How To Create A DataKeeper Replicated Volume That Has Multiple Targets Via CLI
I often help people automate the configuration of their infrastructure so they can build 3-node clusters that span Availability Zones and Regions. The CLI for creating a DataKeeper Job and associated mirrors that contain more than one target can be a little confusing, so I’m documenting it here in case you find yourself looking for this information. The DataKeeper documentation describes this as a Mirror with Multiple Targets.
The environment in this example looks like this:
PRIMARY (10.0.2.100) – in AZ1
SECONDARY (10.0.3.100) – in AZ2
DR (10.0.1.10) – in a different Region
I want to create a synchronous mirror from PRIMARY to SECONDARY and an asynchronous mirror from PRIMARY to DR. I also have to make sure the DataKeeper Job knows how to create a mirror from SECONDARY to DR in case the SECONDARY or DR server ever become the source of the mirror. EMCMD will be used to create this multiple target mirror.
We need to first create the Job that contains all this possible endpoints and define whether the mirror will be Sync (S) or Async (A) between those endpoints.
emcmd . createjob ddrive sqldata primary.datakeeper. local D 10.0.2.100 secondary.datakeeper. local D 10.0.3.100 S primary.datakeeper.local D 10.0.2.100 dr. datakeeper.local D 10.0.1.10 A secondary.datakeeper.local D 10.0.3.100 dr.datakeeper. local D 10.0.1.10 A
That single “createjob” command creates the Job. It might be a little easier to look at that command like this:
emcmd . createjob ddrive sqldata primary.datakeeper.local D 10.0.2.100 secondary.datakeeper.local D 10.0.3.100 S primary.datakeeper.local D 10.0.2.100 dr.datakeeper. local D 10.0.1.10 A secondary.datakeeper.local D 10.0.3.100 dr.datakeeper.local D 10.0.1.10 A
Next we need to create the mirrors.
emcmd 10.0.2.100 createmirror D 10.0.1.10 A emcmd 10.0.2.100 createmirror D 10.0.3.100 S
Our DataKeeper Job should now look like this in the DataKeeper UI
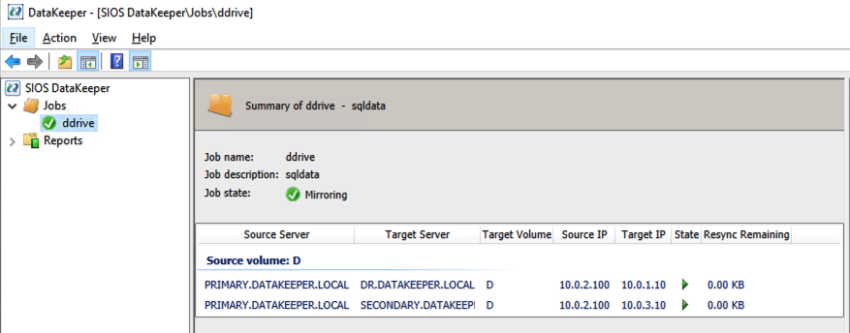
One-to-many DataKeeper Replicated VolumeAnd then finally we can register the DataKeeper Volume Resource in the cluster Available Storage with this command.
emcmd . registerclustervolume D
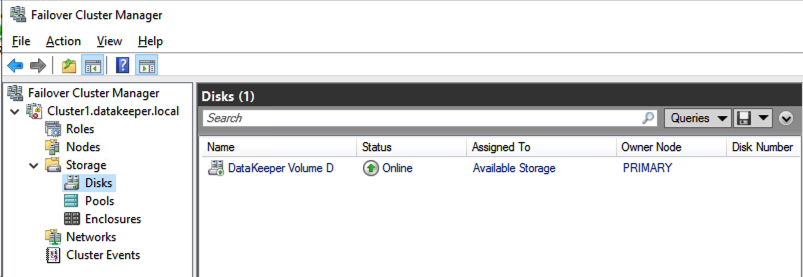
The DataKeeper Volume Resource will now appear in Available Storage as shown below.
DataKeeper Volume in Available StorageYou are now ready to install SQL Server, SAP, File Server or any other clustered resource you normally protect with Windows Server Failover Clustering.

Reproduced with permission from Clusteringformeremortals