Reducing downtime for WordPress sites hosted on Amazon EC2
Going from ignorance to bliss with SIOS AppKeeper
WordPress is an open-source content management system (CMS) used by millions of companies to create websites, blogs, or apps. According to estimates, there are over 75 million websites today that use WordPress and many companies are beginning to host their WordPress instances on Amazon EC2. Users love WordPress for its flexibility and the ease with which you can create and modify layouts. If you are using WordPress for your website, then you are in good company.
With so many users relying on WordPress to power their websites, you can imagine that there is a rich set of third-party tools (plugins and services) designed to meet the needs of those users. Some of these plugins are to add security functionality, such as scanners to probe for vulnerabilities. Because more plugins can lead to more vulnerabilities.
Trust, but verify. Why monitoring WordPress uptime matters.
Deploying a website or application running on WordPress without monitoring it properly would be like leaving your car running outside with the keys in it. You’ll want to protect your investment. For companies managing WordPress sites (or any applications, for that matter), there are three primary reasons to monitor:
- To understand the visitors and optimize their experience;
- To monitor the speed of the site and ensure that it meets expected service level agreements (SLAs); and
- To ensure that you maximize uptime. Downtime can mean (serious) lost revenue for any e-commerce sites running on WordPress.
You believe your WordPress site is working properly, but you really want to know what is going on. The goal of monitoring should be to know quickly what is going on and why, allowing you to respond quickly to any issues.
There is a wide range of tools available to help WordPress users monitor their sites. Some are very focused on WordPress, such as ManageWP and JetPack, while others are industry-standard solutions that apply to many different CMSs and applications. Some go “deep” and are focused on one element of monitoring, such as Google Analytics and its focus on visitor analytics, while others try to go “broad” and address all three key aspects of monitoring. What you decide to use depends on your budget, your requirements, and your technical capabilities.
Here at SIOS, we believe that the best of breed approach makes sense. We focus on monitoring applications and ensuring that our customers’ experience as little downtime as possible with those applications. Many of our customers are using SIOS AppKeeper today to monitor and protect their WordPress sites running on Amazon EC2.
SIOS AppKeeper – simple but powerful monitoring and automated remediation for WordPress sites
Many WordPress monitoring solutions (from free plugins to low-cost freemium services) will tell you when your WordPress site is down. And depending on the sophistication (and cost) of your monitoring solution, it may tell you why your WordPress site is down. But will it help you reduce downtime and automatically restart your services or reboot your instances when downtime is experienced?
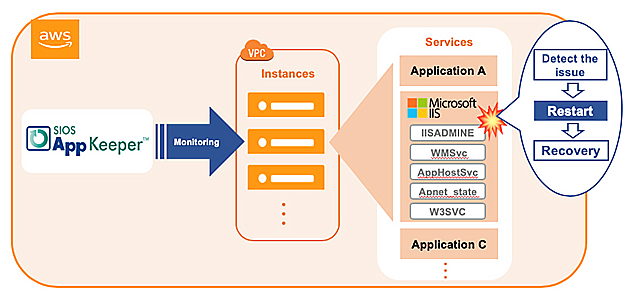
Many companies host their WordPress sites on Amazon EC2 using either Apache or NGINX webservers. SIOS AppKeeper is a SaaS service that can be configured to automatically discover WordPress sites or applications running on Amazon EC2 instances and their services, and then automatically take any number of actions if and when downtime is experienced. So instead of only getting alerts that something is wrong, you get notified that something happened and was automatically addressed.
Downtime matters. If you are running an e-commerce site using WordPress, then downtime will result in lost revenue. How much revenue? Simply divide your annual revenues by 365 days and 24 hours (Annual revenue/365/24) to understand your revenue per hour. In 2013 Google experienced a 5-minute outage that cost them $545,000 in revenue. Now, you may not be Google, but you certainly do want to eliminate downtime wherever possible.
Now imagine what happens when you receive an alert that your WordPress site is down. Are you ready to respond immediately? Do you know what should be addressed to get your WordPress site back up and running? According to our customer research, the average customer using only three Amazon EC2 instances experiences downtime at least once a month.
SIOS AppKeeper monitors Amazon EC2 and alerts you to any downtime AND takes action to remediate the situation, by either restarting your Amazon EC2 services or rebooting your instances.
AppKeeper addresses over 85% of our customers’ Amazon EC2 downtime issues automatically. This means that you get notified that a failure was identified and addressed, without you having to drop everything or lose any significant revenue.
Today hundreds of companies rely on AppKeeper to keep their cloud environments running. We invite you to check out the video below see how easy it is to install and use AppKeeper.

Video: Installing AppKeeper and recovering from AWS EC2 failures Demo
And if you like what you see, please feel free to sign up for a free 14-day trial of AppKeeper. AppKeeper starts at only US$40 per instance per month.
Reproduced with permission from SIOS