What Is The Network Speed Between Azure Regions Connected With Virtual Network Peering?
This is the question I asked myself today. Of course I couldn’t find the reason behind Network Speed Between Azure Regions Connected With Virtual Network Peering documented anywhere. I’m assuming there is no guarantee. It probably depends on current utilization, etc. If I’m wrong, someone please point me to the documentation that states the available speed. I primarily looked here and here.
So I set up two Windows 2016 D4s v3 instances – one in Central US and one in East US 2. Both are paired regions.
If you don’t know what peering is, it essentially lets you to easily connect two different Azure virtual networks. Peering is very easy to setup. Just make sure you configure it from both Virtual Networks. Once it is configured properly it will look something like this.
Doing Tests

I then downloaded iPerf3 on each of the servers and began my testing. At first I had some pretty disappointing results.
But then upon doing some research, I found that running multiple threads and increasing the window size reports a more accurate measurement of the available bandwidth. I tried a few different setting. It seemed to max at at just about 1.9 Gbps on average, much better than 45 Mbps!
I used the client parameters and produced the best results. See as follows:
iperf3.exe -c 10.0.3.4 -w32M -P 4 -t 30
A sample of that output looks something like this.
- - - - - - - - - - - - - - - - - - - - - - - - - [ 4] 2.00-3.00 sec 34.1 MBytes 286 Mbits/sec [ 6] 2.00-3.00 sec 39.2 MBytes 329 Mbits/sec [ 8] 2.00-3.00 sec 56.1 MBytes 471 Mbits/sec [ 10] 2.00-3.00 sec 73.2 MBytes 615 Mbits/sec [SUM] 2.00-3.00 sec 203 MBytes 1.70 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ 4] 3.00-4.00 sec 37.5 MBytes 315 Mbits/sec [ 6] 3.00-4.00 sec 19.9 MBytes 167 Mbits/sec [ 8] 3.00-4.00 sec 97.0 MBytes 814 Mbits/sec [ 10] 3.00-4.00 sec 96.8 MBytes 812 Mbits/sec [SUM] 3.00-4.00 sec 251 MBytes 2.11 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ 4] 4.00-5.00 sec 34.6 MBytes 290 Mbits/sec [ 6] 4.00-5.00 sec 24.6 MBytes 207 Mbits/sec [ 8] 4.00-5.00 sec 70.1 MBytes 588 Mbits/sec [ 10] 4.00-5.00 sec 97.8 MBytes 820 Mbits/sec [SUM] 4.00-5.00 sec 227 MBytes 1.91 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ 4] 5.00-6.00 sec 34.5 MBytes 289 Mbits/sec [ 6] 5.00-6.00 sec 31.9 MBytes 267 Mbits/sec [ 8] 5.00-6.00 sec 73.9 MBytes 620 Mbits/sec [ 10] 5.00-6.00 sec 86.4 MBytes 724 Mbits/sec [SUM] 5.00-6.00 sec 227 MBytes 1.90 Gbits/sec - - - - - - - - - - - - - - - - - - - - - - - - - [ 4] 6.00-7.00 sec 35.4 MBytes 297 Mbits/sec [ 6] 6.00-7.00 sec 32.1 MBytes 269 Mbits/sec [ 8] 6.00-7.00 sec 80.9 MBytes 678 Mbits/sec [ 10] 6.00-7.00 sec 78.5 MBytes 658 Mbits/sec [SUM] 6.00-7.00 sec 227 MBytes 1.90 Gbits/sec
I saw spikes as high as 2.5 Gbps and lows as low as 1.3 Gbps.
Update From Twitter
So I received some feedback from @jvallery that I must try out.

First thing I did was bump up my existing instances to D64sv3 and used -P 64. I saw a significant increase
iperf3.exe -c 10.0.3.4 -w32M -P 64 -t 30 [SUM] 0.00-1.00 sec 2.55 GBytes 21.8 Gbits/sec
I then spun up some F72v2 instances as suggested and I saw even better results.
iperf3.exe -c 10.0.2.5 -w32M -P 72 -t 30 [SUM] 0.00-1.00 sec 2.86 GBytes 24.5 Gbits/sec
I’m not well versed enough in Linux. Bu there seems to be a reasonable amount of bandwidth available between Azure regions when using peered networks.
If someone wanted to repeat this test using Linux as @jvallery suggested, I’ll be glad to post your results here! Seems that there is indeed to possible to vary the Network Speed Between Azure Regions Connected With Virtual Network Peering.
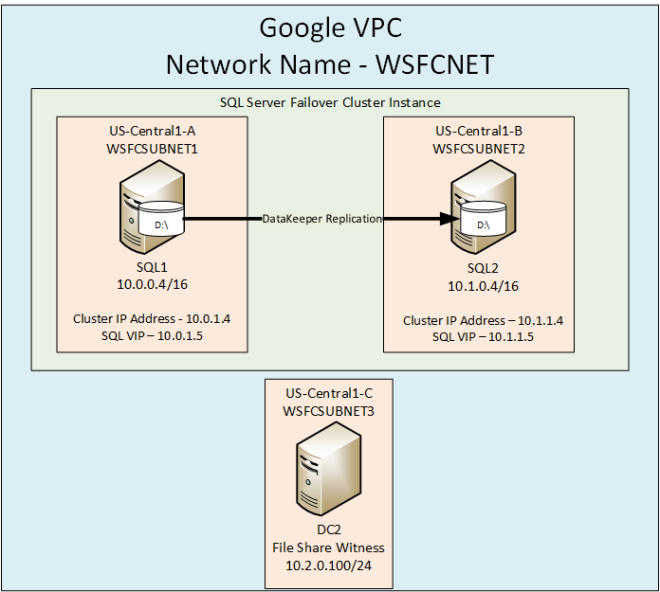
Using SIOS DataKeeper For Disaster Recovery
For one of my clients, I chose to use these two peered networks to address SQL Server disaster recovery using SIOS DataKeeper to asynchronously replicate SQL data between regions for disaster recovery.

In this particular scenario, we were measuring a RPO measured in milliseconds. As you’ll see in the video below, during a DISKSPD test meant to simulate a typical SQL Server workload the RPO was <1 second.
I’d love to hear from you regarding your experience regarding any network speed you measure in Azure and how you are using peered networks in Azure.
Have questions about Network Speed Between Azure Regions Connected With Virtual Network Peering? Read through our blog or contact us!
Reproduced with permission from ClusteringForMereMortals.com