Expand Your High Availability Metrics
In the technology field, we love data. We love data about data and all the metrics and measures that our tools can bring. We’ve created industries around analytics, products that capture every detail from thousands of connected devices. We love metrics and measures. In many instances within the higher availability space, we love the high availability metrics that tell us how quickly a system recovered from the failure. We calculate and track the time between detection and remediation, and we obsess over knowing and measuring how much transactional data would be lost in a disaster, system failure, or disk crash.
Ironically, in high availability and disaster recovery (HA/DR) systems, there are some metrics that don’t get enough attention.
Here are eight other high availability metrics you should be watching to manage your environment:
1. Security alerts
Availability isn’t just about application monitoring and recovery. Systems that are publicly available are always under attack. If you aren’t monitoring security alerts and warnings, your applications may be running flawlessly, while your intellectual property is being funneled flawlessly out the door.
2. Idle connections
Idle connections sound harmless, but they are about as harmless as the green leafy kudzu on a southern lawn. Idle connections take up resources and threaten to fill database pools, congest networks, and stifle performance. Furthermore, idle connections can indicate a problem in the application layer or database configuration.
3. Long-running queries, commands, or jobs
This applies not just to database queries or jobs, but also to commands and backups. Long running queries, commands and jobs can be an indicator of poor system health, slow disk speeds, CPU or other resource contention, or deeper systematic, application compatibility or OS problems.
4. Disk IO
Disk IO typically refers to the input/output operations of the system related to disk activity. Measuring disk I/O can help identify bottlenecks, poor hardware configurations, improperly sized disk or poorly tuned disk layouts for a given workload. Monitoring disk I/O can help tell you if the long running queries are a function of poor sql syntax, poorly coded applications, or latency and access problems.
5. Memory
We all think about how much memory is being used, but memory monitoring goes beyond measuring and looking at free versus used. Monitoring memory helps you look into bottlenecks, leaks, identify improperly sized systems, understand load, load average, and spikes. In addition, knowing about memory intensive patterns can help you tune your availability suite to avoid false failures.
6. Disk Space
As VP of Customer Experience I once had the unfortunate experience of waking up early in the morning for an emergency call. The customer was facing a down production system after a power outage. When they tried to restart their system their protected applications failed to start. After a quick check of the error logs it was clear that the root drive was 100% full. The application could not write to any of the file systems. Disk space monitoring is available in many forms and ways and having it as a metric can prevent unnecessary problems and costly last-minute scrambles to add more. .
7. Errors and alerts
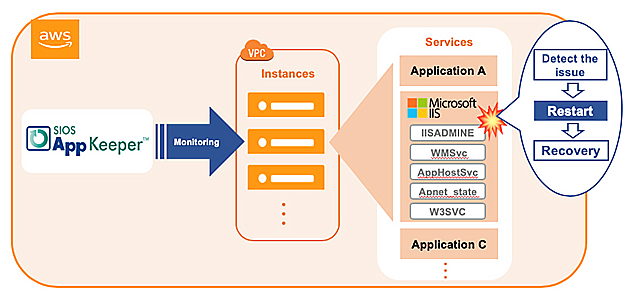
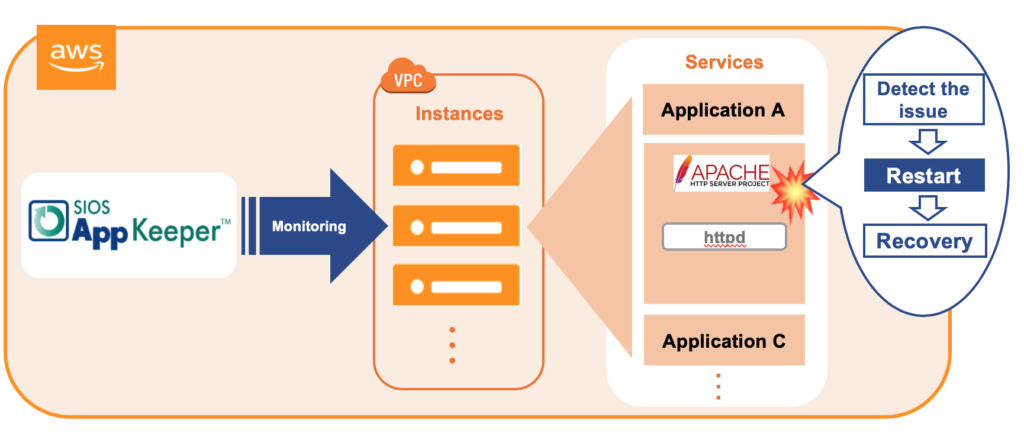
Errors, alerts, and recovery messages in the logs are another good metric to consider. Your availability solution may be keeping your clients online and happy, but it may also be masking an issue that will need your attention soon. Adding log monitoring for FATAL, PANIC, and key ERROR messages can help you identify issues that your availability solution is frequently recovering from, such as database crashes, application panics or core dumps, or fatal errors requiring a cold restart.
8. Recovery numbers
Similar to monitoring errors and alerts, the recovery numbers can tell you a lot about the health of your system’s availability. If you are averaging more than one application recovery per week, you’re likely experiencing something more than your normal availability protection. And while the recovery was successful in restarting your application or system, too many of these false or even real recoveries isn’t healthy.
The list of HA/DR metrics that we can monitor and the tools to monitor them are growing by leaps and bounds. Be sure that you and your team consider expanding your current data capture and analysis to include those that make for the best higher availability system possible.
— Cassius Rhue, VP, Customer Experience
Reproduced with permission from SIOS