Integrate Storage Replication With Failover Clustering
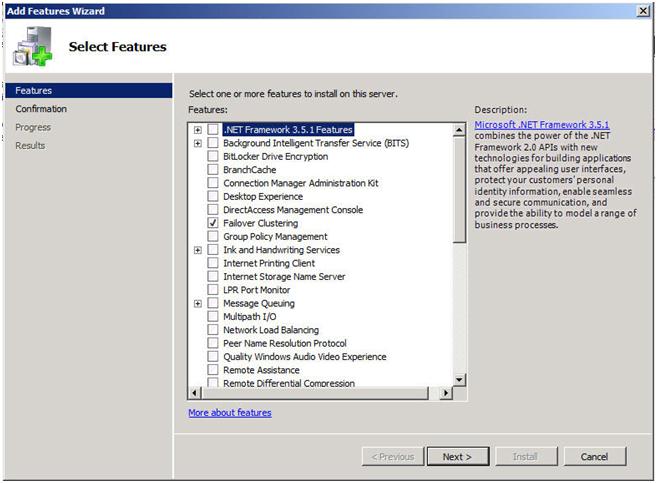
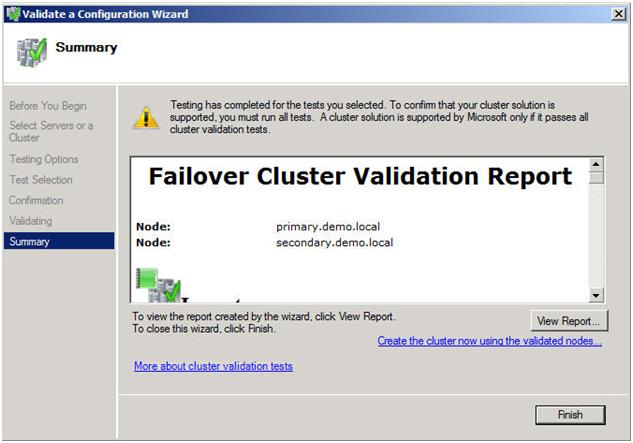
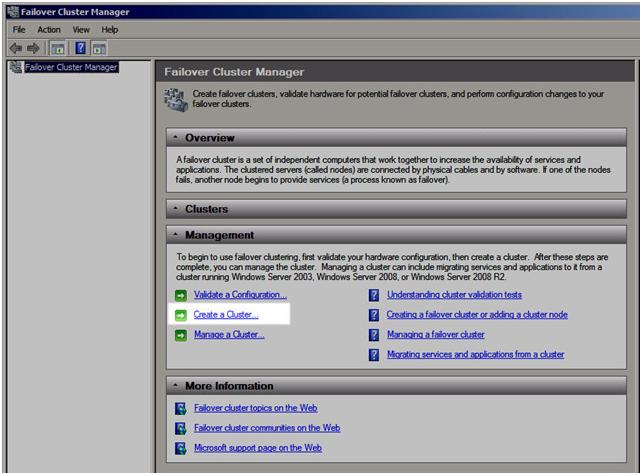
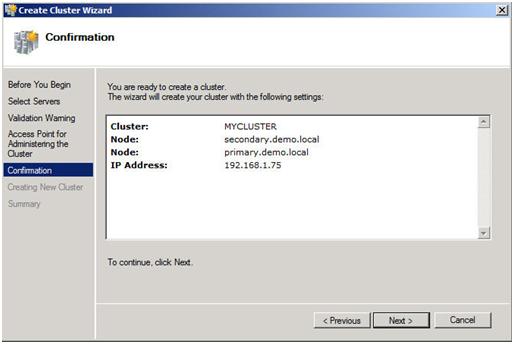
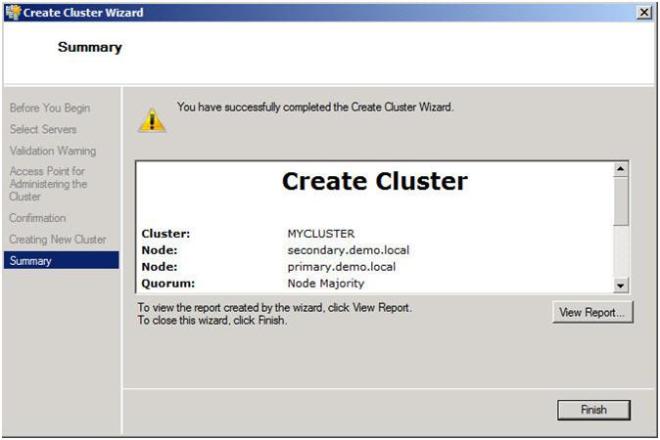
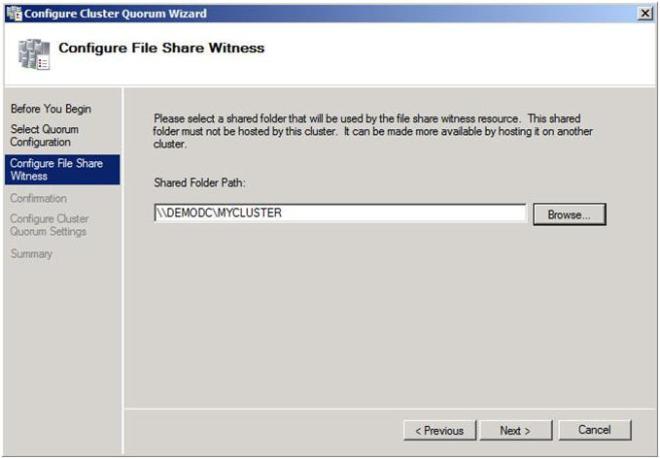
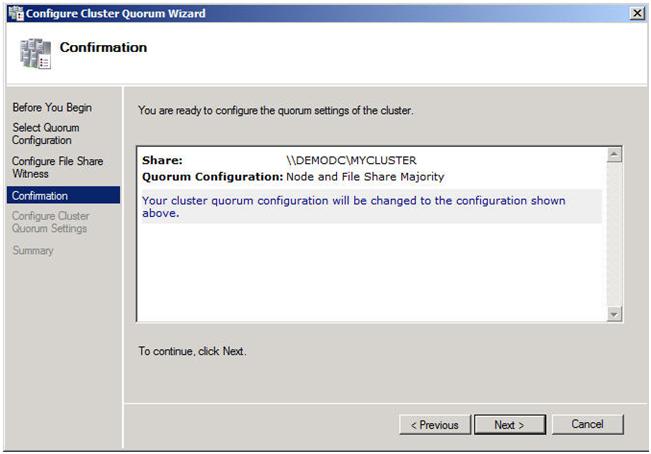
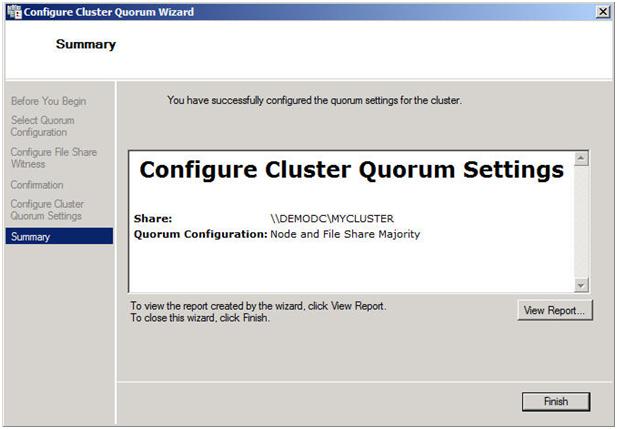
In Part 1 of this series, we took a look at the first steps required for building a multi-site cluster. We got to the point where we had a two node cluster that used a node and file share majority quorum, with no resources yet defined.
Let’s Continue
In this section we will start where we left off and look at how your replication solution will integrate with your failover clustering. Because each vendor’s replication solution will be implemented differently, it is hard to have one document that describes them all. The important thing to remember is that you want to purchase a replication solution that integrates with failover clustering and is certified by Microsoft. Your choices are basically array based, appliance based or host based replication solutions. EMC makes both appliance-based and array-based replication solutions and seem to do a great job at both. EMC’s John Toner maintains a blog that is dedicated to Geographically Dispersed Clusters and if you are going the EMC route, I’m sure he could lead you in the right direction. All the major vendors have solutions, you will just need to contact them to get the details.
SIOS DataKeeper
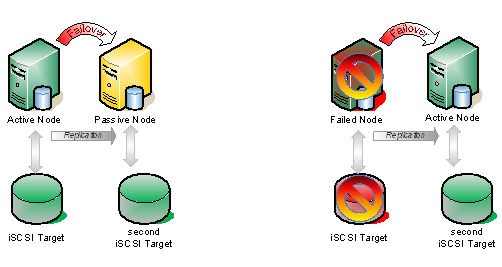
For this demonstration, I’m going to use a host based replication solution, SteelEye DataKeeper Cluster Edition, from my company, SteelEye Technology. It is so easy, that I thought instead of doing a long article, I would just record the steps and share it with you in a video. One of the advantages of host based replication is that you can utilize your existing storage, whether it is just some local attached disks, iSCSI or an expensive SAN. Host based replication can replicate across any storage devices.
Here is a summary of what you will see in the video.
-
Launch the SteelEye DataKeeper MMC Snap-in
- Create a new DataKeeper job, define mirror end points, network, compression, etc.
-
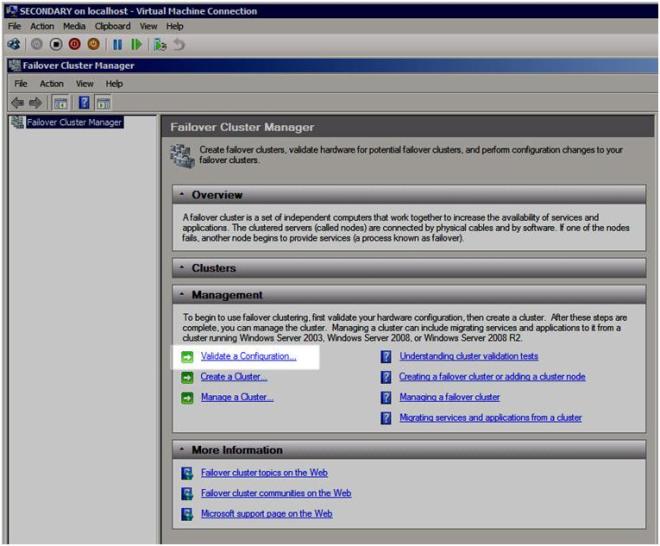
Launch the Failover Cluster MMC Snap-in
- Create a Hyper-V resource
- Add a DataKeeper Volume Resource
- Edit the properties of the DataKeeper Volume resource to associate it with the mirror created earlier
- Make the Virtual Machine configuration dependent upon the new DataKeeper volume resource
That’s it! You are now done. Sit back and enjoy your new Hyper-V multi-site cluster.
CLICK TO WATCH VIDEO
In Part 3 of this series, we will tackle SQL 2008 multi-site clusters on Windows Server 2008 R2. There are a few more steps and some tips and tricks you will definitely need to know, so make sure you check back to get all of the details. In the meantime, if you need assistance, leave me a comment or contact me through SIOS and I’d be glad to help you out.
Reproduced with permission from https://clusteringformeremortals.com/2009/09/18/step-by-step-configuring-a-2-node-multi-site-cluster-on-windows-server-2008-r2-%E2%80%93-part-2/