Webinar: Why Clustering for SQL Server High Availability?
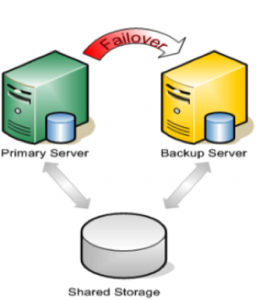
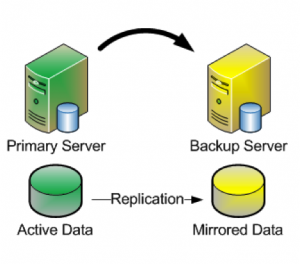
When it comes to SQL Server high availability (HA), SQL Server Failover Cluster Instance (FCI) has been the standard since 1998 with the release of SQL Server 7. Dave Bermingham, Microsoft Cloud and Datacenter MVP and former Cluster MVP, reviews what clusters are, why you should use them for high availability, discusses SQL Server Failover Cluster Instance concepts and why it is an important part of your Mission Critical SQL Server deployment whether you run on-premises, in the cloud or in a hybrid cloud configuration.
Register Webinar: Why Clustering for SQL Server High Availability?