What is “Split Brain” and How to Avoid It
As we have discussed, in a High Availability cluster environment there is one active node and one or more standby node(s) that will take over service when the active node either fails or stops responding.

This sounds like a reasonable assumption until the network layer between the nodes is considered. What if the network path between the nodes goes down?
Neither node can now communicate with the other and in this situation the standby server may promote itself to become the active server on the basis that it believes the active node has failed. This results in both nodes becoming ‘active’ as each would see the other as being dead. As a result, data integrity and consistency is compromised as data on both nodes would be changing. This is referred to as “Split Brain”.
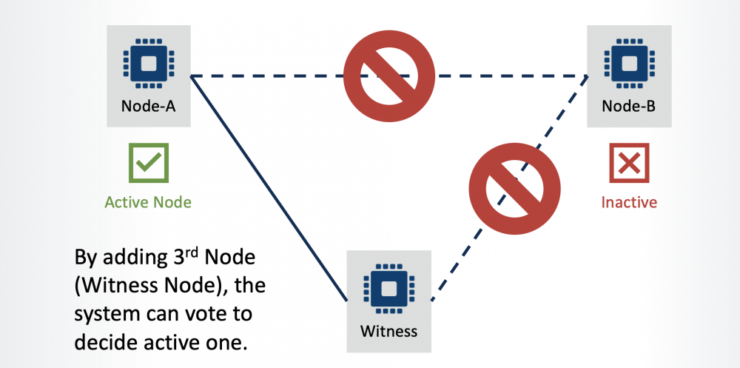
To avoid a split brain scenario, a Quorum node (also referred to as a ‘Witness’) should be installed within the cluster. Adding the quorum node (to a cluster consisting of an even number of nodes) creates an odd number of nodes (3, 5, 7, etc.), with nodes voting to decide which should act as the active node within the cluster.
In the example below, the server rack containing Node B has lost LAN connectivity. In this scenario, through the addition of a 3rd node to the cluster environment, the system can still determine which node should be the active node.
Quorum/Witness functionality is included in the SIOS Protection Suite. At installation, Quorum / Witness is selected on all nodes (not only the quorum node) and a communication path is defined between all nodes (including the quorum node).
The quorum node doesn’t host any active services. Its only role is to participate in node communication in order to determine which are active and to provide a ‘tie-break vote’ in case of a communication outage.
SIOS also supports IO Fencing and Storage as quorum devices, and in these configurations an additional quorum node is not required.