Glossary of Terms: Windows Server Failover Clustering
(WSFC)
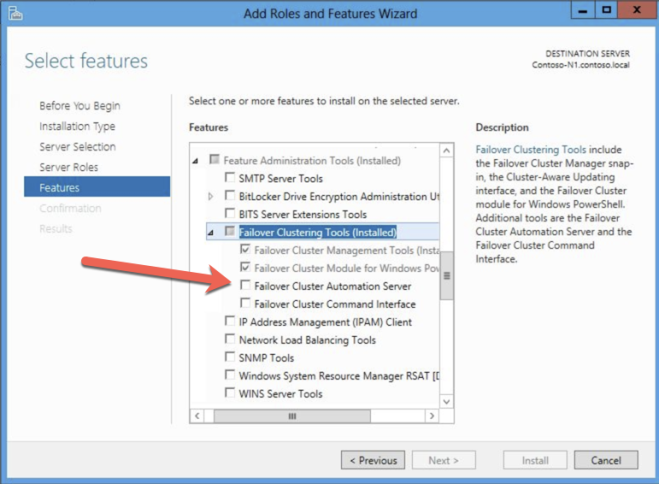
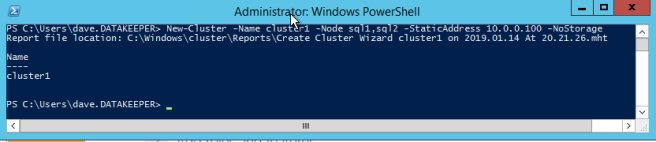
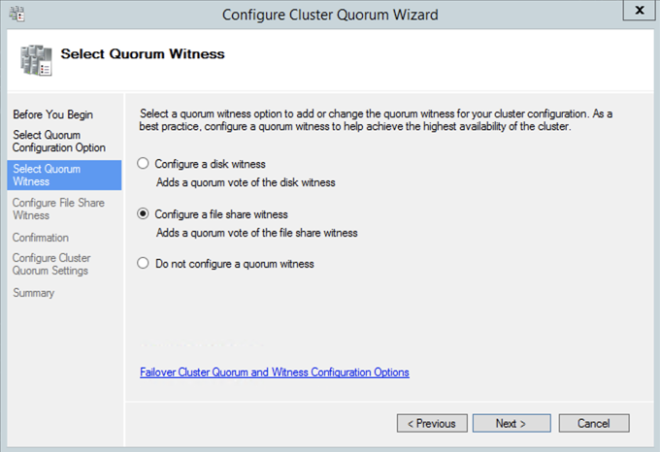
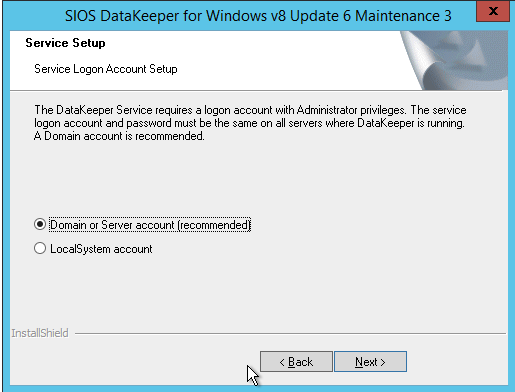
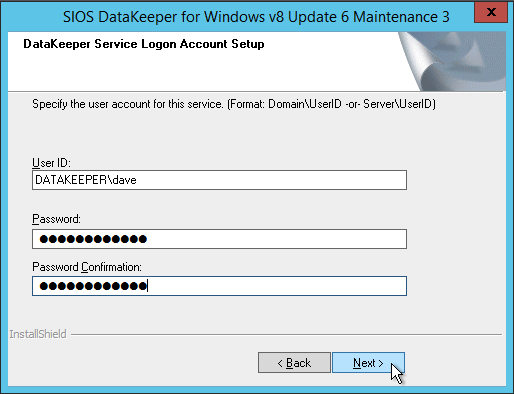
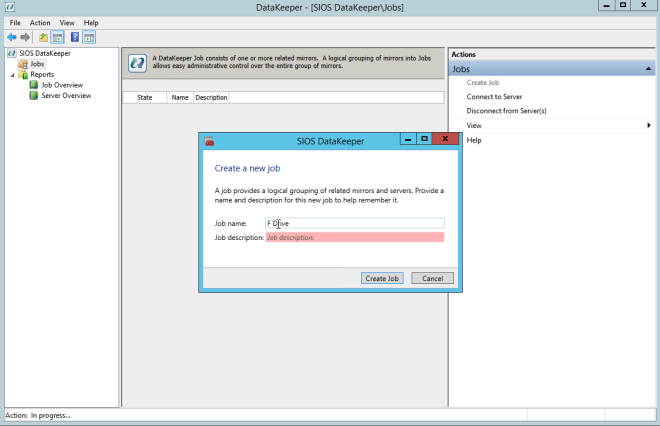
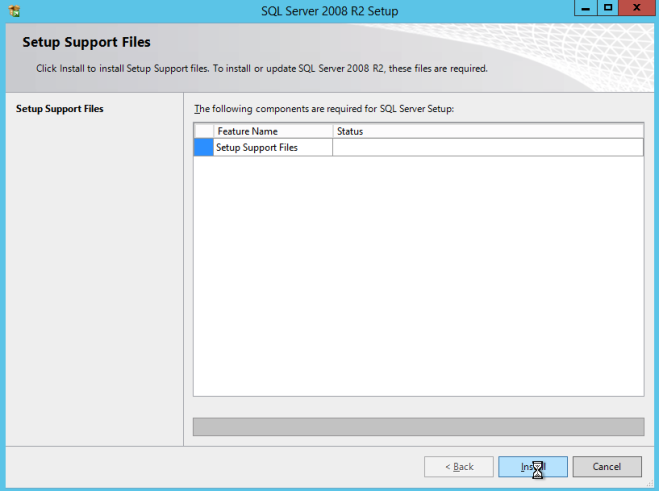
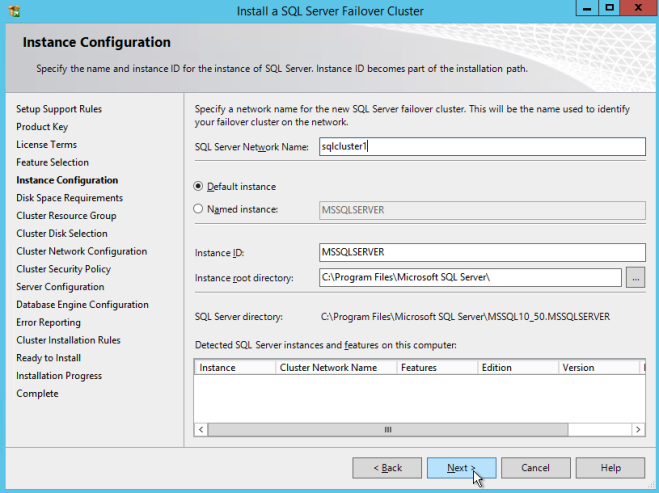
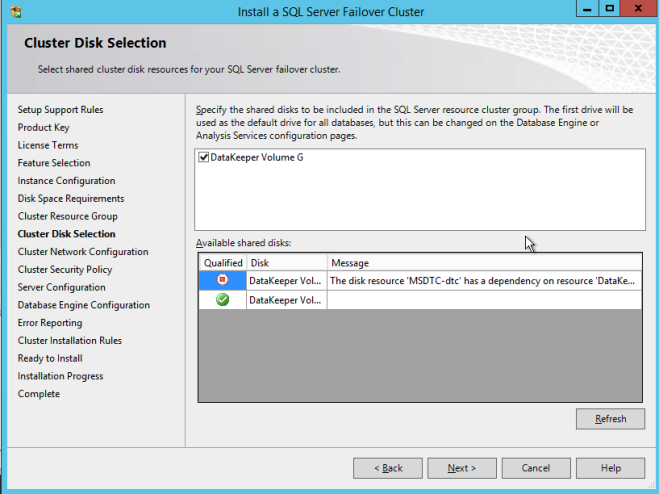
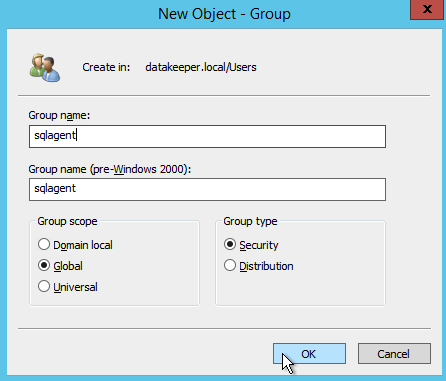
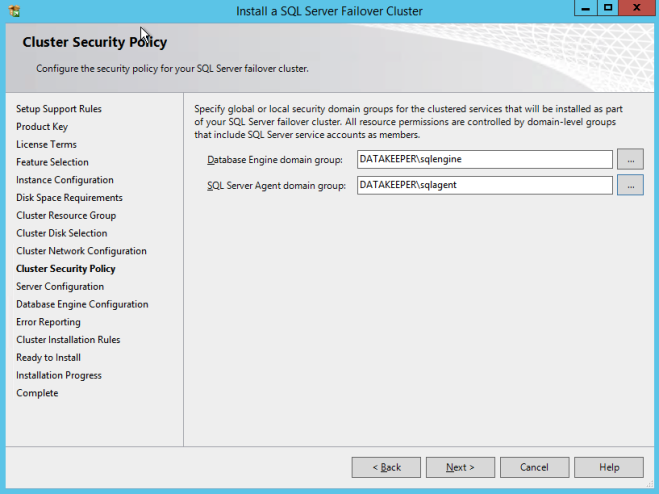
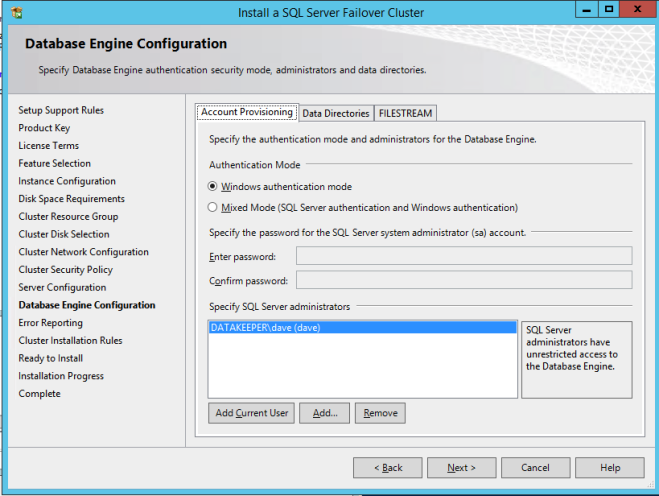
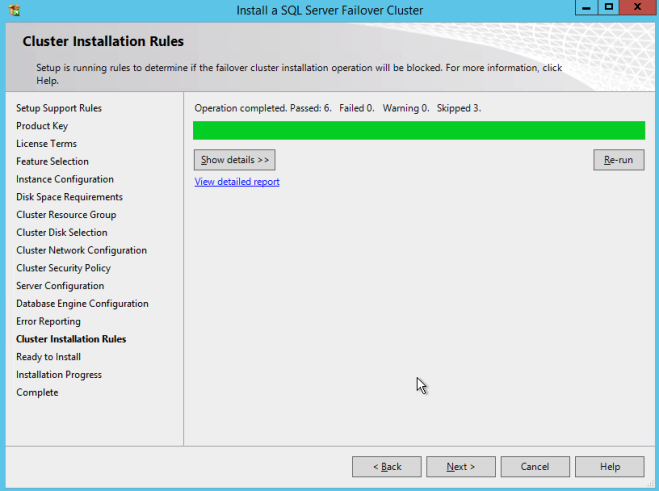
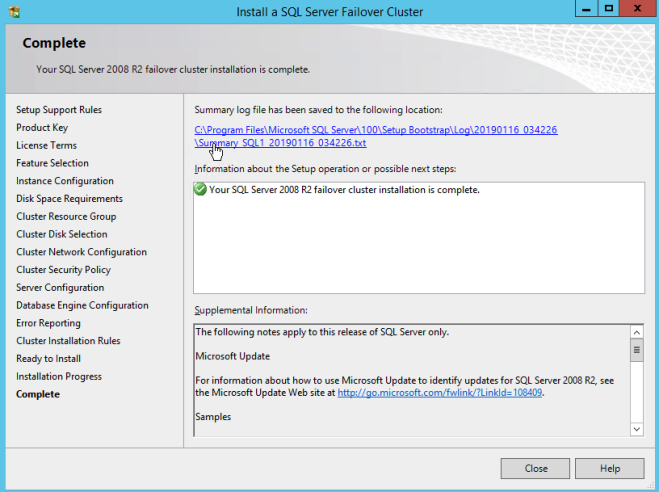
Definition: A Windows Server Failover Clustering (WSFC) cluster is a group of independent servers that work together to increase the availability of applications and services. SQL Server 2017 takes advantage of WSFC services and capabilities to support Always On availability groups and SQL Server Failover Cluster Instances. SIOS DataKeeper is integrated with WSFC adding the configuration flexibility to build WSFC clusters in the cloud.
Reproduced from SIOS