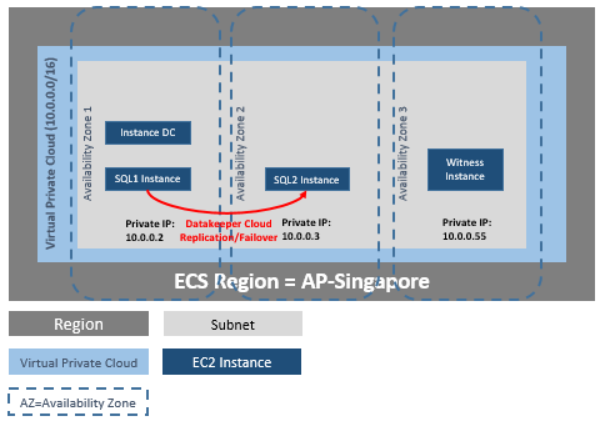
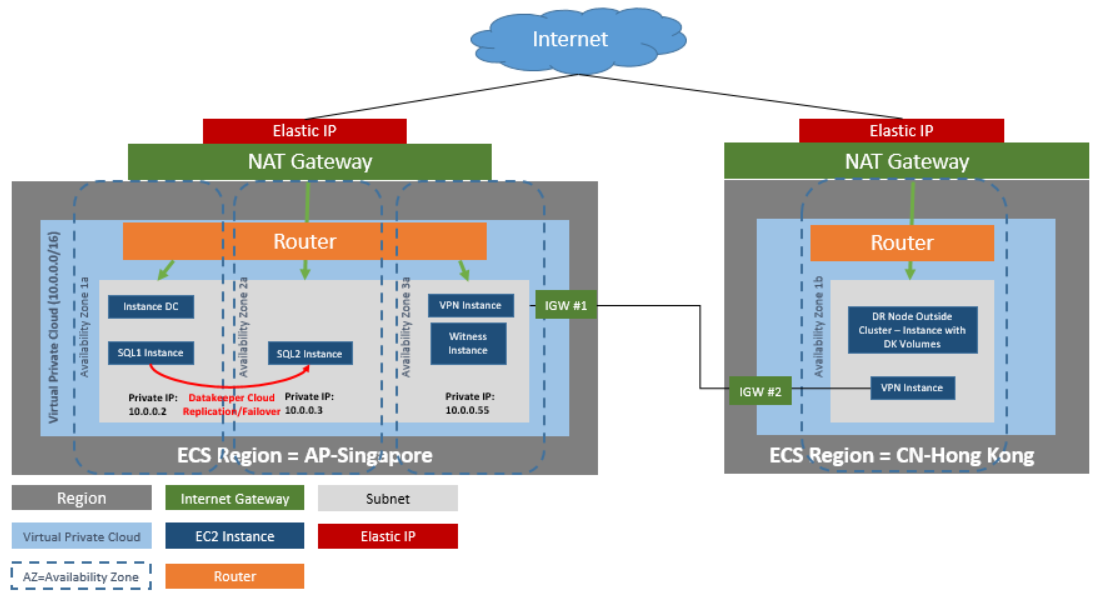
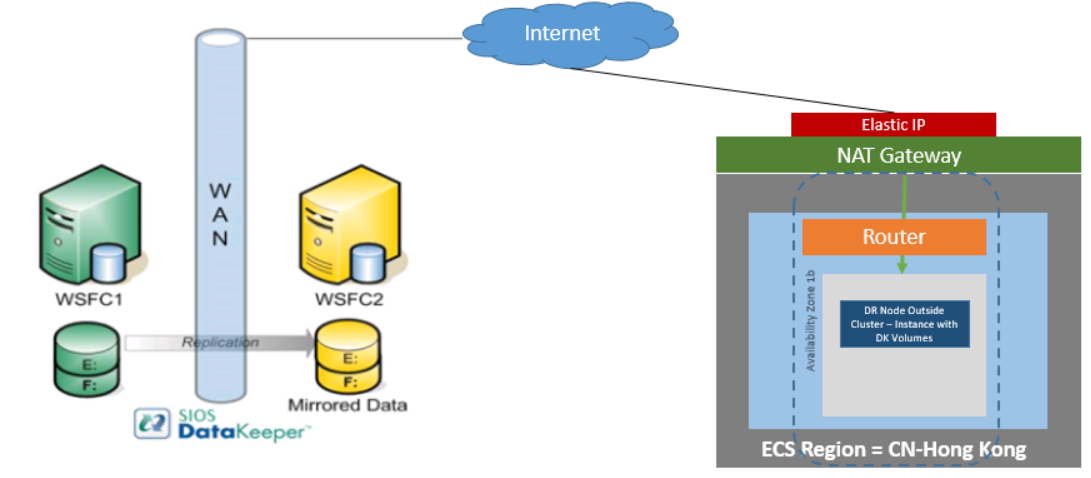
High Availability & the Cloud: The More You Know
While researching reasons to migrate to the cloud, you’ve probably learned that the benefits of cloud computing include scalability, reliability, availability, and more. But what, exactly, do those terms mean? Let’s consider high availability (HA), as it is often the ultimate goal of moving to the cloud for many companies.
The idea is to make your products, services, and tools accessible to your customers and employees at any time from anywhere using any device with an internet connection. That means ensuring your critical applications are operational – even through hardware failures, software issues, human errors, and sitewide disasters – at least 99.99% of the time (that’s the definition of high availability).
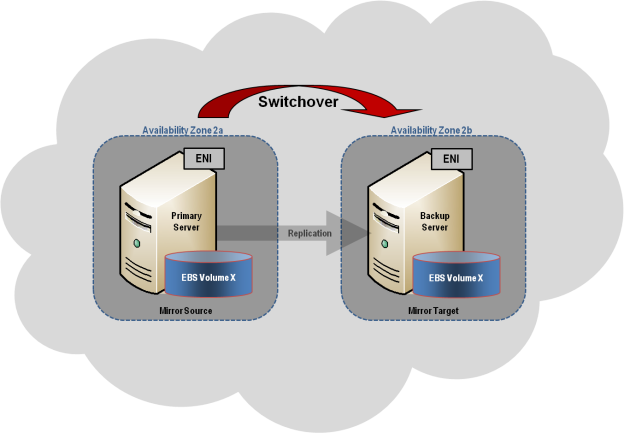
While public cloud providers typically guarantee some level of availability in their service level agreements, those SLAs only apply to the cloud hardware. There are many reasons for application downtime that aren’t covered by SLAs. For this reason, you need to protect these applications with clustering software that will detect issues and reliably move operations to a standby server if necessary. As you plan what and how you will make solutions available in the cloud, remember that it is important that your products and services and cloud infrastructure are scalable, reliable, and available when and where they are needed.
Quick Stats on High Availability in the Cloud in 2021
Now that we’ve defined availability in the cloud context, let’s look at its impact on organizations and businesses. PSA, these statistics may shock you, but don’t fret. We’ve also got some solutions to these pressing and costly issues.
- As much as 80% of Enterprise IT will move to the cloud by 2025 (Oracle).
- The average cost of IT downtime is between $5,600 and $11,600 per minute (Gartner; Comparitech).
- Average IT staffing to employee ratio is 1:27 (Ecityworks).
- 22% of downtime is the result of human error (Cloudscene).
- In 2020, 54% of enterprises’ cloud-based applications moved from an on-premises environment to the cloud, while 46% were purpose-built for the cloud (Forbes).
- 1 in 5 companies don’t have a disaster recovery plan (HBJ).
- 70% of companies have suffered a public cloud data breach in the past year (HIPAA).
- 48% of businesses store classified information on the cloud (Panda Security).
- 96% of businesses experienced an outage in a 3-year period (Comparitech).
- 45% of companies reported downtime from hardware failure (PhoenixNAP).
What You Can Do – Stay Informed
If you are interested in learning the fundamentals of availability in the cloud or hearing about the latest developments in application and database protection, join us. The SIOS Cloud Availability Symposium is taking place Wednesday, September 22nd (EMEA) and Thursday, September 23rd (US) in a global virtual conference format for IT professionals focusing on the availability needs of the enterprise IT customer. This event will deliver the information you need on application high availability clustering, disaster recovery, and protecting your applications now and into the future.
Cloud Symposium Speakers & Sessions Posted
We have selected speakers presenting a wide range of sessions supporting availability for multiple areas of the data application stack. Check out the sessions posted and check back for additional presentations to be announced! Learn more
Register Now
Whether you are interested in learning the fundamentals of availability in the cloud or hearing about the latest developments in application and database protection, this event will deliver the information you need on application high availability clustering, disaster recovery, and protecting your applications now and into the future.
Register now for the SIOS Cloud Availability Symposium.
Reproduced from SIOS