
Failover Cluster
Failover Cluster Software Solutions: What You Need to Know
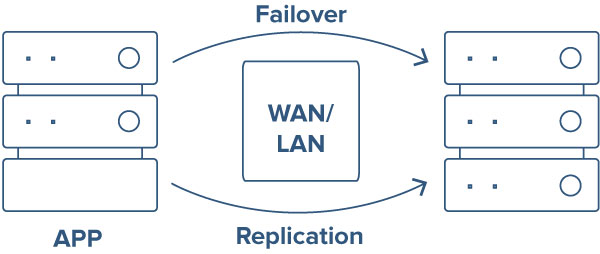
What is Failover?
The “Tell All” on Failover
Failover is the process by which a standby, redundant system, database, or network assumes operations when the primary system, database, or network fails, or primary operations are abnormally terminated. Hot failover is one of the key design principles incorporated into high availability and disaster recovery systems.
RTO is the maximum tolerable duration of any outage. Online transaction processing applications generally have the lowest RTOs, and those that are mission-critical often have an RTO of only a few seconds.
RPO is the maximum amount of data loss that can be tolerated when a failure happens. For HA, RPO is often zero to specify there should be zero data loss under all failure scenarios
Let’s Understand Failover
First, we need to discuss the difference between cold, warm, and hot standby servers:
- A cold server (sometimes referred to as a cold failover) is one that is not connected to the primary server but is available and turned on only when the primary server goes down. With a cold server, it can take considerable time to power up the standby server, which may require an updated configuration and software. This means that Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) are the longest. Cold failover is considered unacceptable for mission-critical applications.
- A warm server/failover is one that periodically receives updates from the primary server through data replication and mirroring.
- A hot server/failover is one that receives regular updates from the primary server and is immediately available to take over in the event of a failover. Hot failover is the most resource-intensive, results in zero data loss (zero RPO) and RPOs of no more than a few minutes and is required to support high availability for mission-critical applications.
SIOS Failover Cluster Software supports hot failovers, delivering a zero RPO and an RTO of milliseconds for high availability. The results: a system failure results in no data loss and is transparent to the user.
SIOS Failover Cluster Software
SIOS offers failover cluster software so you can build a traditional shared storage cluster for high availability or a SIOS SANless cluster that uses local storage. SIOS software uses real-time synchronous (for LAN environments) or asynchronous (for WAN environments) data replication to synchronize storage.
SIOS solutions provide high availability and disaster recovery with a single solution. This approach eliminates the cost and complexity of SAN-based replication. With the ability to replicate to multiple targets, you can configure a multi-node failover cluster with nodes located in multiple locations to protect your systems from disasters.
With SIOS clusters, you can replicate between the configurations of your choice – between SAN and SANless environments and any combination of physical, virtual, cloud, and hybrid configurations. In fact, SIOS clustering solutions are unique in the breadth of operating systems, applications, and infrastructure environments supported, including Windows, Linux, SAP, SQL Server, Oracle, AWS, Azure, and Google cloud platforms.
In a Windows environment, SIOS DataKeeper gives you the flexibility to build a Windows cluster in any combination of physical, virtual, and cloud environments. SIOS DataKeeper Cluster Edition seamlessly integrates with and extends Windows Server Failover Clustering (WSFC) by providing a performance-optimized, host-based data replication mechanism.
In a Linux environment, SIOS LifeKeeper and SIOS DataKeeper provide a tightly integrated combination of high availability failover clustering, continuous application monitoring, data replication, and configurable recovery policies, protecting your business-critical applications from downtime and disasters.
Let’s review one case study that talks to the benefits of one of SIOS’ solutions – SIOS DataKeeper.
A SIOS Failover Cluster Software Solution in Action
Located in The Netherlands, Van de Lande BR (VDL) manufactures a wide range of PVC and PE compression fittings and valves. Their products are used all over the world in industrial and technical installations. Manufacturing more than 4500 different products, VDL is deeply committed to product improvement and quality, making their brand the choice for builders of systems and installations for more than 50 years.
VDL has a Hyper-V environment, solid state disk (SSD) storage, and its business relies heavily on its ERP solution. With only one data processing system in place, VDL was exposed and needed a disaster recovery (DR) solution to ensure the protection and availability of its ERP, web services, and other mission-critical systems in the event of a disaster.
To deliver immediate failover and DR protection, VDL built a Windows Server Failover Clustering (WSFC) system, with one node replicating data to the other node. If the primary node fails, WSFC transfers all operations to the standby node, giving users continuous access to applications and data.
VDL also chose SIOS DataKeeper Cluster Edition to provide DR for its Hyper-V virtual machines (VM). SIOS DataKeeper is a software add-on that provides uninterrupted data access. It seamlessly integrates with WSFC to add performance-optimized, host-based, synchronous or asynchronous real-time replication of Hyper-V VMs between physical servers across both LAN and WAN connections. Working with WSFC, SIOS DataKeeper monitors the system and application health, maintains client connectivity, and makes it possible to create SANless clusters. Unlike a SAN, a SANless cluster eliminates single points of failure and reduces the cost and complexity of deploying clusters.
SIOS DataKeeper also uses WSFC to provide system administrators with a familiar and application-agnostic HA/DR solution, thereby dramatically simplifying implementation and operation.
VDL deployed two SIOS DataKeeper clusters; one two-node cluster works as a file server and iSCSI server while the other supports a SQL Server (ERP) cluster and Dynamics NAV web services. The implementation took less than one day. During the system failover test, the network services team failed over and failed back the system quickly and easily. After a thorough evaluation of the VDL server configuration and the completion of testing, the installation team confirmed that SIOS DataKeeper and a SANless cluster met all their criteria for disaster recovery, performance, and high availability of their ERP system, web services, and other mission-critical applications. The organization no longer risks data loss in the event of a failure.
One Last Thing
In addition to testing SIOS, VDL tested other solutions with unacceptable results. Comments Maurits van de Lande, ICT Manager at VDL, “We have tested our file server with both DFS replication and AlwaysOn technology. Neither delivered an automated disaster recovery solution to match SIOS DataKeeper, which fully addresses our DR requirements.”
———————————————————————————————————————————-
Regardless of your IT environment, your organization can reap the benefits of SIOS DataKeeper Cluster Edition and DataKeeper Standard Edition, both of which provide configuration flexibility, reduce data transfer costs, eliminate single points of failure, reduce complexities, and optimize network performance.
For more information, contact us or request a free trial.
References:
- https://nilebride.wordpress.com/2011/07/24/log-shipping-vs-mirroring-vs-replication/
- https://techdifferences.com/difference-between-mirroring-and-replication.html
- https://docs.microsoft.com/en-us/windows-server/failover-clustering/failover-clustering-overview
Reproduced from SIOS


 How to Achieve High Availability with Clusters
How to Achieve High Availability with Clusters