| February 13, 2024 |
The Challenges of Using Amazon EBS Multi-Attach for Microsoft Failover Clusters |
| February 5, 2024 |
Video: Application High Availability Will Become Universal | Predictions From SIOS Technology Video: Application High Availability Will Become Universal | Predictions From SIOS TechnologySIOS Technology is a high availability (HA) and disaster recovery (DR) solutions company providing application availability for critical mission-critical databases, applications, and services for their customers across Windows and Linux systems, and a variety of cloud platforms. Cassius Rhue, VP of Customer Experience at SIOS Technology, shares his 2024 predictions. As reliance on applications continues to rise, there will be increasing pressure on IT teams to deliver efficient high availability and disaster recovery for applications that were traditionally considered non-essential in addition to mission-critical ones. Due to this shift, we will likely see an expansion of high-availability software solutions and services to meet this expectation. With more companies expanding into the cloud and across different operating systems, more teams are also expected to cover a diverse set of operating systems, applications, and cloud platforms. Teams will be looking for applications and solutions that are consistent across these different operating systems and cloud environments to reduce complexity and improve cost efficiency. HA solutions will also need to be consistent across the operating systems and cloud environments and we will see a drive toward cloud-agnostic HA. Companies need HA and DR solutions to be simple, automated, quick, and intelligent. As more organizations are migrating to the cloud, they will need to ensure they do not lose data in the process. HA solutions will need to bridge the gap between the old systems and the more modern ones. 2024 will see an increased focus on data retention, security access controls, and permissions prompting organizations to integrate more enhanced security measures into their high availability and disaster recovery solutions, services, and strategies. As the volume of data that is being collected continues to increase, organizations will also need more information about why failures have occurred. Automation and orchestration tools will likely play a central role in streamlining root cause analysis and providing intelligent responses. SIOS Technology will continue to focus on its customers in the coming year, helping them avoid and reduce downtime, and ensuring their data and applications are available when the business needs them most. The company will continue to optimize its solution, providing additional adjacent services to benefit their customers, as well as, helping application providers and cloud providers form an effective HA strategy. Reproduced with permission from SIOS |
| February 2, 2024 |
Mitsubishi Motors Moves Critical Systems to the Cloud with LifeKeeper for High Availability Protection |
| January 30, 2024 |
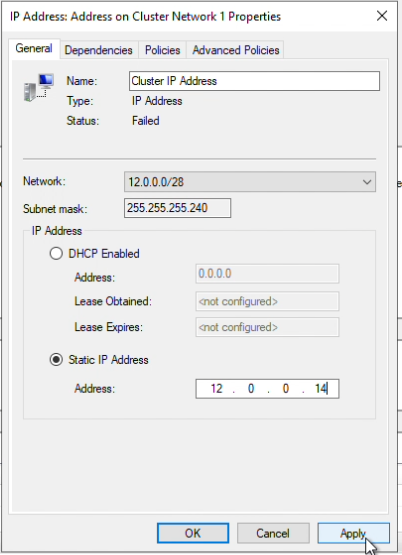
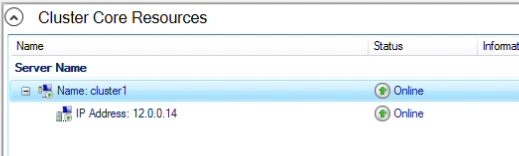
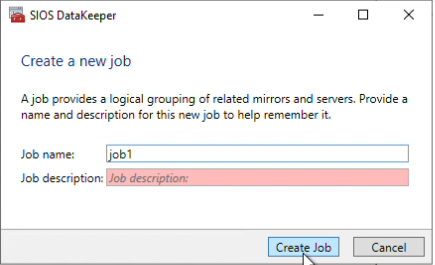
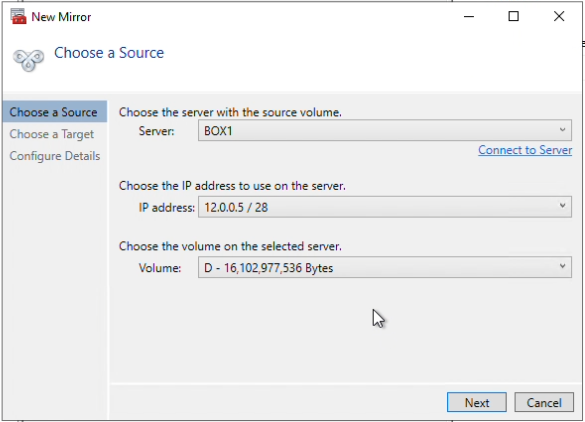
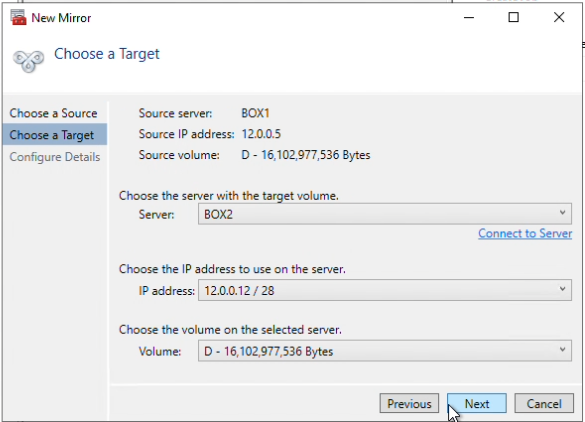
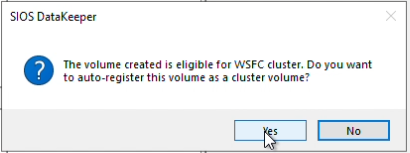
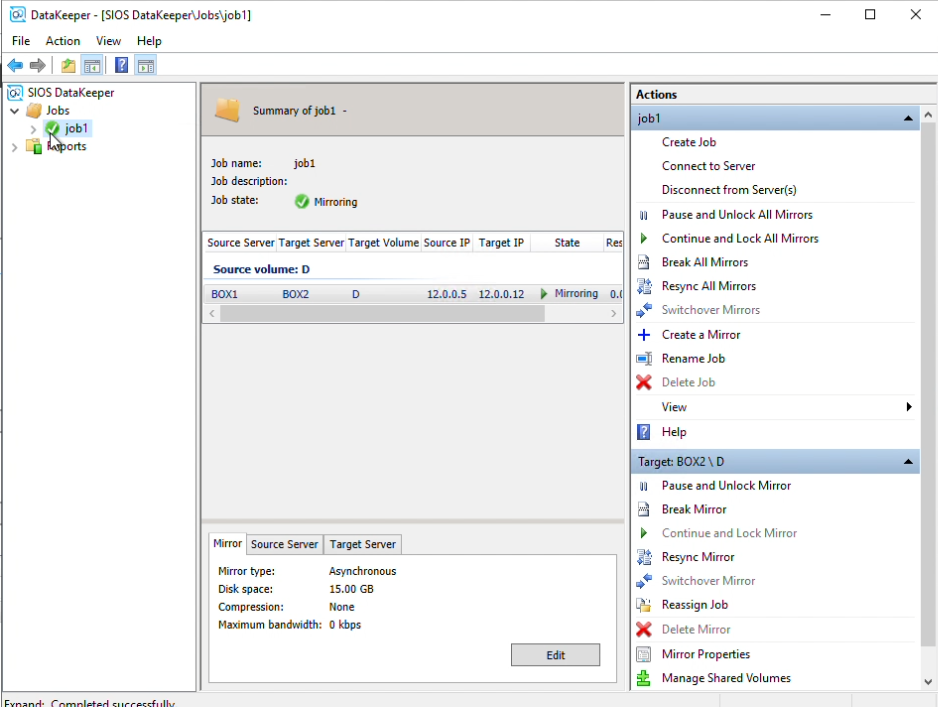
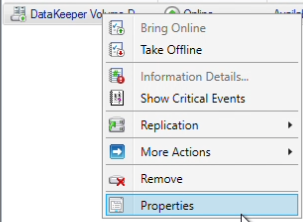
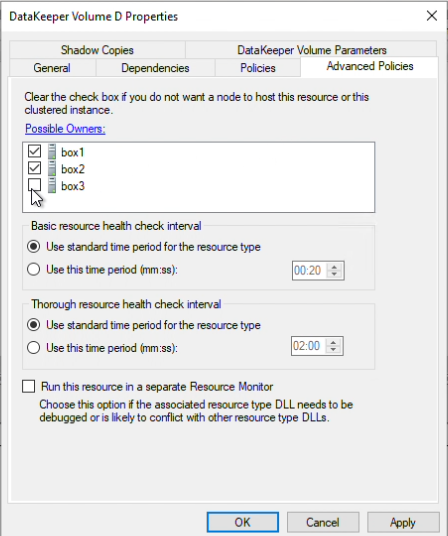
How to Set Up a DataKeeper Cluster Edition (DKCE Cluster) |
| January 24, 2024 |
Ensuring Access To Critical Educational Applications |