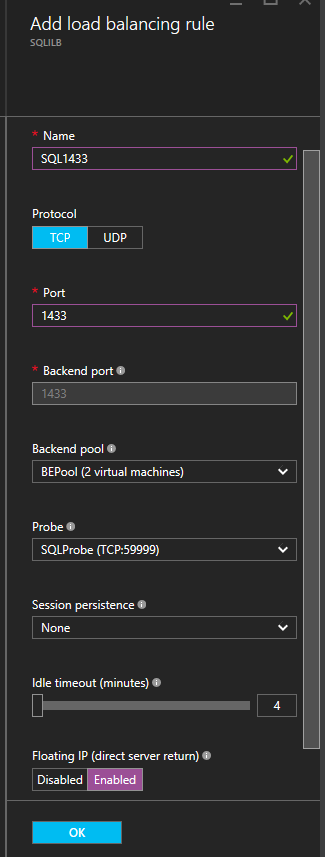
SQL Server 2016 Support For Distributed Transactions With AlwaysOn Availability Groups
SQL Server 2016 Support For Distributed Transactions with Always On Availability Groups sounds extremely promising. They did make some improvements in that regard, but it is not yet fully supported.

SQL Server 2016 Support For Distributed Transactions are only supported if the transaction is distributed across multiple instances of SQL Server. It is NOT supported if the transaction is distributed between different databases within the same instance of SQL Server. So in the picture above, if the databases are on separate SQL instances it will work. But not if the databases reside on the same instance which is more likely.
If you require distributed transaction support between different databases within the same SQL Server instance and you want high availability, you still must use a traditional SQL Server Always On Failover Cluster or a SANLess Cluster using DataKeeper.
Reproduced with permission from Clusteringformeremortals.com