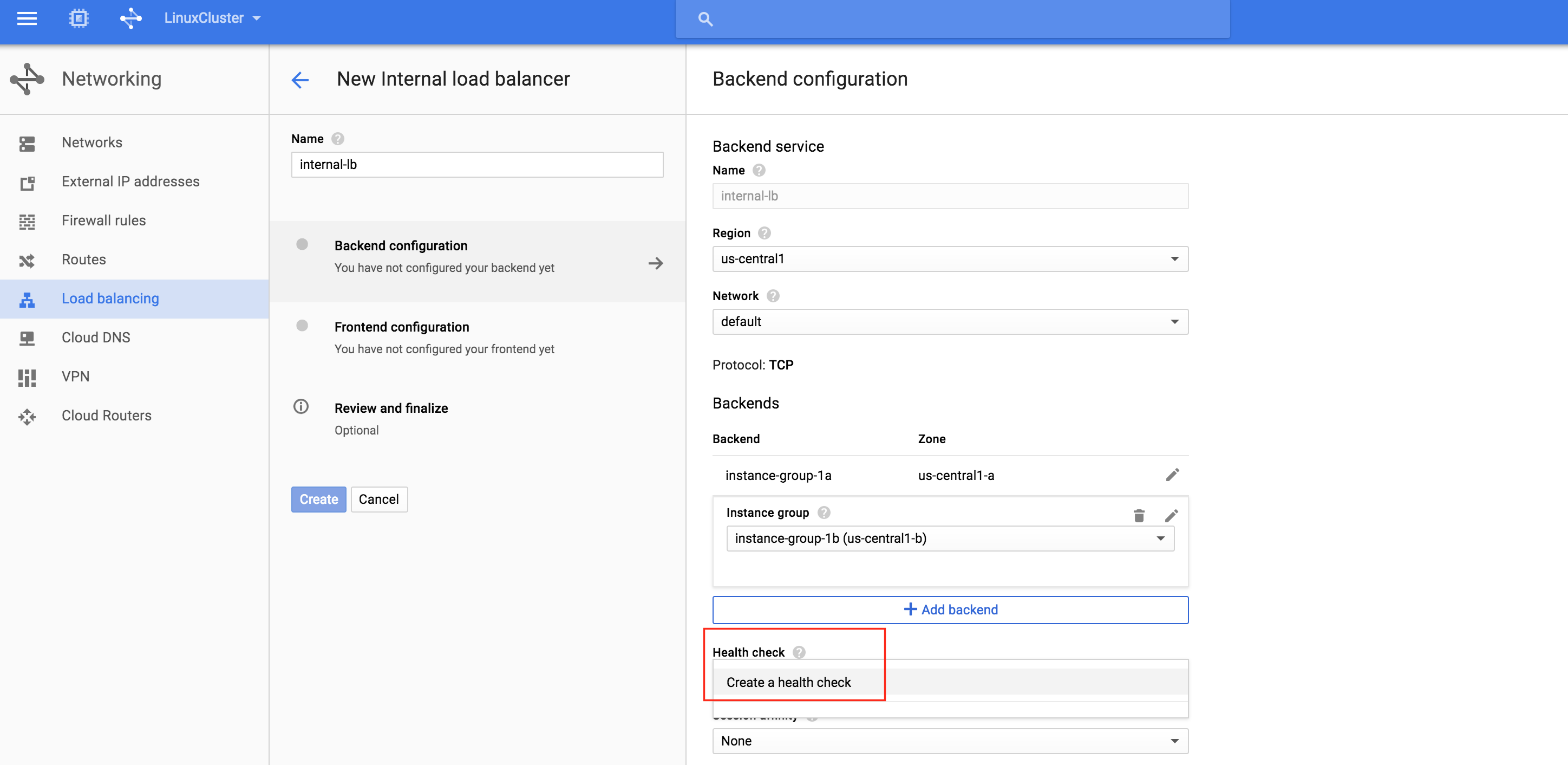
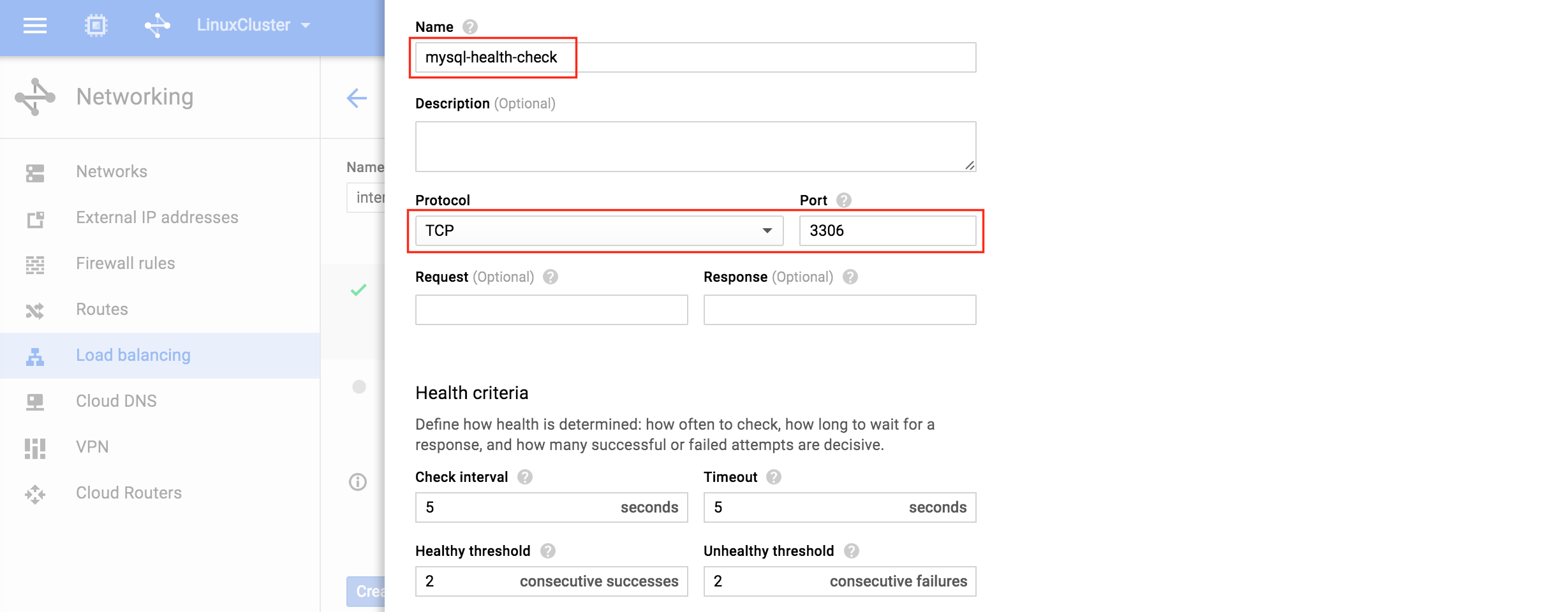
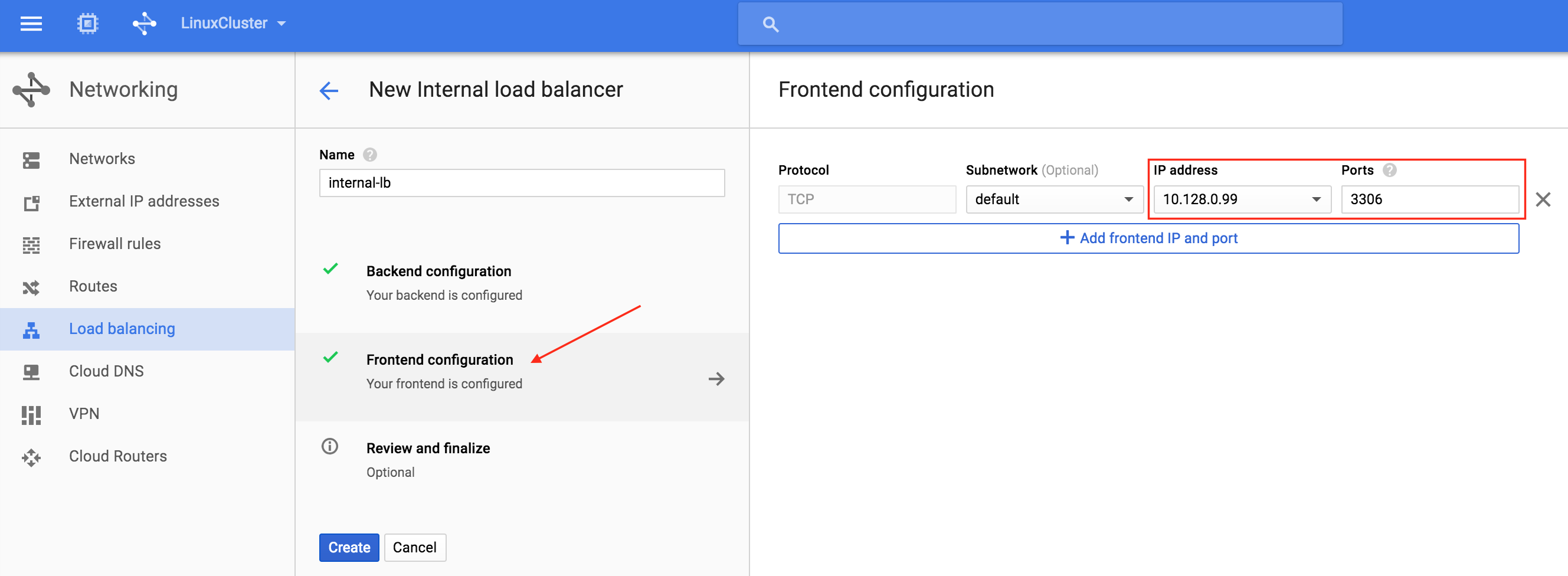
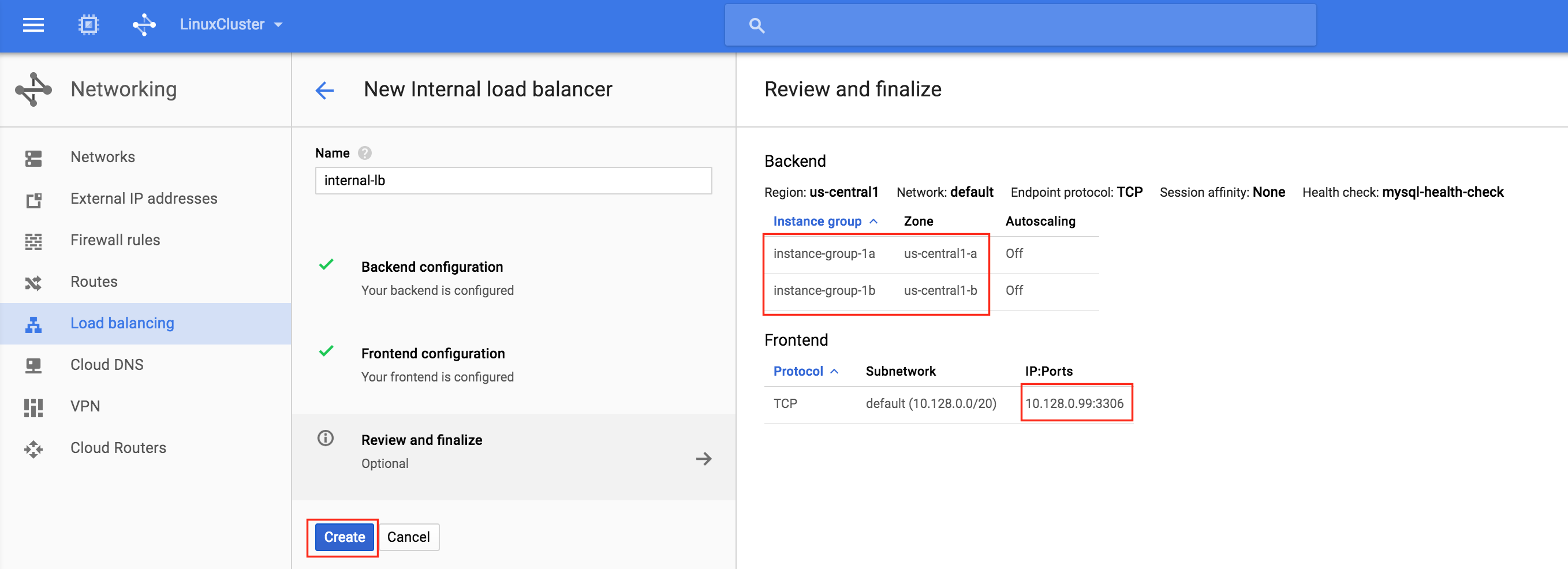
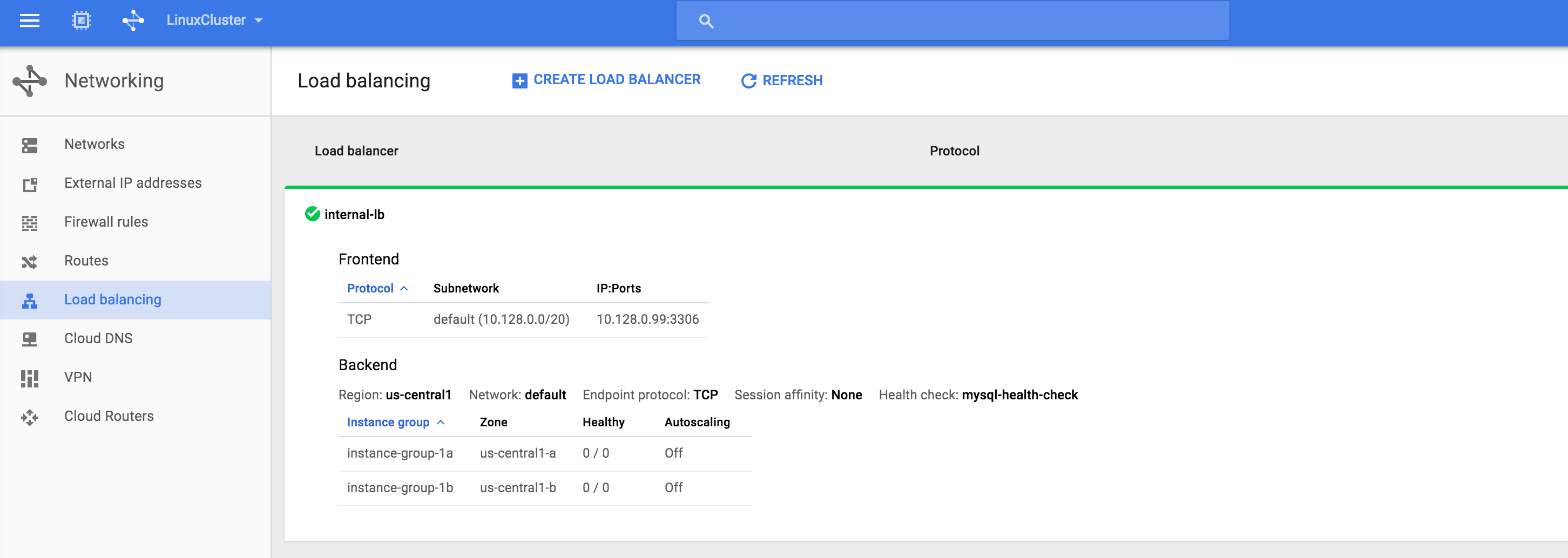
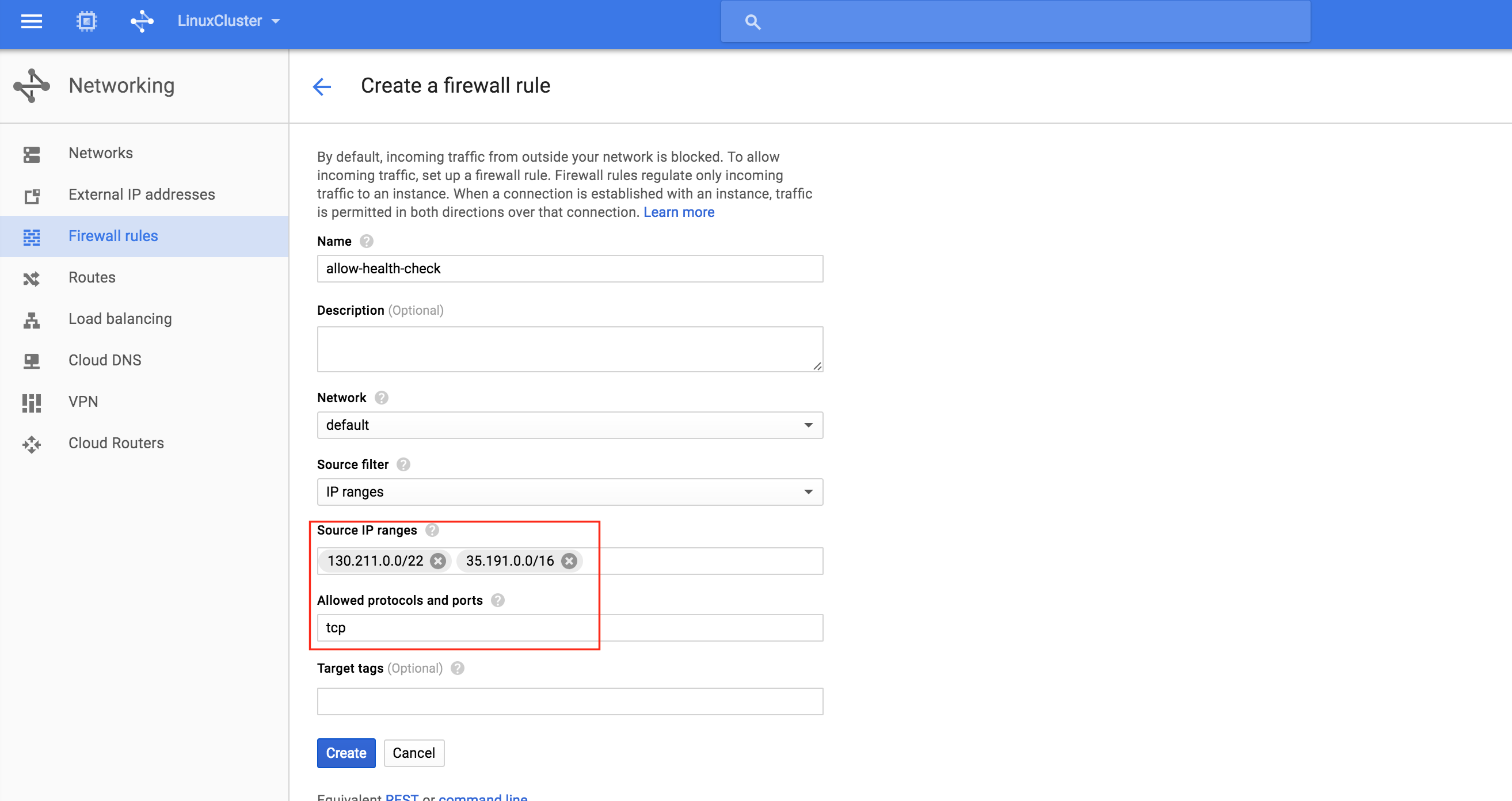
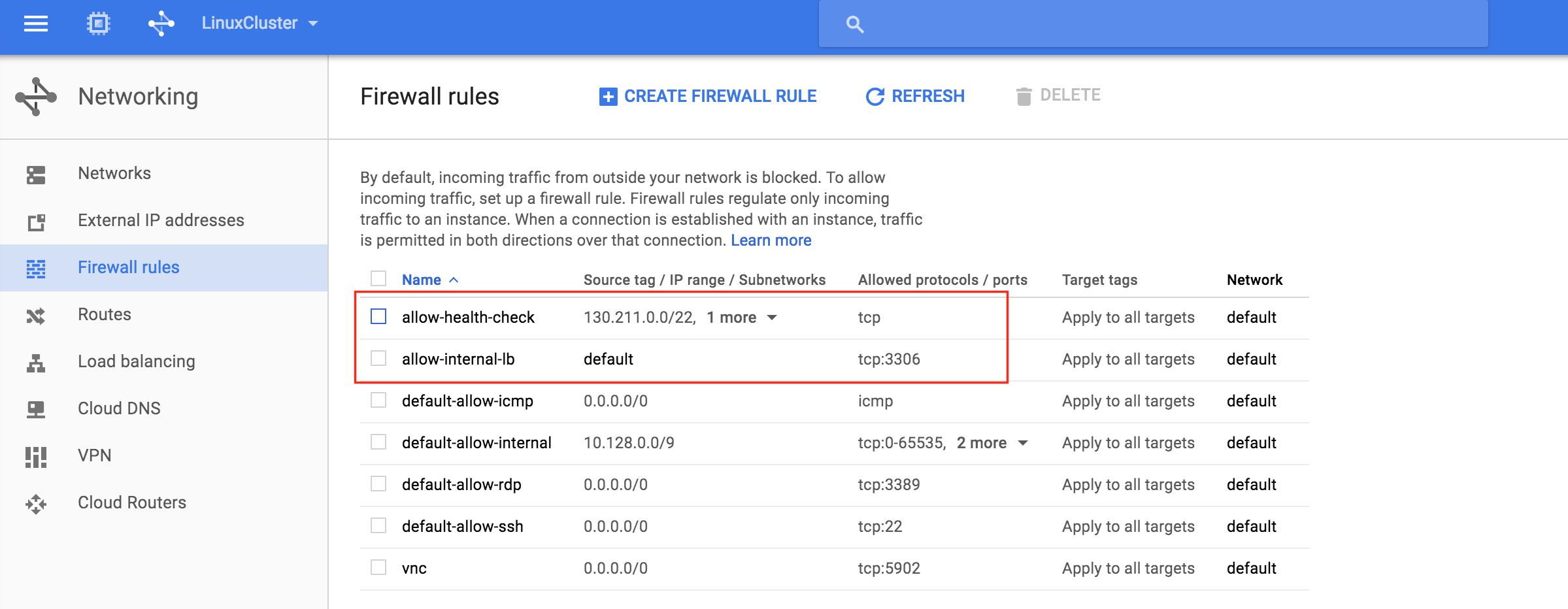
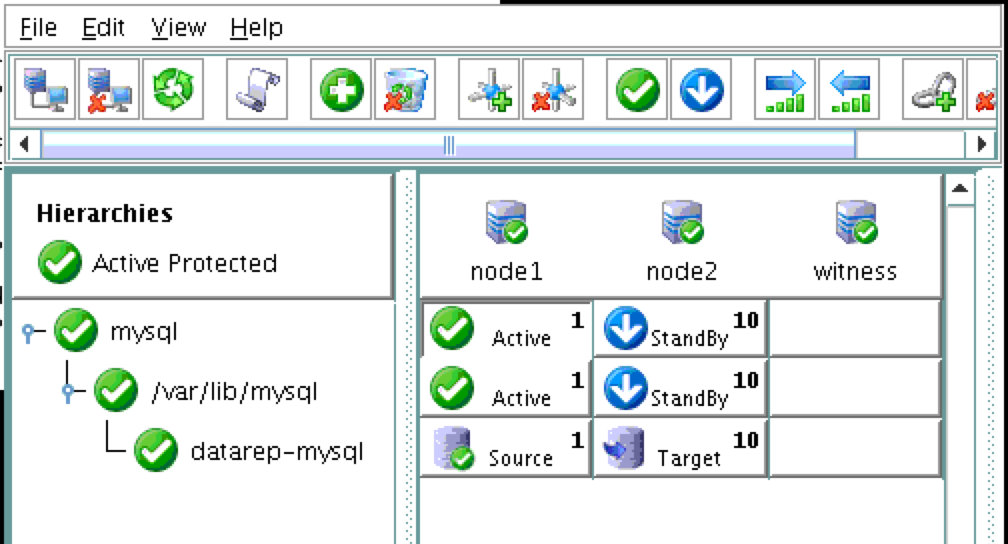
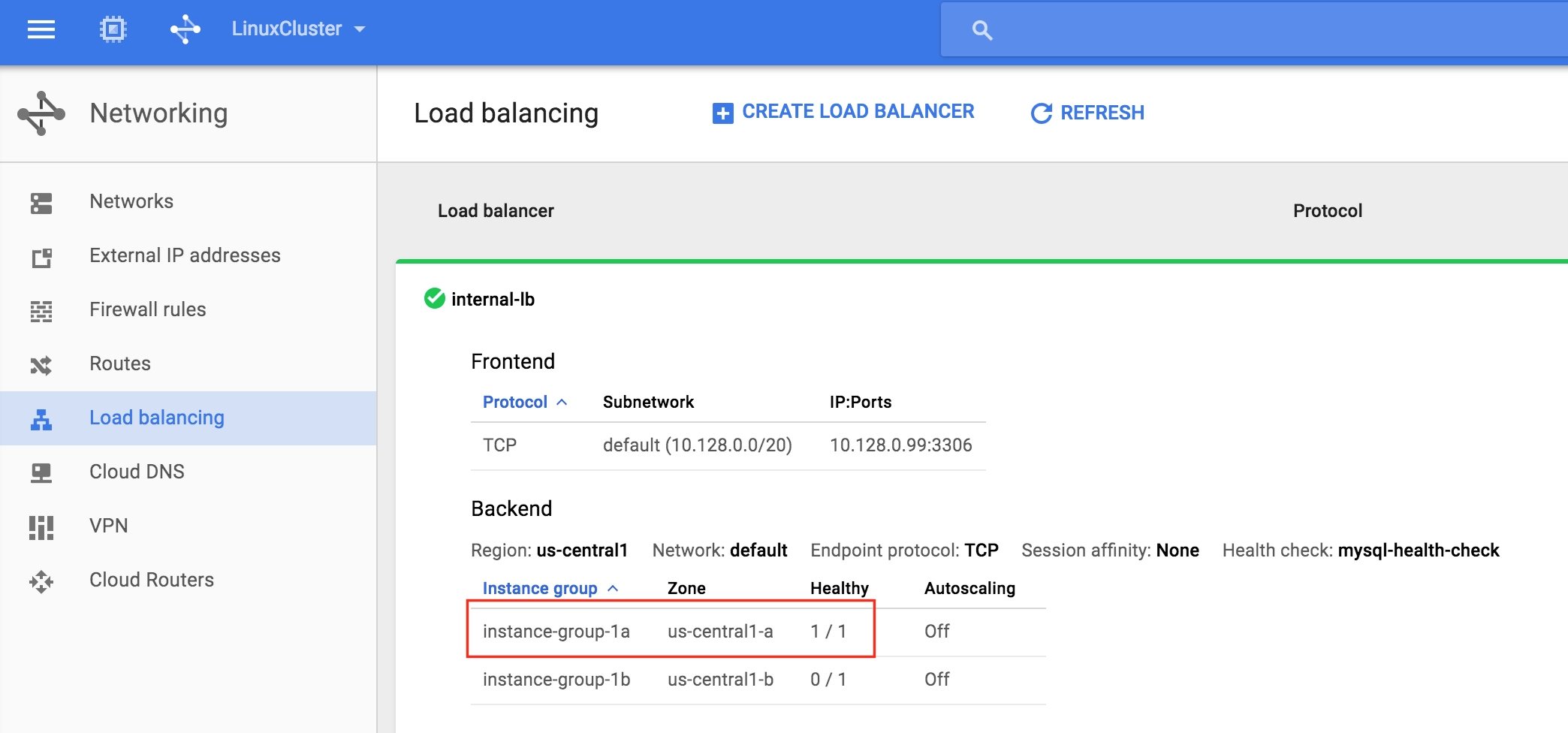
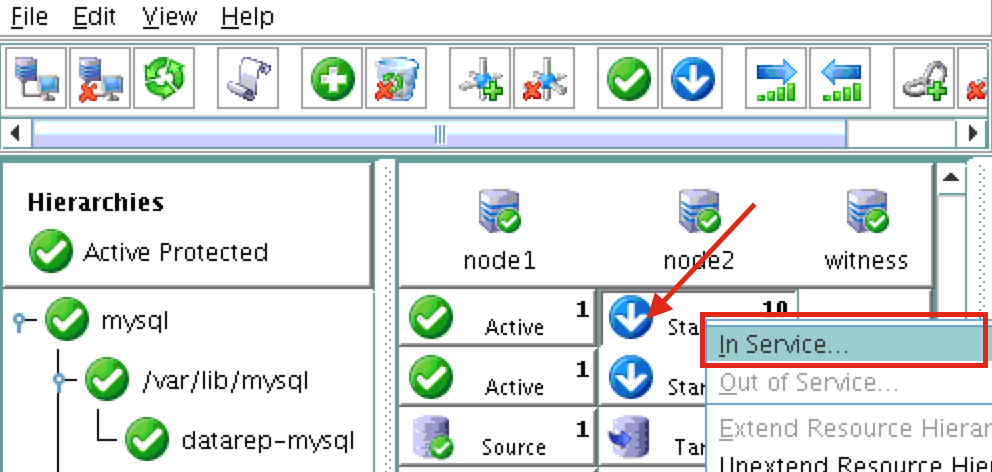
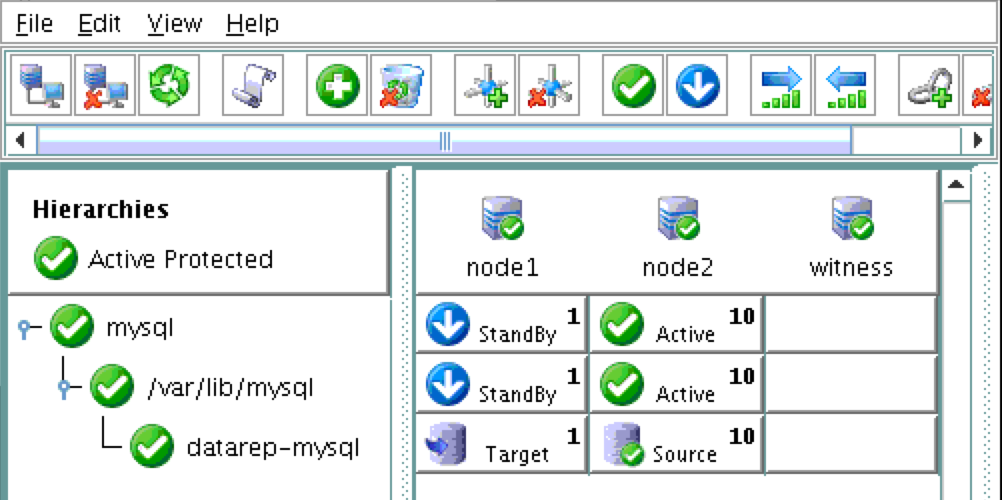
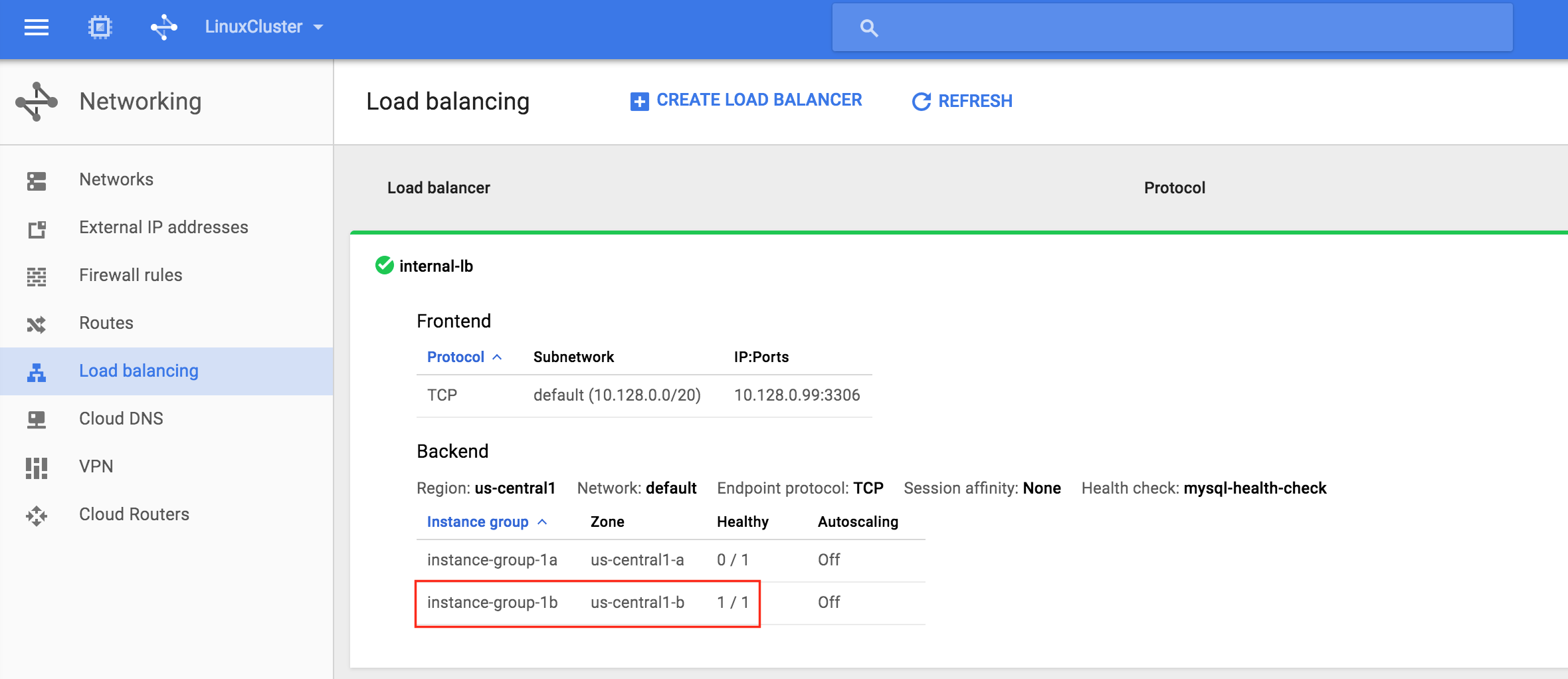
기본적으로 DataKeeper를 사용하는 SANLess SQL Server 장애 조치 (Failover) 클러스터 인스턴스는 Always Availability Group Wizard와 관련하여 SQL Server의 단일 인스턴스처럼 보입니다. Always On AG의 구성은 두 개의 독립 실행 형 (클러스터되지 않은) SQL Server 인스턴스간에 Always On AG 만 작성한 경우와 완전히 동일합니다. 이 구성에서 모든 서버가 동일한 장애 조치 (failover) 클러스터에 있다는 사실에 혼란이 생깁니다. 그러나 SQL Server FCI는 SQL Server가 클러스터 된 SQL Server 인스턴스로 설치된 클러스터 노드에서만 실행되도록 구성됩니다. 다른 노드는 동일한 클러스터에 있습니다. 그러나 SQL은 이러한 노드에 클러스터 된 인스턴스가 아닌 독립 실행 형 SQL Server 인스턴스로 설치됩니다. 다소 혼란 스럽습니다. 근본적으로 일어나는 일은 Always On AG가 WSFC 쿼럼 모델과 청취자를 활용한다는 것입니다. 이와 같이 모든 AG Replicas는 일반적으로 SQL Server의 클러스터 된 인스턴스를 실행하지 않더라도 동일한 WSFC에 있어야합니다. 당신이 완전히 혼란스러워해도 괜찮다면, 대부분의 사람들은 처음에이 하이브리드 구성 주위에서 머리를 감싸려고 할 때 혼란 스럽습니다. 이와 같은 구성의 실질적인 이점은 SQL Server 장애 조치 (Failover) 클러스터 인스턴스가 많은 환경에서 Always On AG보다 더 우수하고 비용 효율성이 높은 고 가용성 솔루션이 될 수 있지만 읽을 수있는 보조 복제본. 항상 읽기 가능한 보조 복제본을 추가하면이 필요성을 해결할 수있는 실행 가능한 옵션이됩니다. 또한 SIOS DataKeeper를 사용하면 SQL Server FCI 용 SAN이 필요하지 않으므로 노드가 다른 데이터 센터에있는 SQL Server FCI를 구성 할 수 있으며 Azure 및 SQL Server의 가용성 영역에 해당하는 SQL Server FCI도 지원됩니다. AWS. 아래 그림은 한 가지 가능한 구성 일뿐입니다. 다중 FCI 클러스터 노드, 다중 AG 및 다중 복제본이 모두 지원됩니다. SQL Server 버전에 따른 제한으로 인해 제한됩니다. 이 기사에서는 설치 단계를 문서화하는 것으로 보인다. 물론 여기서는 SQL FCI 용 공유 저장 장치 대신 SIOS DataKeeper를 사용하여 FCI를 작성합니다.
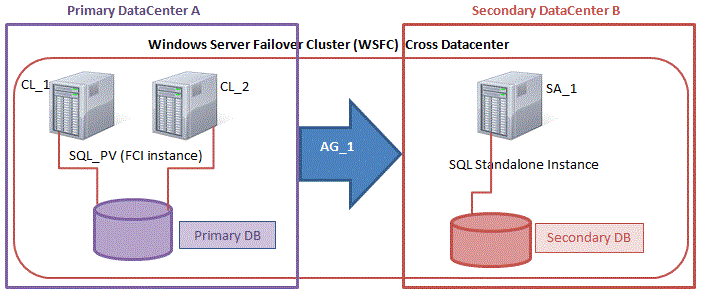
기본 가용성 그룹
SQL Server Standard Edition에서 "기본 가용성 그룹"을 축소하여 SQL Server Standard Edition에서도이 구성을 가능하게했습니다. 기본 AG는 가용성 그룹당 단일 데이터베이스, 단일 복제본 (2 노드)으로 제한됩니다. 그러나 읽기 가능한 보조 복제본을 지원하지 않으므로이 하이브리드 구성의 사용 사례가 매우 제한적입니다.
분산 가용성 그룹
SQL Server 2016에 도입 된 분산 형 AG는이 하이브리드 구성에서도 지원됩니다. 분산 AG는 일반 AG와 매우 유사하지만 복제본은 동일한 클러스터 또는 동일한 Windows 도메인에있을 필요가 없습니다. Microsoft는 다음과 같이 분산 가용성 그룹의 주요 사용 사례를 문서화합니다.
- 재해 복구 및보다 쉬운 다중 사이트 구성
- 새 하드웨어 또는 구성으로 마이그레이션 (새 하드웨어 사용 또는 기본 운영 체제 변경 포함)
- 여러 가용성 그룹에 걸쳐 단일 가용성 그룹에서 판독 가능한 복제본 수를 8 개 이상으로 늘림
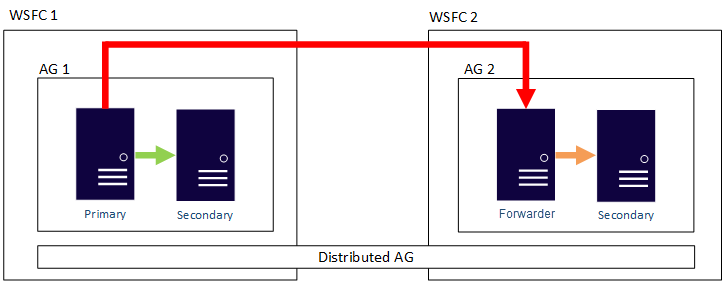
개요
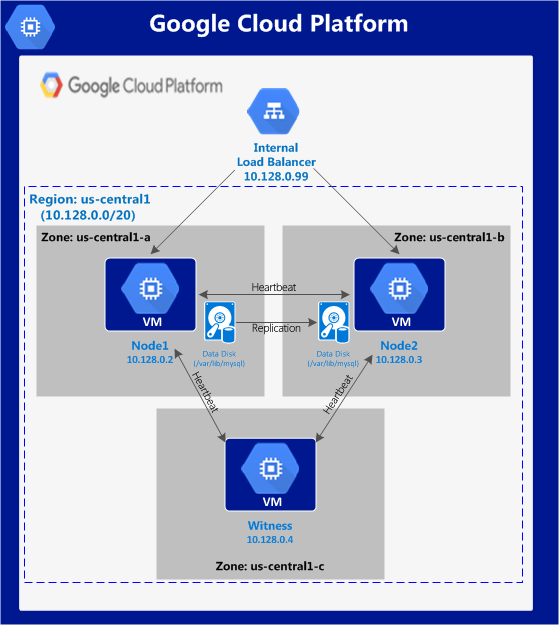
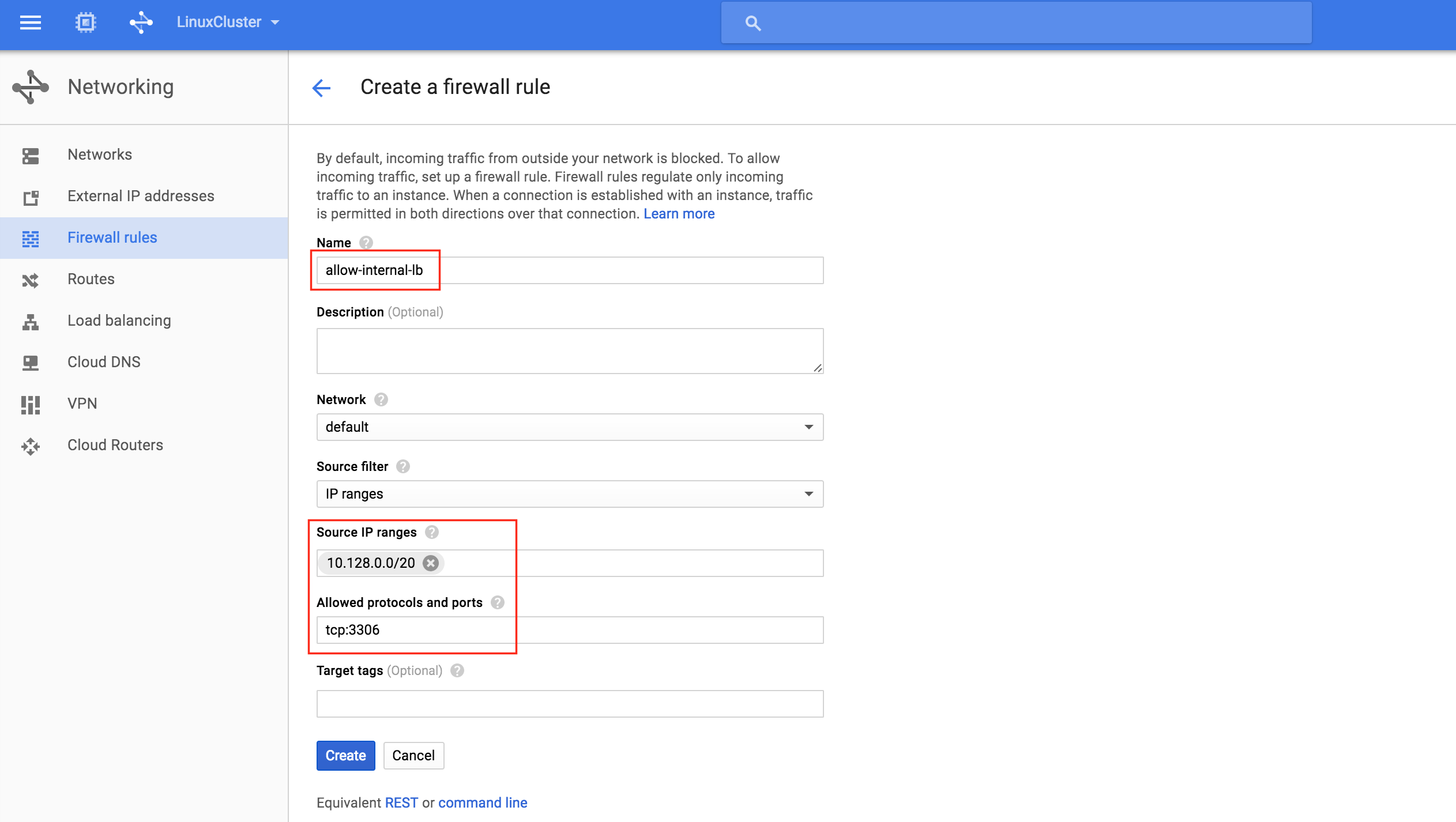
SQL Server 고 가용성을위한 SQL Server FCI에 대한 아이디어가 마음에 들면 읽기 전용 보조 복제본의 유연성을 원한다면이 하이브리드 솔루션이 당신이 찾고있는 것일 수도 있습니다. 전통적인 SAN 기반 SQL Server FCI 및 심지어 S2D (Storage Spaces Direct) 기반 FCI는 단일 데이터 센터로 제한됩니다. SIOS DataKeeper는 SAN 한계에서 벗어나 가용 영역 또는 클라우드 지역에 적용되는 SQL Server FCI와 같은 구성을 가능하게합니다. 또한 SAN에 의존하지 않으므로 SQL Server 장애 조치 (Failover) 클러스터 인스턴스를 포기하지 않고도 로컬로 연결된 고속 저장 장치를 활용할 수 있습니다.
* 돈을 저축하는 방법
앞서 SQL Server Standard Edition으로이 모든 작업을 수행하여 비용을 절감하는 방법을 알려 드리겠다고 약속했습니다. 특정 시점의 스냅 샷인 읽을 수있는 복제본으로 살아갈 수있는 경우 Always On AGs를 완전히 건너 뛸 수 있으며 SIOS DataKeeper 대상 측 스냅 샷 기능을 사용하여 진행중인 복제에 영향을주지 않으면 서 대상 서버의 볼륨 스냅 샷을 주기적으로 응용 프로그램에 적용 할 수 있습니다 또는 가용성. 방법은 다음과 같습니다.

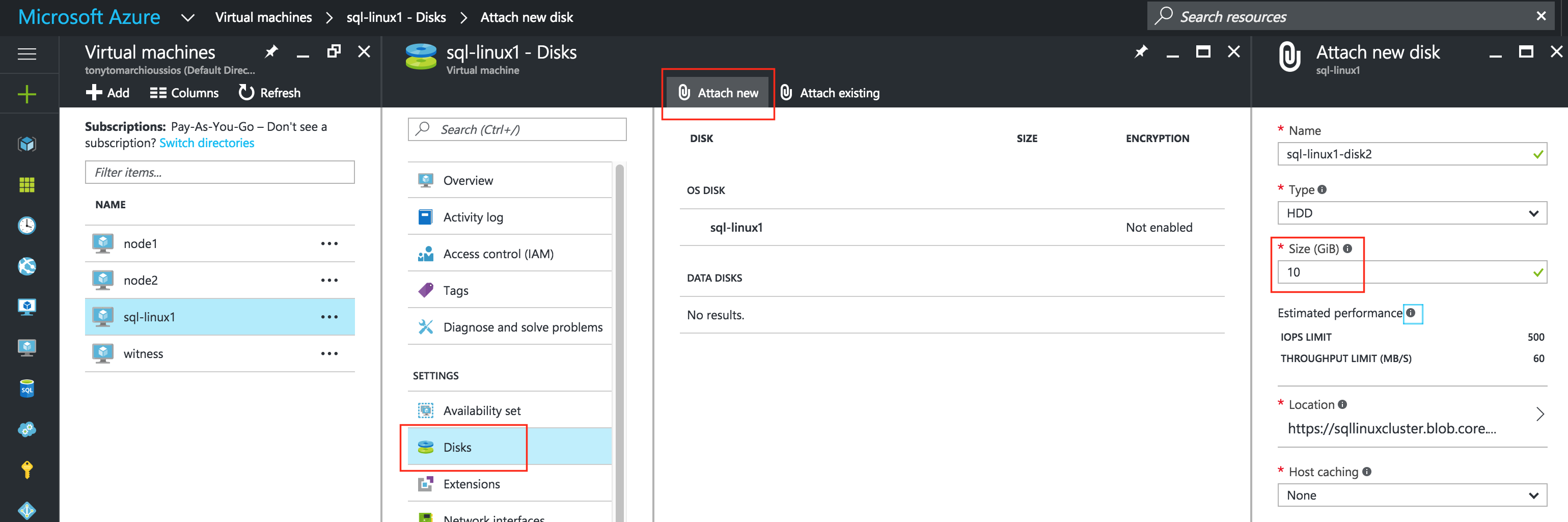
SQL Server Standard Edition으로 2 노드 SQL Server FCI를 만들고 SQL 라이센스에 많은 비용을 절약하십시오. 또한보고 또는 DR 목적으로 클러스터 외부의 세 번째 노드에 데이터를 복제합니다. 이 세 x 째 서 v에서 볼륨의 스 냄샷을 작성할 경우이 스 냄샷은 읽기 쉽게 액세스 할 수 있습니다. 이렇게하면 SQL Server의 독립 실행 형 인스턴스에서 해당 데이터베이스를 탑재하여 월말 보고서를 실행하거나 아카이브로 복사하거나 해당 스냅 샷을 사용하여 QA 및 Test / Dev 환경을 최신 SQL로 쉽고 빠르게 업데이트 할 수 있습니다 데이터. 항상 가용성 그룹과 SANless SQL Server 장애 조치 (Failover) 클러스터 인스턴스를 함께 사용하여 SQL Server 고 가용성, 재해 복구를 달성하기위한 가이드를 찾았다면 좋겠습니다.

 구성 [/ caption]
구성 [/ caption]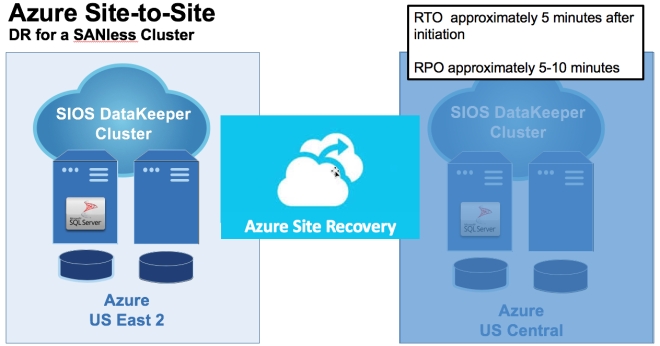 th = "660"] HA 용 SIOS DataKeeper 및 DR 용 Azure 사이트 복구를 활용하는 일반적인 구성 [/ caption]
th = "660"] HA 용 SIOS DataKeeper 및 DR 용 Azure 사이트 복구를 활용하는 일반적인 구성 [/ caption]