How to Perform Performance Testing Replication with SIOS DataKeeper
Configuring replication for a production database can be a pretty daunting task especially if you have not done your research in advance. This blog will cover many parts of the trickiest aspect of setting up your environment properly… performance. Understanding these key points will put you ahead of the pack and ensure your production Go-Live does not have any last minute hiccups.
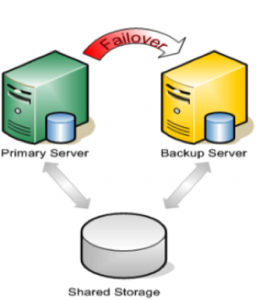
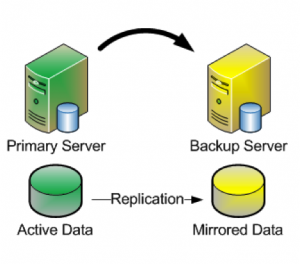
The first and most basic point to consider is choosing the correct mirror type for your configuration. SIOS DataKeeper comes with two options for mirror type during the creation process, Synchronous and Asynchronous. Either of these options have their own benefits and drawbacks depending on your environment.
Selecting Mirror Type
Synchronous mirrors excel best in LAN environments with high speed connections and provide 1:1 write consistency at time of commit to the primary system. However if the network, or target storage is unable to keep up with the throughput of the primary system you will see reduction in write speed to maintain synchronous write consistency. Therefore synchronous mirroring would not be recommended for WAN or high latency environments.
Asynchronous mirrors however are perfect for a WAN environment. Asynchronous mirrors provide all the same functionality of ensuring 1:1 write consistency between the nodes, but the difference is that writes are committed to the primary system before the write is committed to the target system. This is possible due to the utilization of a bitmap also known as an intent log, a bitmap tracks all of the changes that occur on the system at a block level and writes data to the target as quickly as it can through a backlog known as a write queue. The write queue can be limited by number of writes or total MB in data and when the limit is hit the mirror will pause and the data will sync, preventing a failover while the data is not in sync.
Hardware Configuration:
Now that you have decided which mirror type fits your environment best it is important to understand that DataKeeper is not magic, DataKeeper can only write and replicate as fast as your systems allow so having hardware capable of achieving the throughput needed by your applications is crucial. Here is some advice and tips for ensuring you have the hardware needed to achieve your replication goals.
- Ensure that your Primary and Target systems have identical storage hardware. For example target IOPS should be equal to the source IOPS. Otherwise the slowest component in the environment will prove to be the bottleneck of the write speed. Matching hardware will always provide better performance.
- Understanding the importance of the bitmap, the easiest and cheapest way to provide a significant boost in performance is to store the bitmap on its own dedicated high speed storage. The bitmap is very small so provisioning a 5 or 10GB SSD will be sufficient and provide great return on performance
enhancement. - Test the standalone hardware with an understanding that replicating data will introduce some overhead. For example if you have a requirement to attain 10,000 IOPS in your environment, ensure that your hardware can at a bare minimum attain consistent 10,000 IOPS standalone on all nodes that will be part of the cluster. If you are intending to perform synchronous mirroring ensure that you have beyond the bare minimum requirements as further overhead is introduced to maintain synchronous consistency. Network will also need to be load tested to ensure you can transfer the data required for your replication scheme.
- Know how to test properly. When utilizing a test environment to verify production capabilities it is important to mimic the setup as closely as possible. It is understood that you cannot set up an entire production database clone just to test replication but utilizing the correct data generation tool can provide better indication of current performance capabilities. Diskspd is a free tool that can be used for some basic testing, but in the world of SQL, HammerDB provides a much better indicator of real world performance.
DiskSpd: https://github.com/microsoft/diskspd
HammerDB: https://www.hammerdb.com/
- Lastly we have DataKeeper tuning, there are configurable settings beyond the mirror type within DataKeeper. Modifying these is generally a bit more nuanced and best done under the advice of the SIOS support team. However if you have confirmed that all of the other recommendations are squarely in place then tuning some DataKeeper parameters may provide that last boost in performance needed to meet your required metrics. Some examples of tuning would be increasing the number of outstanding writes that can be in your write queue or modifying how often the bitmap file is flushed to disk.
Reproduced with permission from SIOS