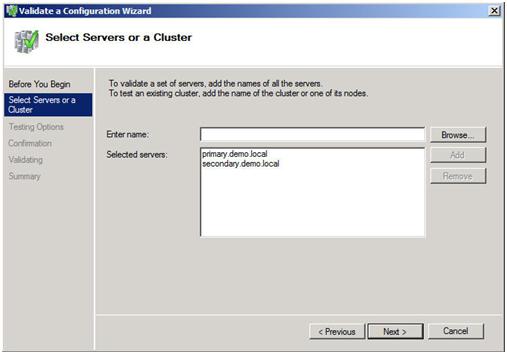
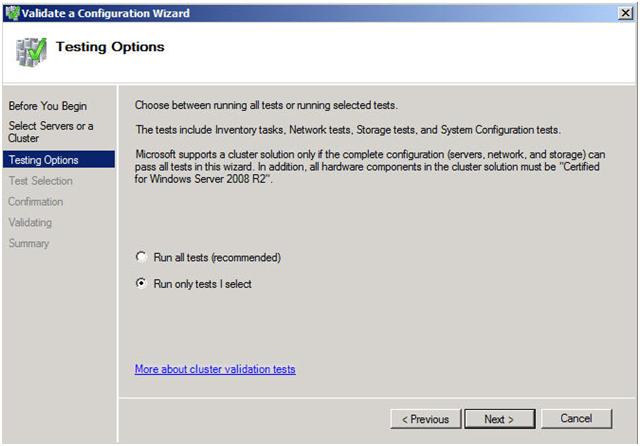
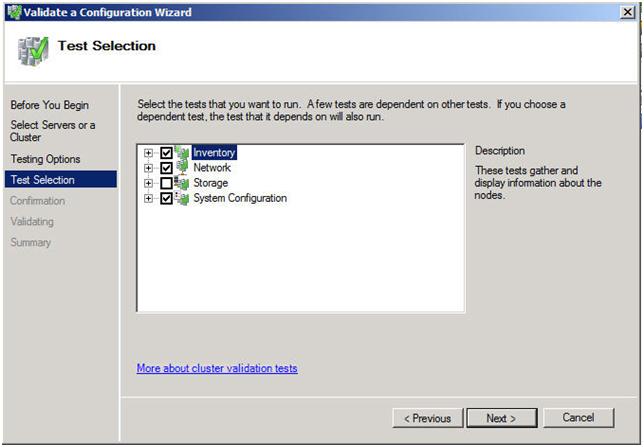
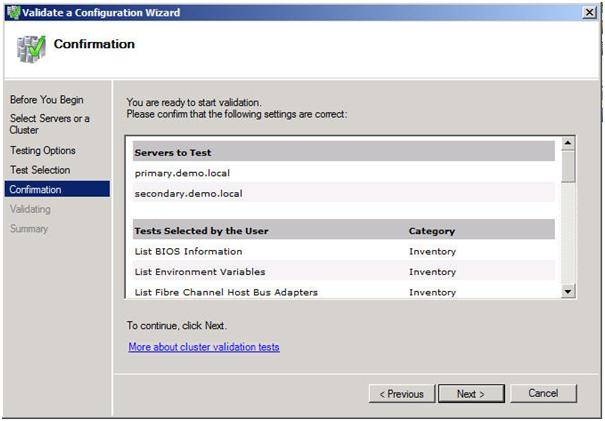
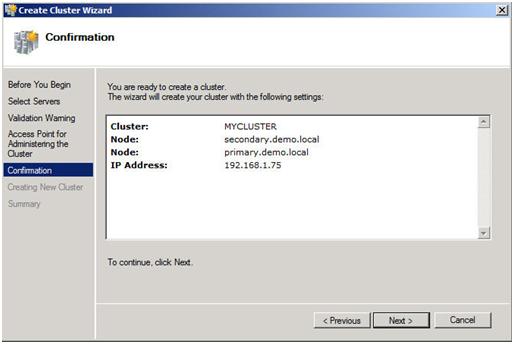
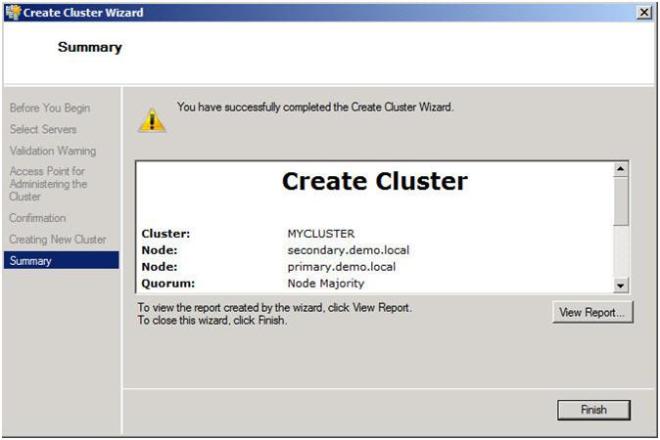
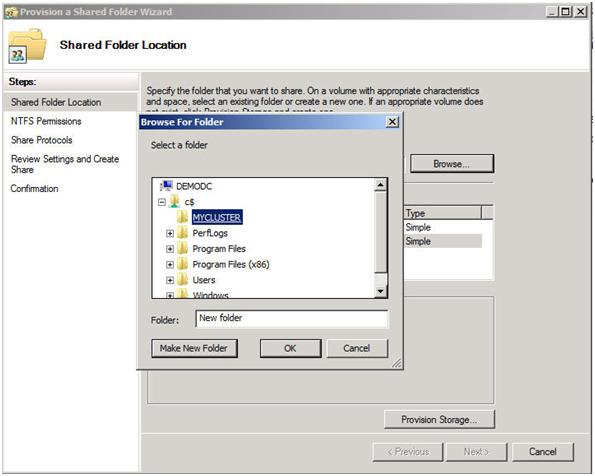
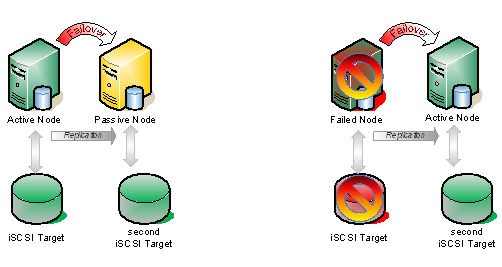
Look for a Step-by-Step article on how to configure a DHCP across data centers and/or without shared storage in the very near future using Windows Server Failover Clustering and SteelEye DataKeeper Cluster Edition. In the meantime, check out this video that demonstrates a DHCP cluster that uses a replicated DHCP database instead of a shared disk in the cluster.
Reproduced with permission from https://clusteringformeremortals.com/2009/11/23/dhcp-cluster-without-shared-storage-andor-across-data-centers/




{kind=link}