How to Reduce Downtime in SAP
Thinking about how to reduce downtime in SAP is an important topic that should be visited during initial solution design. Changes to existing SAP landscapes can be made, these can be more tricky in existing production environments where downtime will be an issue.
There are several typical components in an SAP landscape that can be considered single points of failure; ASCS (Central Services), HANA DB, NFS nodes and SAP Application servers. Ideally these should be protected by using redundant servers in a High Availability configuration.
HA/DR Goals for SAP
Core goals when designing components of High Availability/Disaster recovery for SAP should be:
● Minimize Downtime
● Eliminate Data loss
● Maintain data integrity
● Enable flexible configuration
In today’s modern cloud environments the infrastructure of the underlying hardware is typically well protected from failures by using multiple redundant NICs, redundant storage and hardware availability zones – however, this still doesn’t guarantee that your SAP application will be running and responding to requests.
Using a high availability solution such as the SIOS Protection Suite introduces intelligent High Availability coupled with local disk replication to ensure that your SAP applications and services are continually monitored, protected and have the ability to automatically switch to redundant hardware when a failure is detected.
Now lets consider a simple example of an SAP configuration that’s not HA protected, it might look something like this (figure 1):
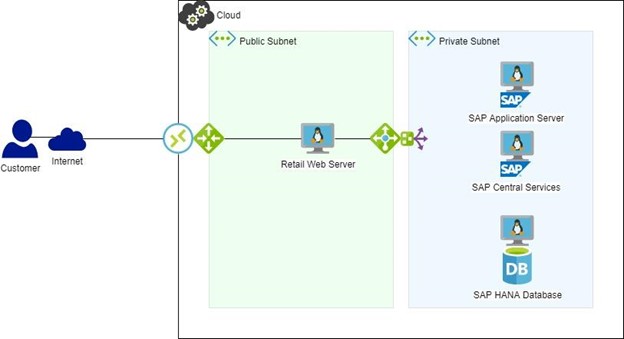
If this environment is used to process transactions from a web server that is used to sell clothing to customers, SAP is being used to process sales, track orders, track inventory and provide multiple automated ordering etc based on these transactions.
Now let’s imagine that this sales processing environment (pictured above) was configured in the cloud without HA because the architect thought that highly redundant hardware in the cloud environment was good enough to protect from failures. If that HANA DB experiences an issue and shuts down let’s look at the steps that are typical required to get the database back up and running:
● Even if HANA is configured with HANA System Replication, failover to the secondary HANA DB system isn’t automated. This will require someone who knows HANA to correct, after the failure is detected and they are notified of the outage.
● Real Time transactions from web server will be suspended until the issue is resolved
If this small clothing retailer transacts about $10 million annually from web based sales, that equates to roughly $1150 per hour in sales equalized over the year. Peak times would cost much more per hour.
This report from IBM suggests that the average downtime cost per hour is $10k
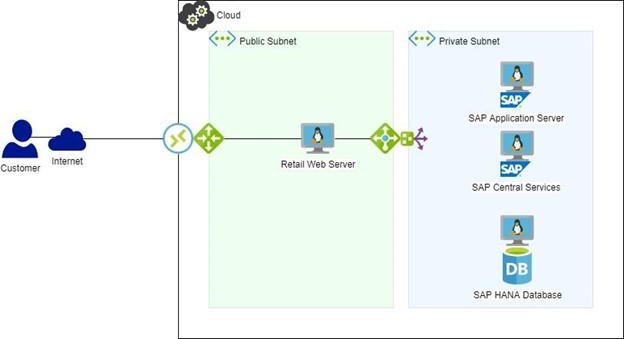
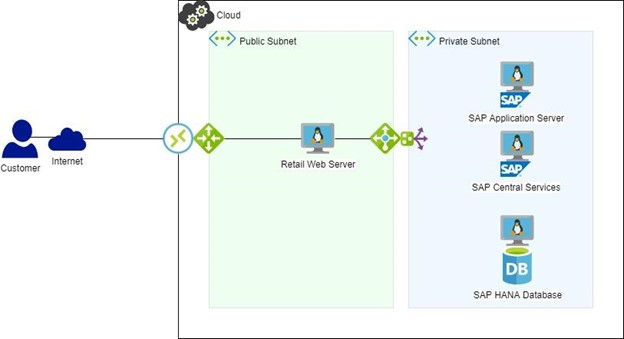
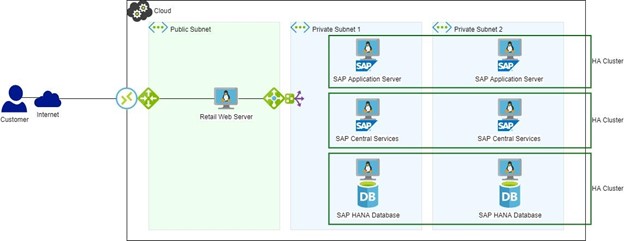
Figure 2: SAP Landscape with HA/DR
If HA software had been in use (figure 2), HANA DB failover would have been automatic and interruption to the web server would have been within the configured timeouts and absolutely no sales would have been lost. An alert would be generated and the cause could be looked at and diagnosed in a more leisurely manner than a system down situation.
Scale up the customer size and it’s very likely that any system down situation would start to cost hundreds of thousands of dollars and consume significant people resources to resolve.
Another IBM report suggests a staggering 44% of respondents had bi-monthly unplanned outages and another 35% had monthly unplanned outages.
Planned outages themselves are another potential problem with 46% of respondents reporting monthly planned outages and a further 29% reporting yearly planned outages. Having applications and services protected by HA software can also mitigate these planned outages by allowing services to be moved to running systems during maintenance activities.
Learn more about high availablity for SAP and S/4HANA.