How To Build A Sanless SQL Server Failover Cluster Instance In Google Cloud Platform
If you are going to host SQL Server on the Google Cloud Platform (GCP) you will want to make sure it is highly available. One of the best and most economical ways to do that is to build a Sanless SQL Server Failover Cluster Instance In Google Cloud Platform.
Cost Effective
Since SQL Server Standard Edition supports Failover Clustering, we can avoid the cost associated with SQL Server Enterprise Edition which is required for Always On Availability Groups. In addition, SQL Server Failover Clustering is a much more robust solution as it protects the entire instance of SQL Server. It has no limitations in terms of DTC (Distributed Transaction Coordinator) support and is easier to manage. Plus, it supports earlier versions of SQL Server that you may still have, such as SQL 2012 through the latest SQL 2017. Unfortunately, SQL 2008 R2 is not supported due to the lack of support for cross-subnet failover.
What’s Different With SIOS Datakeeper?
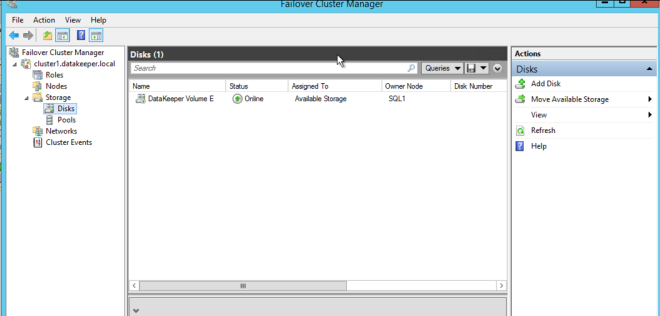
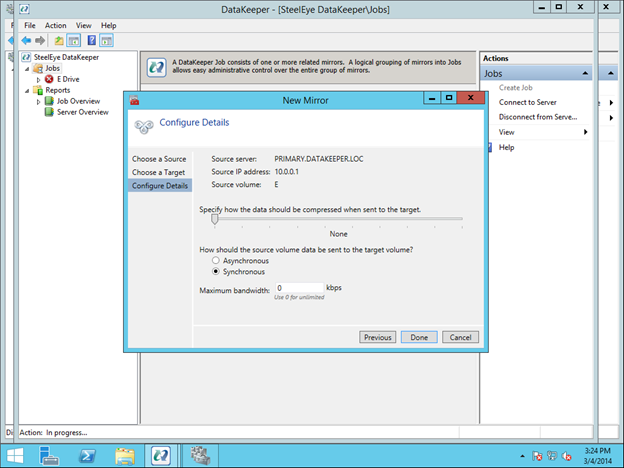
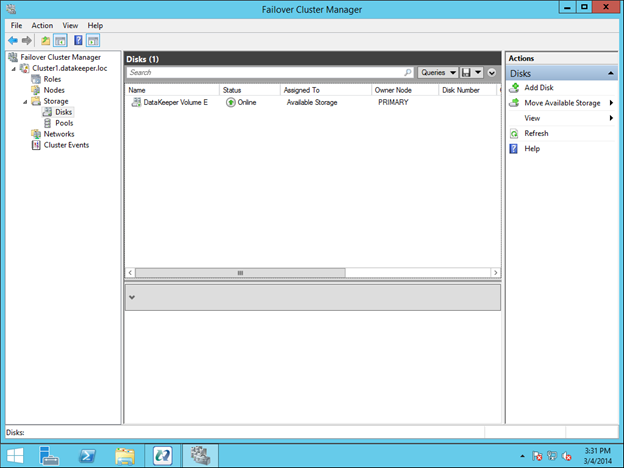
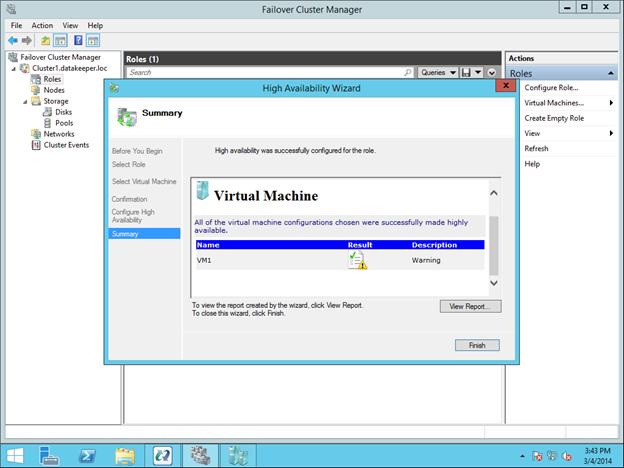
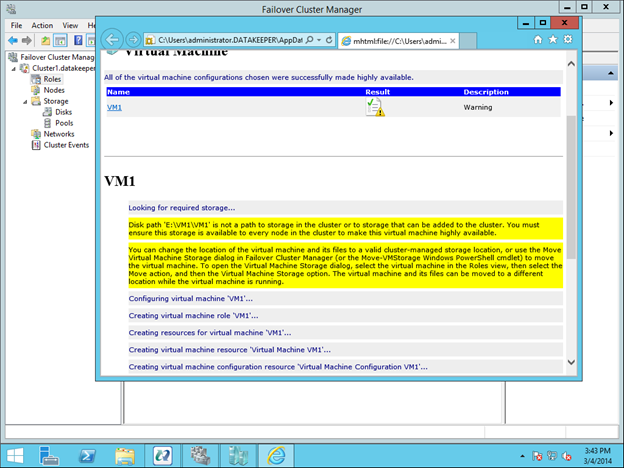
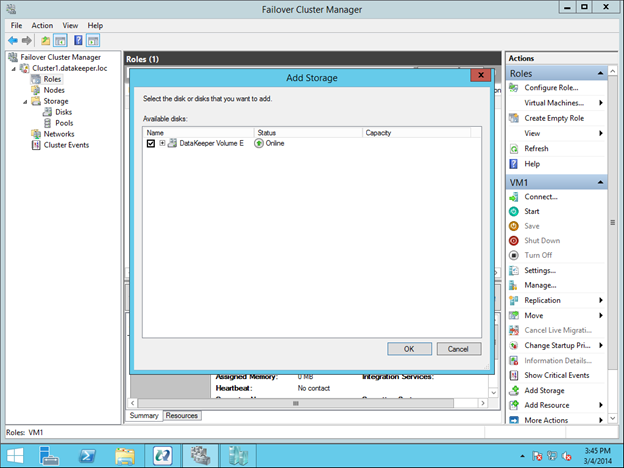
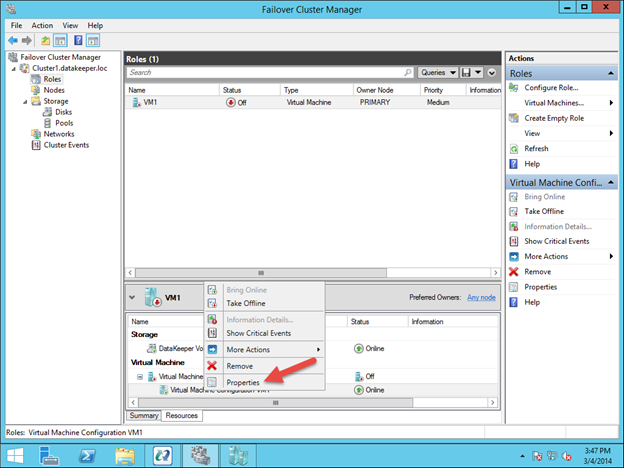
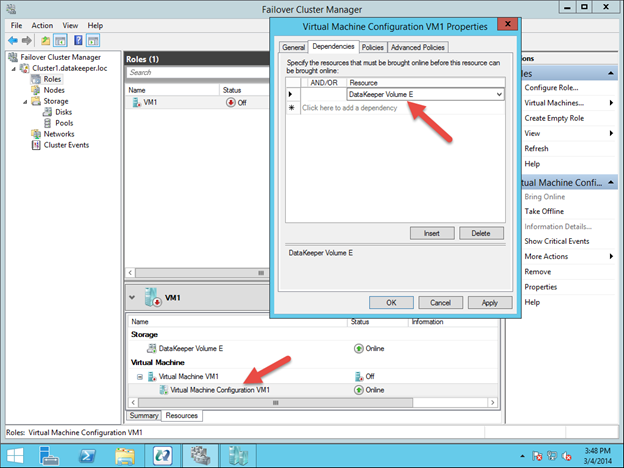
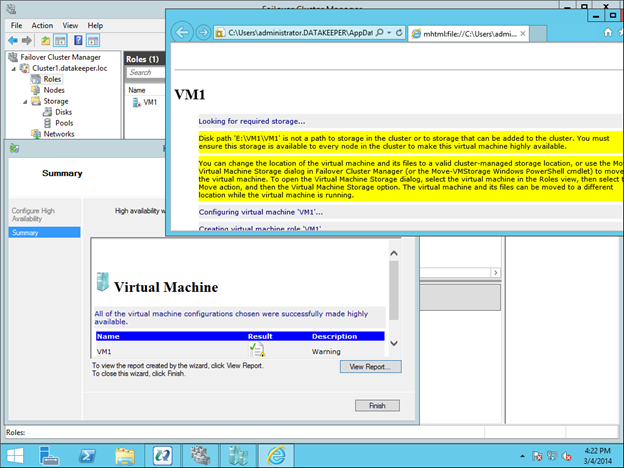
Traditionally, SQL Server FCI requires that you have a SAN or some type of shared storage device. In the cloud, there is no cluster-aware shared storage. In place of a SAN, we will build a SANless cluster using SIOS DataKeeper Cluster Edition (DKCE). DKCE uses block-level replication to ensure that the locally attached storage on each instance remains in sync with one other. It also integrates with Windows Server Failover Clustering through its own storage class resource called a DataKeeper Volume which takes the place of the physical disk resource. As far as the cluster is concerned, the SIOS DataKeeper volume looks like a physical disk, but instead of controlling SCSI reservations. It controls the mirror direction, ensuring that only the active server writes to the disk and that the passive server(s) receive all the changes either synchronously or asynchronously.
Getting Started With The Sanless SQL Server Failover Cluster Instance In Google Cloud Platform
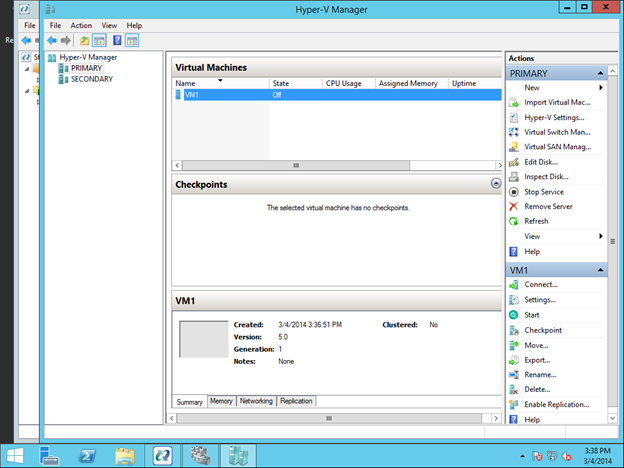
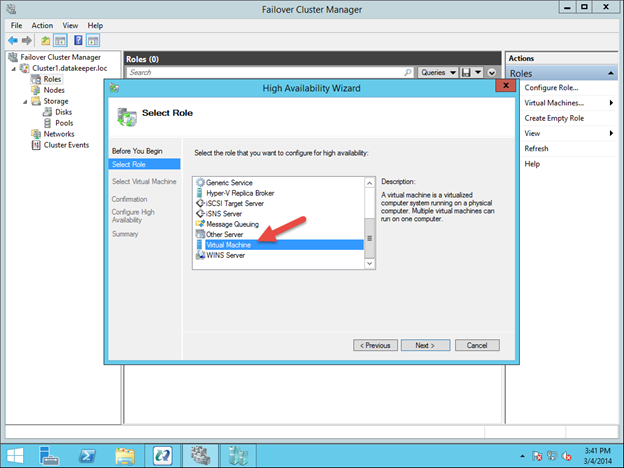
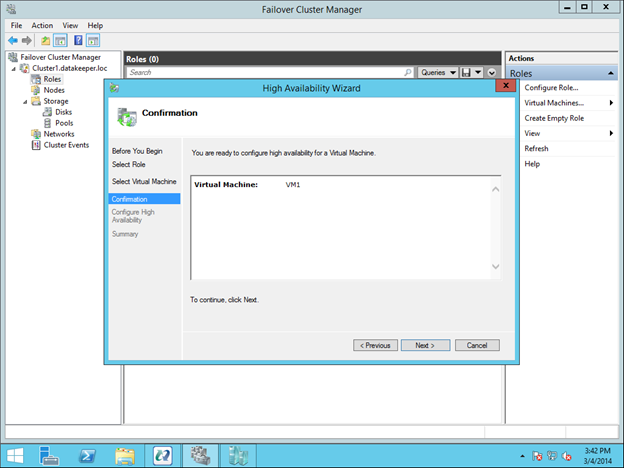
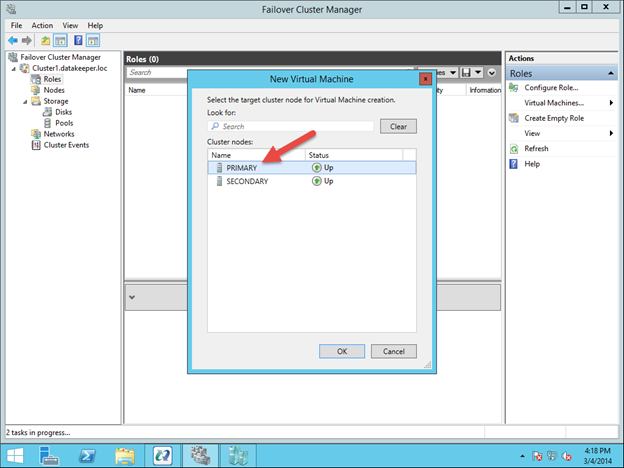
In this guide, we will walk through the steps to build a two-node failover cluster between two instances in the same region, but in different Zones, within the GCP as shown in Figure 1.
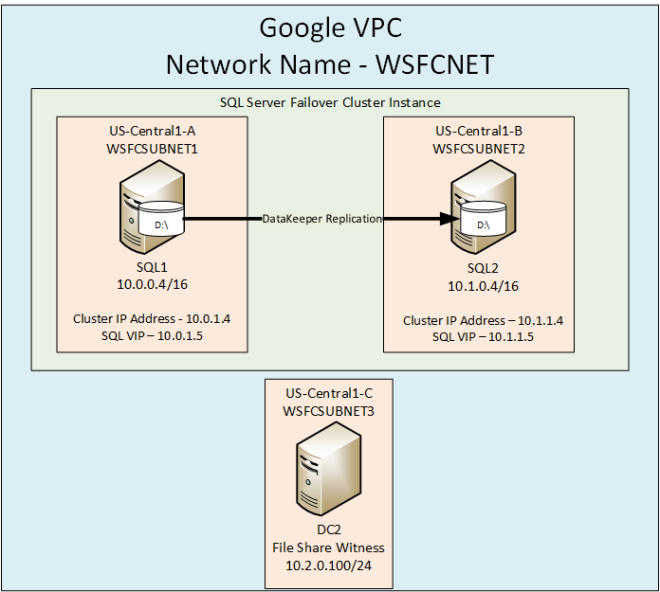
To find out out more about Sanless SQL Server Failover Cluster Instance In Google Cloud Platform, download the entire white paper at https://us.sios.com/san-sanless-clusters-resources/white-paper-build-sql-server-failover-cluster-gcp/
Find out more about SIOS DataKeeper
Reproduced with permission from Clusteringformeremortals.com