
Dynamic Utilization Will Make High Availability More Affordable, Further Driving Migration to the Cloud
On-demand provisioning in the cloud is nothing new. What will be new are more cost-effective options for high availability and disaster recovery in hybrid and purely public cloud configurations. Such on-demand HA and DR will leverage dynamic utilization of resources spread among multiple datacenters and geographical regions, and make achieving high service levels more affordable for more applications.
Both HA and DR require redundancy to ensure reliable, rapid recovery from failures.
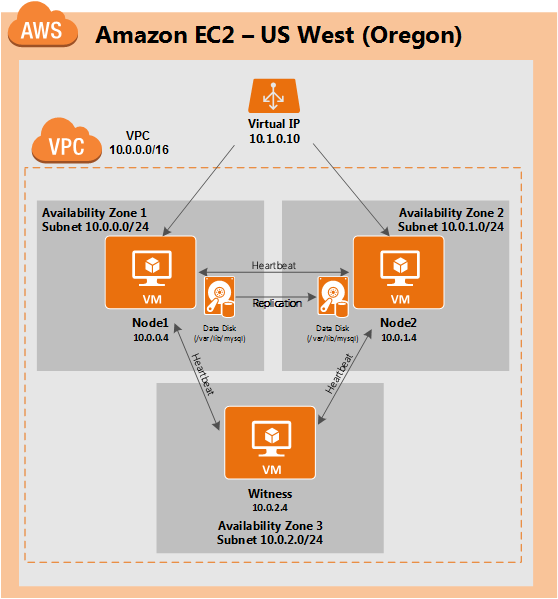
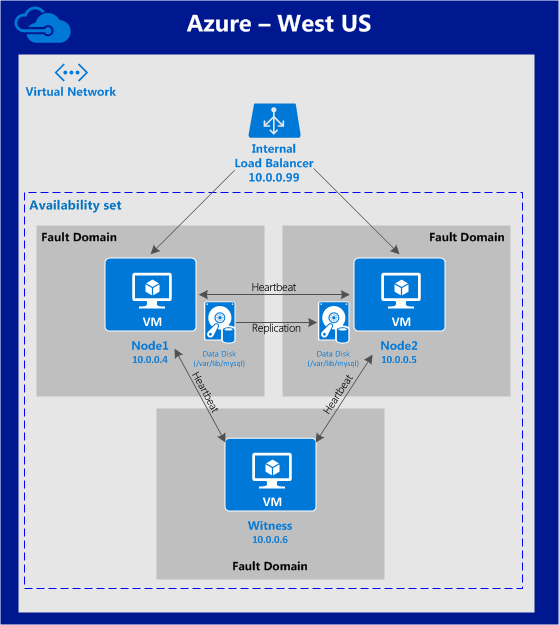
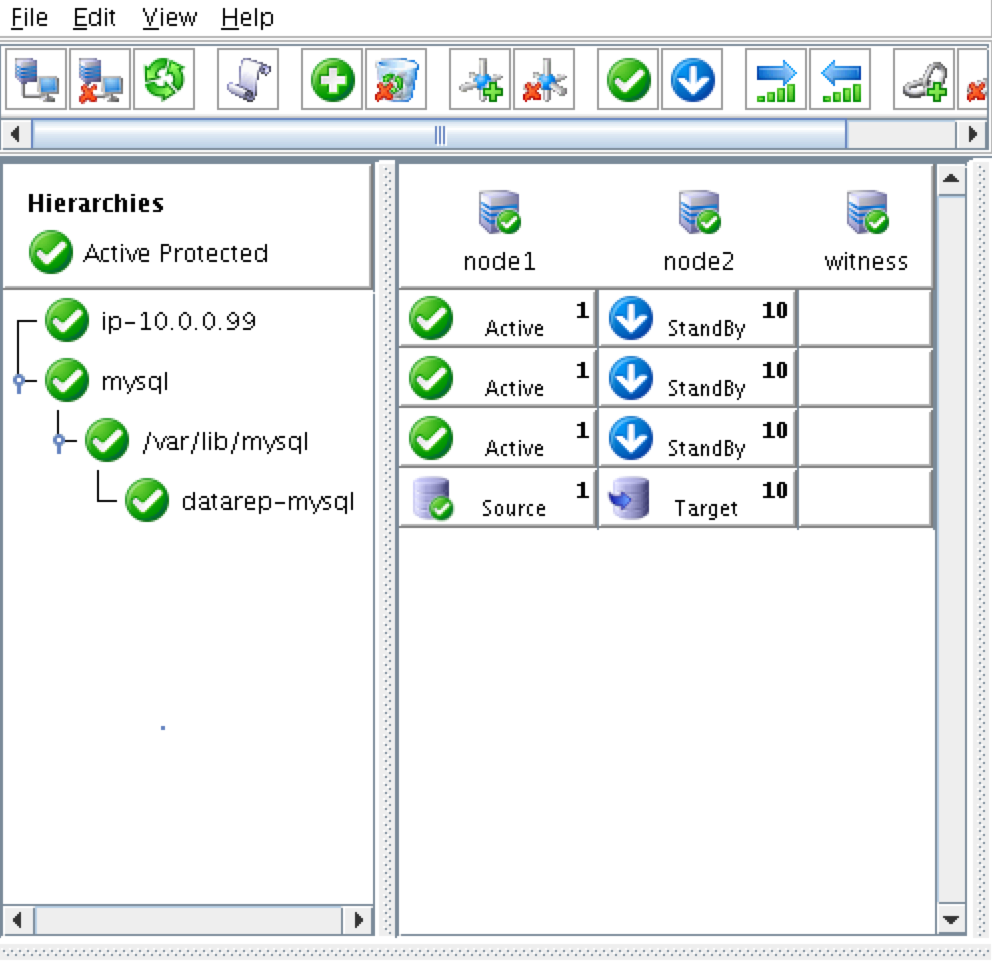
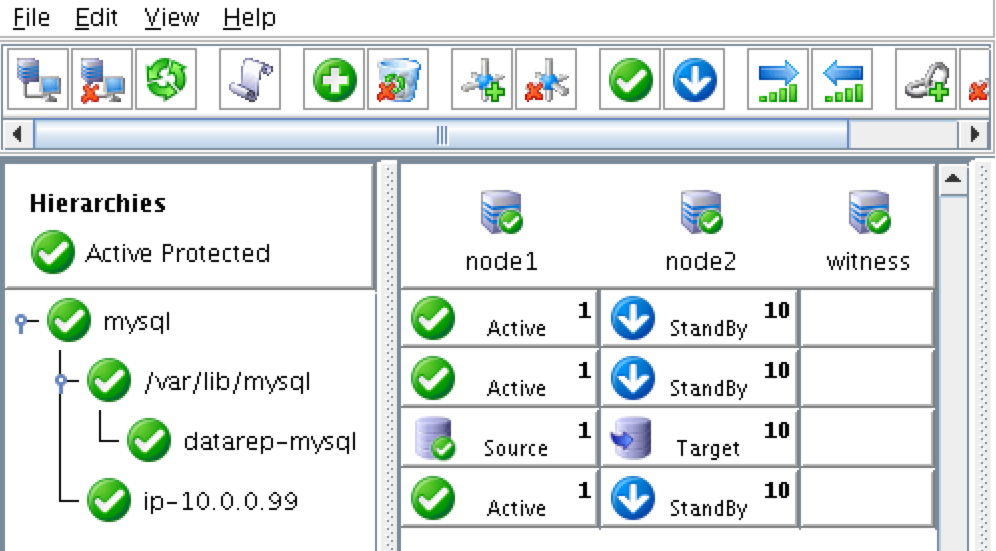
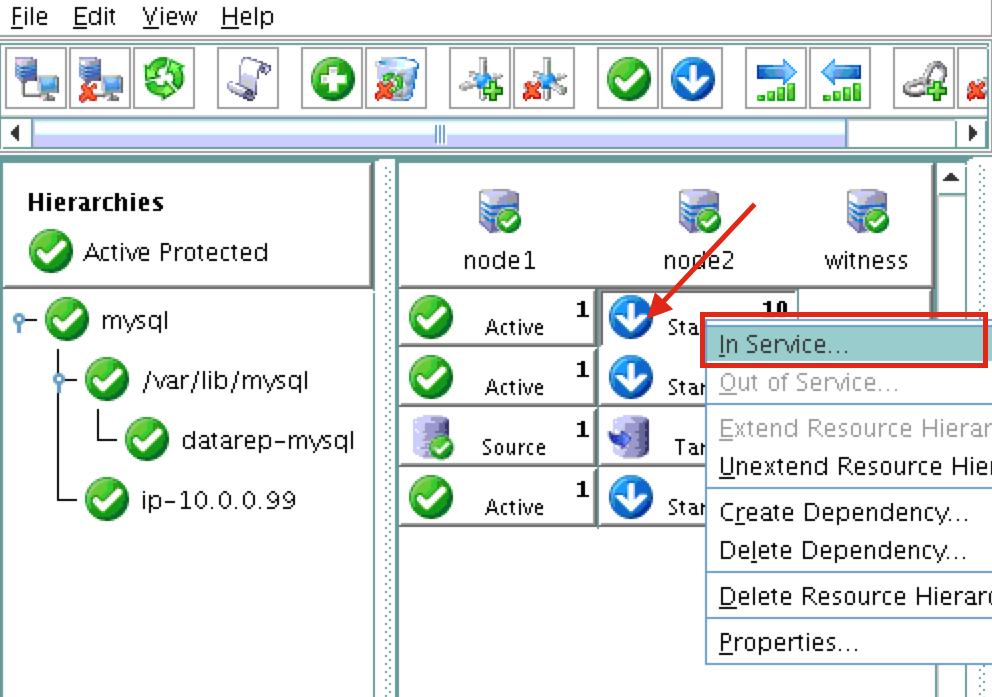
HA failover clustering replicates the full operational environment of the primary VM, including the CPU, memory and storage resources, in a secondary VM. All data is then also replicated in real-time to the secondary, which remains idle unless and until the primary fails. Having one or more fully redundant secondary VMs creates a cluster that is effectively in a continual state of self-test, thereby ensuring it is prepared for automatic and rapid failover.
Basic DR configurations, by contrast, lack the capabilities needed for fast failover
Consider Azure Site Recovery, for example. Microsoft positions ASR as being DR-as-a-service. And the growing DRaaS market now includes offerings from nearly a dozen providers. With ASR, primary VMs are replicated to secondaries in other Azure regions, or from on-premises instances to the Azure cloud. But the data is not replicated in real-time. The service is unable to automatically detect and failover from many causes of application-level downtime.
Underlying Issue
Many potential points of failure are simply not covered by DRaaS and other cloud availability services. In general, complete loss of service is detected. But faults due to application or OS software, as well as failures in discrete resources like network or storage are not detected. As a consequence, an application service may be disrupted-potentially for an extended period-without being detected by the cloud’s own recovery facilities.
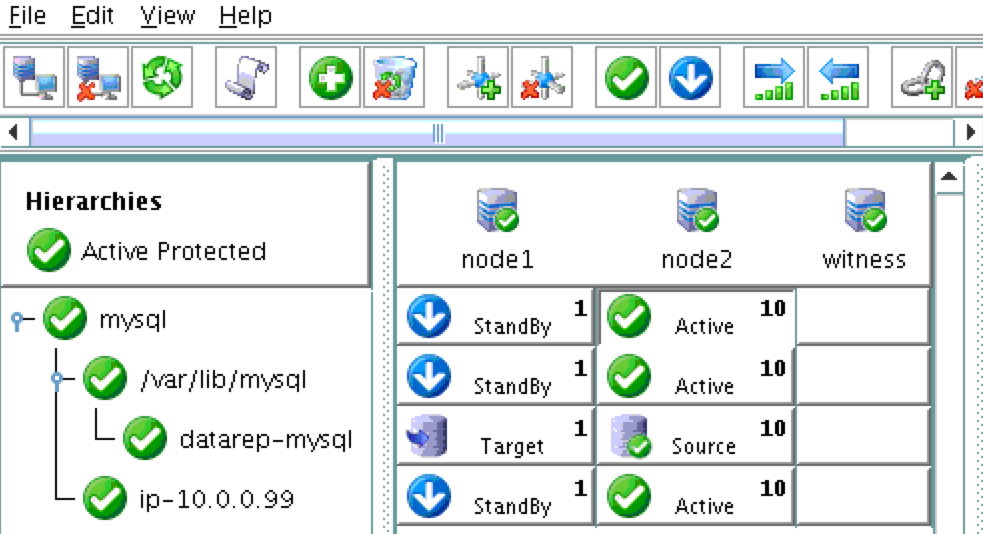
SIOS DataKeeper and SIOS Protection Suite from SIOS Technology
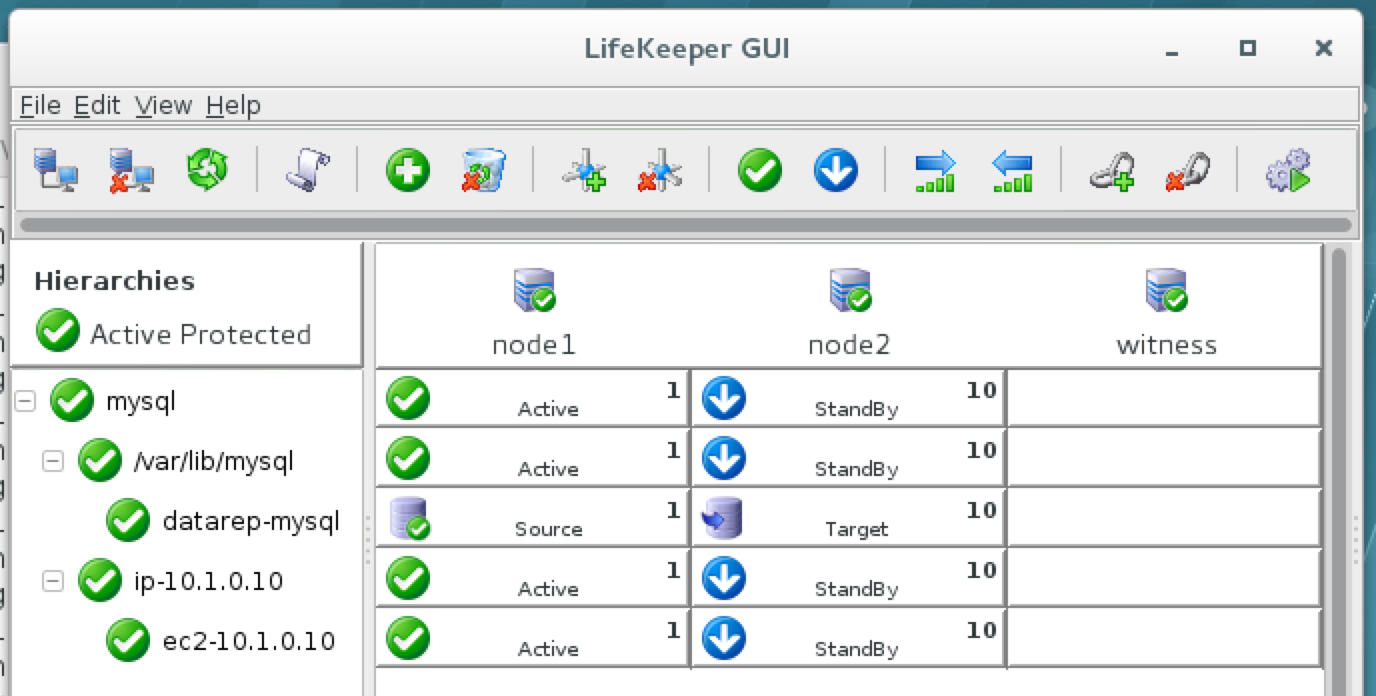
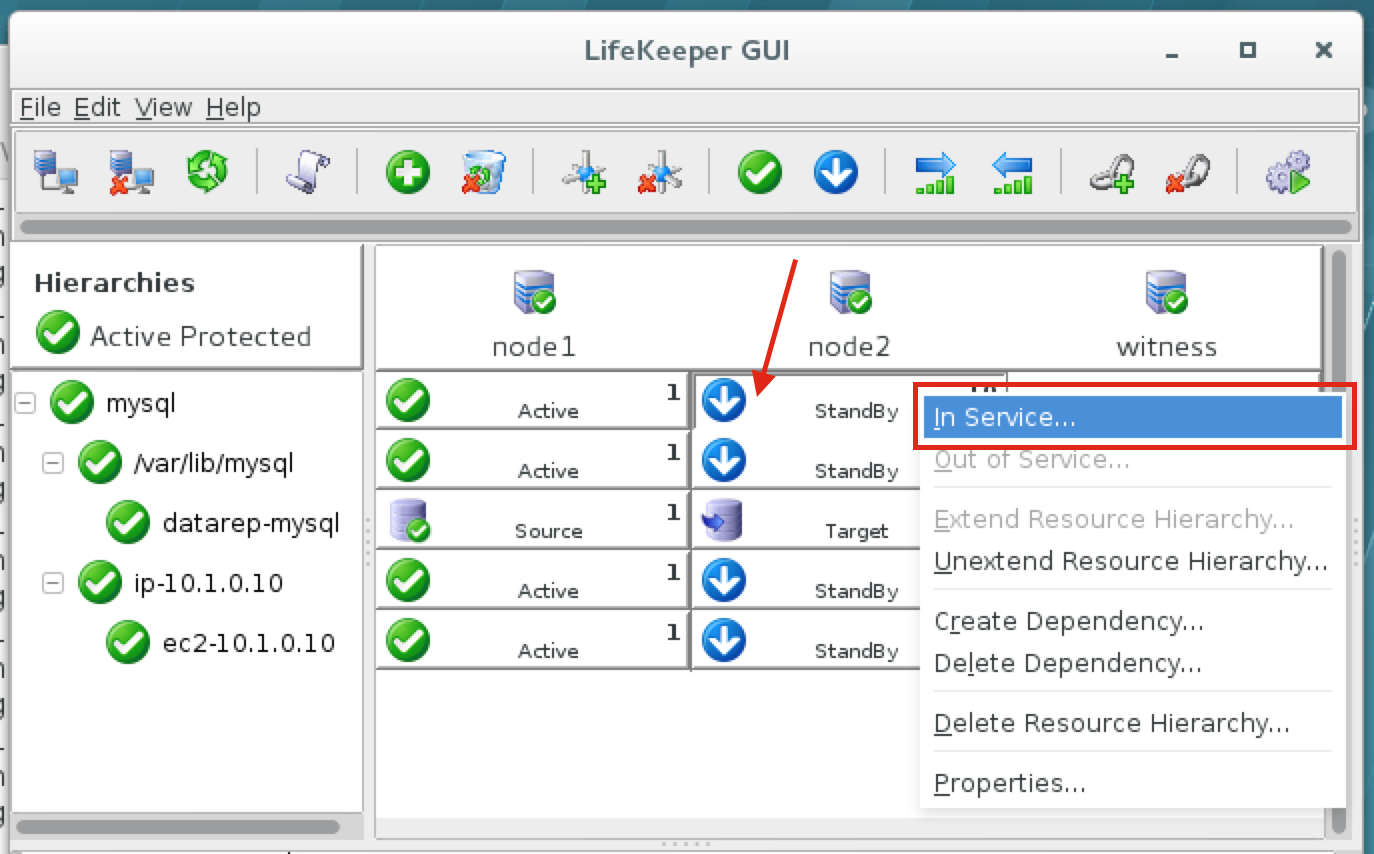
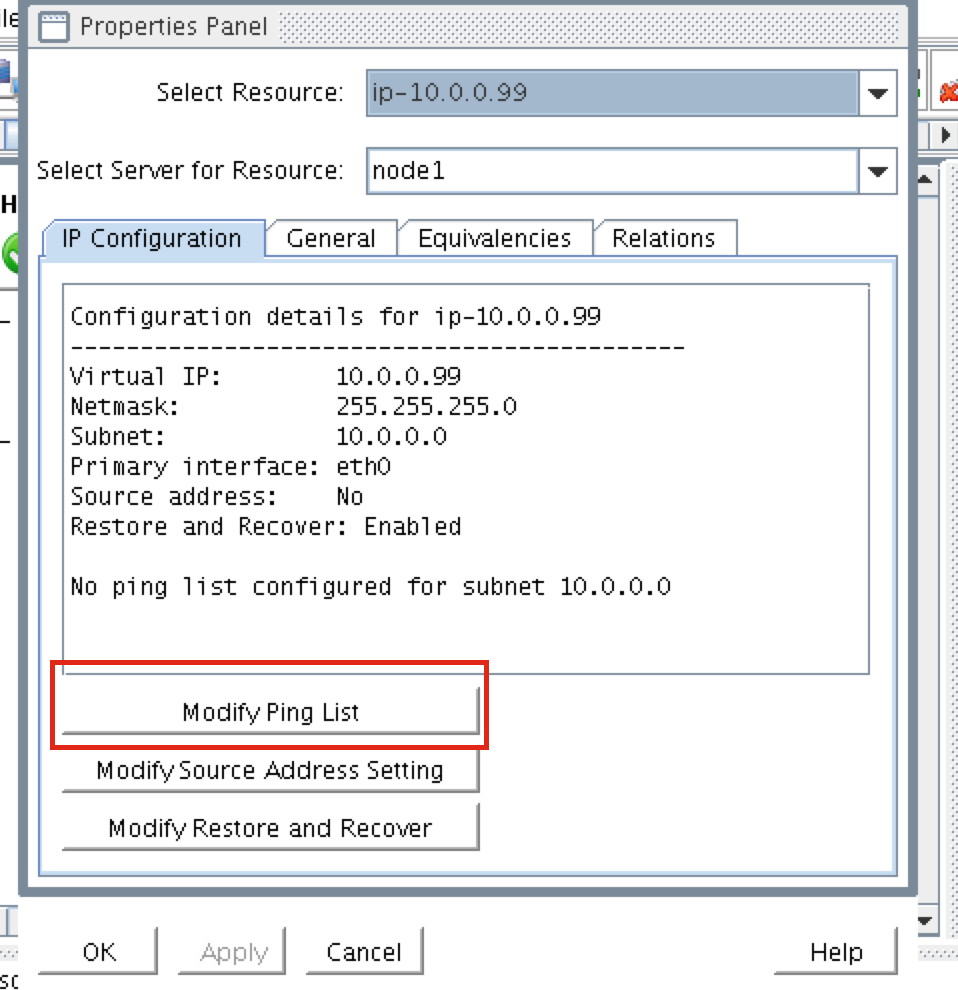
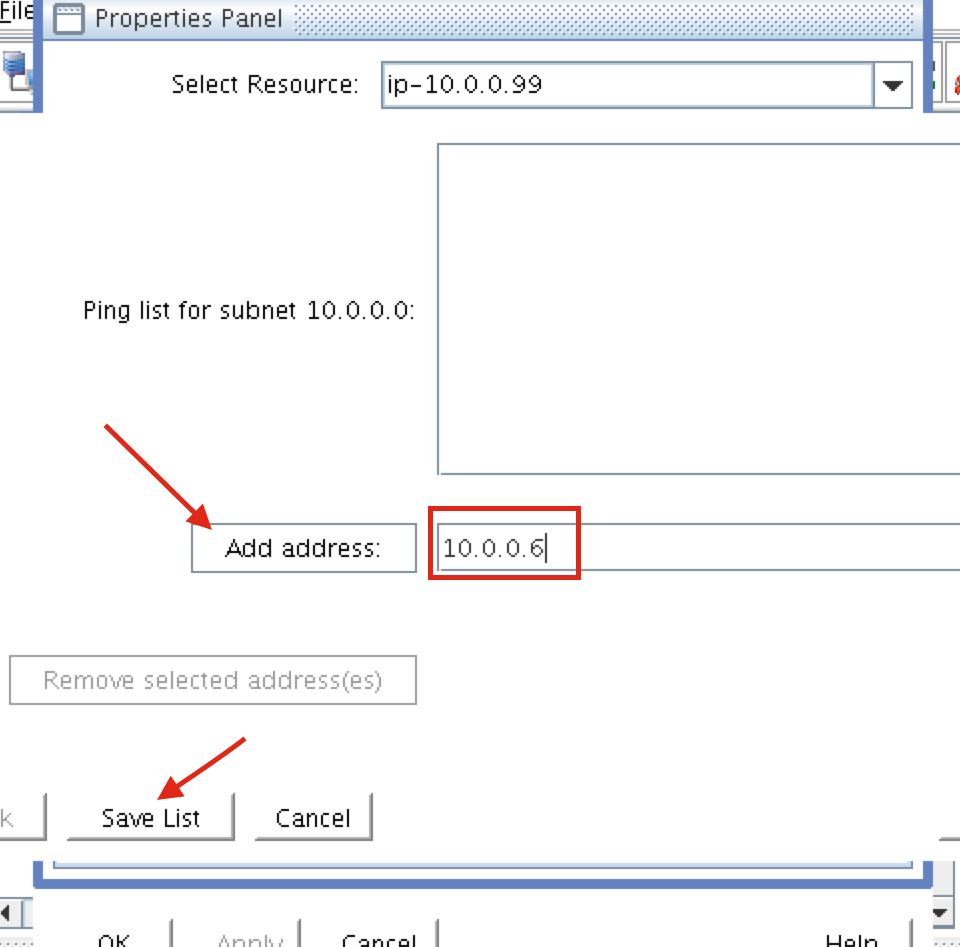
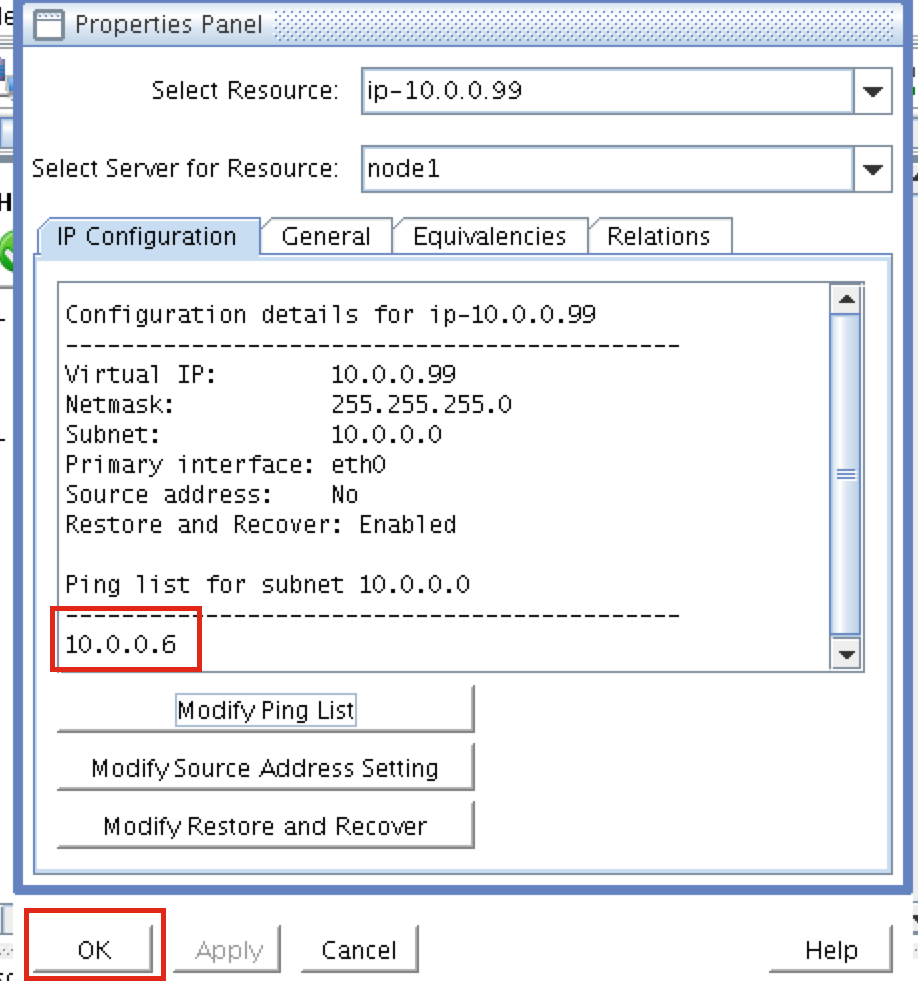
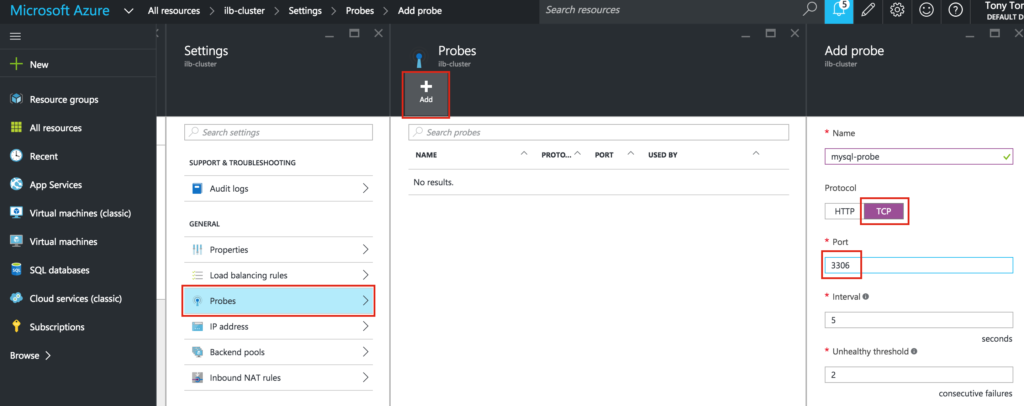
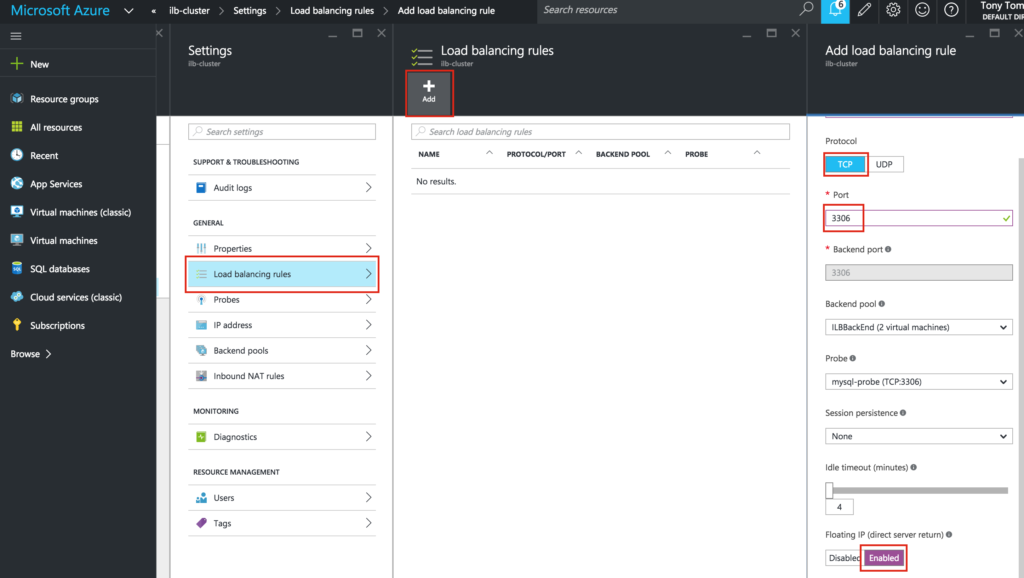
When high availability is of paramount importance, comprehensive fault detection is essential to avoiding application-level downtime. This objective is readily achieved with purpose-built failover clustering technology, such as SIOS DataKeeper and SIOS Protection Suite from SIOS Technology, which is capable of automatically detecting a broad range of causes of downtime in both the software and the underlying physical and virtual resources. These software-only clusters are layered atop the cloud to provide a complete HA/DR solution that includes data replication, continuous application-level monitoring and configurable failover/failback recovery policies.
DRaaS Offerings
Failover clustering software can be configured for HA or DR alone, or for a combination of HA and DR. DR normally has a standby VM in another region in a configuration referred to as a GeoCluster. As with DRaaS offerings, WAN bandwidth limitations cause some “replication lag” for the data, and potentially some data loss under certain failure scenarios. But unlike with DRaaS, broad classes of failure are detected automatically at the cloud platform and application levels, and can be remedied immediately to assure service continuity.
While failover clustering, with its ability to minimize both recovery point and recovery time objectives (RPO/RTO), affords comprehensive service protection compared to DRaaS, the need to fully configure costly redundant and idle resources remains. Fortunately, this issue is being addressed by emerging cluster management techniques that can orchestrate a full recovery through the dynamic allocation of resources at the time of failure.
A New Approach
The standby VM, while operating in standby mode, is configured only with the resources needed to handle its minimalist role of a data replication target for the primary VM. When a failure occurs, the cluster immediately and dynamically reconfigures the standby VM with the complete complement of resources needed to deliver the level of performance required for its fully operational role of the primary VM. This dynamic utilization enables HA and DR protections to benefit from significant cost savings without sacrificing the availability and reliability benefits of clustering.
Conclusion
Both HA failover clusters and DRaaS, whether operating separately or in concert, can have roles to play in making the continuum of HA and DR protections more affordable for the full spectrum of enterprise applications-from those that can tolerate some data loss and extended periods of downtime, to those that require an RPO of zero (no data loss) and an RTO of less than five minutes under all possible failure scenarios.
About the Author

Jerry Melnick is President and CEO at SIOS Technology, where he is responsible for directing the overall corporate strategy and leading the company’s ongoing growth and expansion. He has more than 25 years of experience in the enterprise and high availability software markets. Before joining SIOS, he was CTO at Marathon Technologies where he led business and product strategy for the company’s fault tolerant solutions. His experience also includes executive positions at PPGx, Inc. and Belmont Research, where he was responsible for building a leading-edge software product and consulting business focused on supplying data warehouse and analytical tools. Jerry began his career at Digital Equipment Corporation where he led an entrepreneurial business unit that delivered highly scalable, mission critical database platforms to support enterprise-computing environments in the medical, financial and telecommunication markets. He holds a Bachelor of Science degree from Beloit College with graduate work in Computer Engineering and Computer Science at Boston University.




{kind=link}