
Using SIOS Protection Suite for Linux Quick Service Protection Resource
On a recent engagement with the SIOS Professional Services team, a customer inquired about how to protect a custom application with the SIOS Protection Suite for Linux solution. One of the highly experienced high availability experts at SIOS Technology Corp., helped understand the customer’s application and laid out the methods SIOS provides for custom application support.
SIOS Protection Suite for Linux provides multiple methods for adding high availability and application monitoring to custom applications. These options include the following:
- Creating a custom application recovery kit (ARK)1
- Creating a generic application resource hierarchy
- Creating a quick service protection resource
| Type | Coding Complexity | Monitoring | Recovery |
| Custom Application Recovery Kit Resource1 | Highest | Highest | Highest |
| Generic Application Resource | Medium | High | High |
| Quick Service Protection Resource | Low | Medium | Medium |
Definitions Used in Chart
Monitoring – defined as the ability to make a determination of the availability, accessibility and functioning of the protected application, database or service. A low level of application, database, or service monitoring provides basic coverage, such as a check for a running process, existence of a pid_file, or that the status command returns a ‘true’ result when executed. Note: A ‘true’ or ‘0 (zero)’ return code does not mean that the application, database, or service is running. But only that the command executed was able to successfully complete with a positive (‘true’ or ‘0 (zero)’) status result. The highest level of monitoring indicates that application specific knowledge is applied to determine the health and functioning of the application beyond lower level methods such as process status, ps output, or systemd status returns. The highest level of monitoring typically applies knowledge of recommended order of healthcheck operations, knowledge of dependencies, and analysis of the results obtained from status and monitoring commands.
Recovery – defined as the ability to restart a failed application, database or service. A low level of recovery capability implies that commands for a restart are issued and expected output are obtained from the issuance of the command. The highest level of monitoring indicates that application-specific knowledge is applied to determine how to initiate an orderly restart of the application, database, or service, which may require knowledge of recommended order of operations, dependencies, rollbacks or other related remediation of a failed service.
Solution: Quick Service Protection Resource
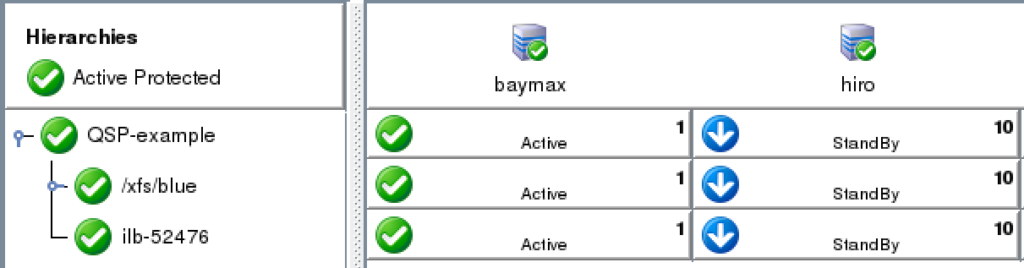
In this engagement, the customer’s application had systemd compatibility. Based on their overall requirements for avoiding coding, minimal monitoring needs, and simple recovery procedures, we recommended the Quick Service Protection (QSP) Resource.
The QSP resource works to quickly add support of a systemd service to the SIOS Protection Suite for Linux resource protection. In the case of Customer Example.com, they have a systemd compatible service, with the minimal required definition needed to start and stop their application.
[Unit]
Description=SIOS ‘as-is’ Example Service 2020
After=network.target
[Service]
Type=simple
Restart=always
RestartSec=3
User=root
ExecStart=/example_app/bin/exampleapp start
ExecStop=/example_app/bin/exampleapp stop
[Install]
WantedBy=multi-user.target
Example.com systemd file
SIOS recommends that prior to attempting the protection of the resource with the SIOS Protection Suite for Linux product, verify via systemctl that the example application stops and starts accordingly:
# systemctl status example
* example.service – SIOS ‘as-is’ Example Service 2020
Loaded: loaded (/usr/lib/systemd/system/example.service; disabled; vendor preset: disabled)
Active: inactive (dead)
# systemctl start example
# systemctl status example
* example.service – SIOS ‘as-is’ Example Service 2020
Loaded: loaded (/usr/lib/systemd/system/example.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2020-08-21 14:53:27 EDT; 5s ago
Main PID: 19937 (exampleapp)
CGroup: /system.slice/example.service
`-19937 /usr/bin/perl /example_app/bin/exampleapp start
# systemctl stop example
# systemctl status example
* example.service – SIOS ‘as-is’ Example Service 2020
Loaded: loaded (/usr/lib/systemd/system/example.service; disabled; vendor preset: disabled)
Active: inactive (dead)
After verifying that the application functions correctly via systemd, restart the service and ensure that the service is running.
# systemctl start example
# systemctl status example
* example.service – SIOS ‘as-is’ Example Service 2020
Loaded: loaded (/usr/lib/systemd/system/example.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2020-08-21 15:59:44 EDT; 3min 2s ago
Main PID: 30740 (exampleapp)
Refer to the SIOS Protection Suite for Linux Quick Service Protection Suite documentation for additional details on the resource create process.
Using the SPS-L UI select the Create option, indicated in the Global UI Resource Toolbar by the following icon: ![]()
Once the create wizard is launched, select the Quick Service Protection option in the Create Resource Wizard Window

In the next prompt for ‘Switchback Type’, choose whether you will use intelligent switchback or automatic switchback.

After selecting the ‘Switchback Type’, the Server dialogue appears allowing you to choose the primary server for the custom application.

(Note: If the service requires storage, be sure to choose the same primary server previously selected for the storage resources.)
In the Service Name dialog box, find the service for your custom application.

Once you’ve selected the correct service, example, determine whether you will enable monitoring or disable the monitoring service. Refer to the documentation to gain an understanding of the monitoring provided by the QSP resource.2

Next, choose a resource tag. A resource tag should be a meaningful name that will help your IT team quickly identify which SPS-L resource protects your application or service.
Lastly, follow the final dialogue to complete the resource creation process. Once the resource is created, use the UI to extend the resource to additional servers. If necessary, create dependencies between the newly protected custom service/application and any other required resources such as storage or IP resources.
NOTES:
1 Creating a customer application recovery kit can be accomplished via an engagement with the SIOS Technology Corp. Professional Services Team. For more information contact professional-services@us.sios.com
2 The QSP Recovery Kit quickCheck can only perform simple health (using the “status” action of the service command). QSP doesn’t guarantee that the service is provided or the process is functioning. If complicated starting and/or stopping is necessary, or more robust health checking operations are necessary, using a Generic Application or Custom Application ARK is recommended
Reproduced from SIOS



