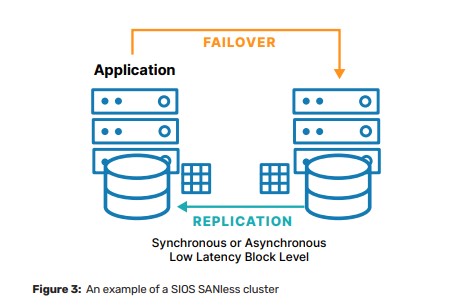
8 Changes That Can Undermine Your High Availability Solution
As VP of Customer Experience I have observed that most organizations are conscious and careful of deploying any tools or processes that could have an impact on their businesses’ high availability. These companies typically go through great care with regards to HA including strict change vetting for any HA Clustering, DR, Security, or Backup solution changes. Most companies understand changes to these tools needs to be carefully considered and tested so as to avoid impact to the overall application availability and system stability. IT administrators are aware that even the most inconspicuous change in their HA Clustering, Disaster Recovery, Security, or Backup solution can lead to a major disruption.
However, changes in other workplace and productivity tools are most often not considered with the same diligence.
Eight changes that can be undermining your HA solution:
- Lost Documentation
Your existing tools often encapsulate a lot of documentation around the company, decisions, integrations, and overall HA architecture. As teams transition to new tools, these documents are often lost, or access becomes blocked or hampered.
Suggested Improvement: Export and import all existing documents into the new tool. Use archive storage and backups to retain complete copies of the data before the import.
- Lost Requirements
Similar to the lost documents, requirements are often the first thing to be lost when transferring tools.
Suggested Improvement: Document known requirements, export requirements related documents from any existing productivity tools.
- Lost History and Mindshare
Almost as important as the documentation and requirements is the history behind changes, revisions, and decisions. Many organizations keep historical information within workplace and office productivity tools. Such information could include decisions around tools and solutions that have been previously evaluated. When these workplace tools are changed or transitioned, this type of history can be lost. Existing tools often have a lot of tacit knowledge involved with them as well. As the new tools are integrated, that knowledge and mindshare disappears. Two decades ago our team migrated bug tracking solutions. The knowledge gap between the tools was huge and impacted multiple departments, including the IT team now tasked with managing, backing up, and resolving issues.
Suggested Improvement: Be sure to adequately train and transfer mindshare and knowledge between new tools. Be sure that history, context and decisions around the current tools and previous tools are documented before terminating the current tool
- Lost Access / Access control
Every new tool has a different set of security and access rules. Often in the transition teams end up with too many admins, not enough admins, or too many restrictions on permissions.
Suggested Improvement: Map access and user controls, based on requirements and security rules, in advance and have a process for quick resolution.
- Lost Contacts
Email and contact system migrations are rarely seamless. Even upgrades between existing versions can have consequences. One downside of a migration from one tool (Exchange to Gmail) could be lost contacts. Our team worked with a customer who once called our support team for help obtaining their partner contacts. Their transition for email systems had stalled and access to critical contacts was delayed.
Suggested Improvement: Plan for contact migration and validation. Be sure that any critical contacts for your HA cluster are definitely a part of a validated migration step.
- Broken integration
Broken integrations is a very common item that impacts high availability, monitoring and alerting. As companies move towards newer productivity tools, existing integrations may no longer work and require additional development. As a relative example, a company previously using Skype for messaging, moved away to Slack. Many of the tools that delivered messages via Skype needed to be adjusted. In your HA environment, a broken integration between dashboards or alert systems could mean critical notifications are not received in a timely manner.
Suggested Improvement: Map out any automated workflows to help identify integration points between tools. Also work to identify any new requirements and integration opportunities. Plan and test integrations during the proof of concept or controlled deployment phase.
- Lost Champions
Every tool set has a champion and a critic. The champion may or may not be the same as your administrator. The role of the champion changes within each organization and often with each tool, but what is common among them is their willingness to address issues, problems, or challenges with the new productivity tool for the benefit of themselves and others. The champion is the first to find the new features, uncover and report new issues, and help onboard new people to the toolset. Champions go beyond mindshare and history. Often with the changing of tool sets, your team will lose a champion.
- Lost Productivity
New tools, even those not directly related to HA have an impact on your team’s productivity. Even tools related to priority management, development and code repositories require ramp up and onboarding time. This time often translates into lost productivity, which can translate into risks to your cluster. Make sure your processes related to all of the existing and new tools are documented well so that the change to a new tool does not cause confusion, break process flow and lead to even greater losses of productivity.
Suggested Improvement: Reduce the risk of lost productivity by using training tools, leveraging a product champion, and making sure that rollout focuses on shortening the learning curve
Changing workplace productivity tools so that you don’t undermine your high availability solution requires capturing requirements, identifying key documents, transferring mindshare, mapping dependencies, testing and configuring proper access, identifying a toolset champion. It’s making sure that your new tools actual improve productivity rather than pull your key resources away from maintaining uptime.
Cassius Rhue, VP Customer Experience
Reproduced with permission from SIOS